使用经验分享
线上故障排查思路:
1、紧急处理,优先保障服务可用(如切换vip,主备容灾)
2、保留第一现场,通过jstack -l {pid} > jvmtmp.txt ,打印栈信息 (后续可以在gceasy官网上传报文进行分析)
3、通过arthas工具进行线上故障问题。执行命令如下
dashboard,优先通过看板,找到问题线程id
thread {id},查看问题线程的栈信息
watch {class} {method} {ognl表达式},观察问题方法的上下文
前言
arthas是阿里的一款线上故障分析工具,对jvm当前的上线文可以进行实时监控,下文会介绍我在实际过程中是如何使用arthas来定位问题的。
背景
笔者像往常一样coding,突然收到一条消息告警“服务器内存使用率>95%”。随即第一时间访问部署在该服务器的系统,系统能够响应请求,但是响应时间变得非常慢(原本毫秒级可以响应的请求,变成秒级响应)。通过看板可以得到,服务器的负载上升(最近5m)
这已经开始影响到用户的正常使用了。确认仅是web服务受到影响,其他存储服务正常的情况下,我开始联系运维将服务切换到备机(应急方案)。系统这才恢复正常。
故障分析
当人运气还是背时,躺着也要背锅。我倒要看看,究竟是谁在搞鬼。
献祭出法宝Arthas~,命令行噼里啪啦一顿敲
dashboard
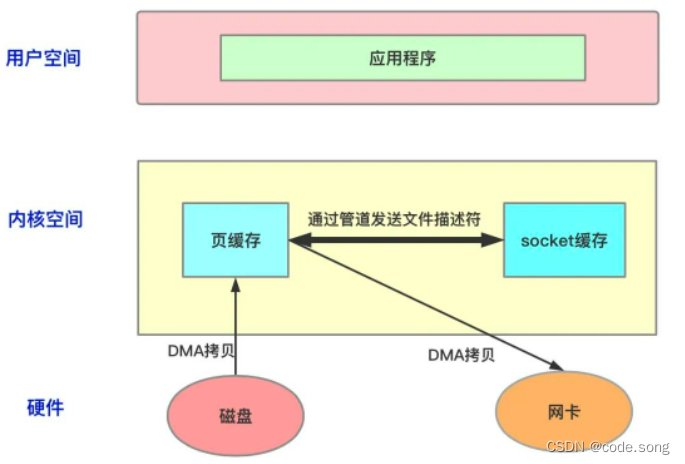
通过看板形式,分析当前jvm整体状态
[arthas@22683]$ dashboard
(图一)

(图二)
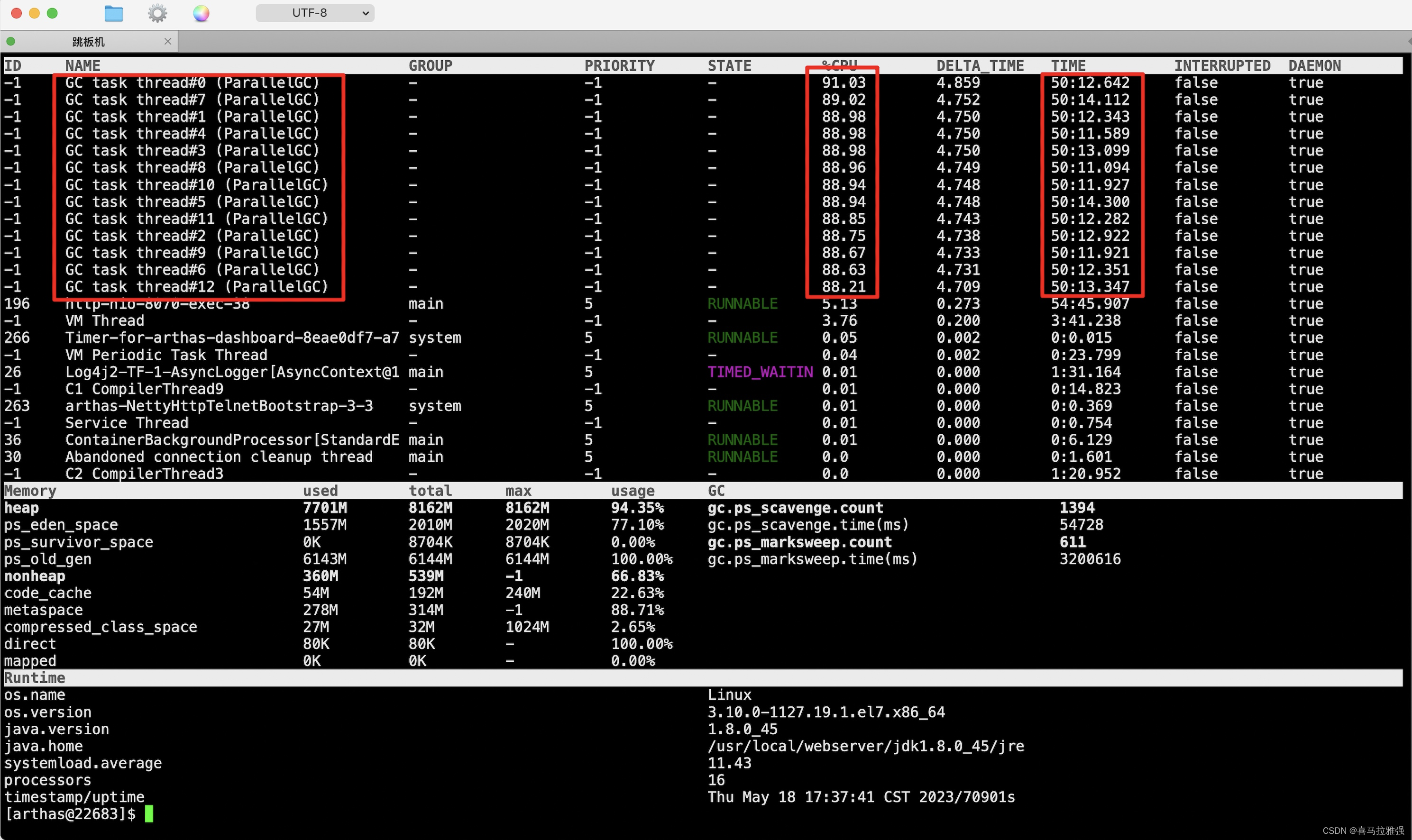
通过图片可以看出,线程http-nio-8070-exec-38执行耗时54分钟,并且伴随着大量的GC线程。初步判断线程可能存在深度递归或者死循环,产生了大量内存,JVM疲于GC,GC期间系统会发生STW(Stop The World),且占用了大量CPU资源,因此导致其他服务线程无法正常工作。
为了验证猜想,我们利用火焰图进行分析
profiler
profiler(火焰图)记录的是一段时间内,方法的执行次数与频率,并以报表的方式进行展示
# 火焰图开启后,arthas需要时间采集样本,这里我们等待5分钟
[arthas@22683]$ profiler start
# 关闭火焰图,停止采集。arthas会生成火焰图文件,拷贝到本地打开瞅瞅
[arthas@22683]$ profiler stop
(火焰图)

可以看到,GC占有率达到98.93%,jvm大部分时间都用来回收内存,现在是没有空闲去处理服务请求的。
得出结论:频繁GC是系统卡顿的直接原因.
thread
知道问题线程后,我们可以利用thread分析下线程状态
# 196为问题线程ID
[arthas@22683]$ thread 196
"http-nio-8070-exec-38" Id=196 RUNNABLE
at org.apache.commons.collections4.iterators.UnmodifiableIterator.next(UnmodifiableIterator.java:76)
at com.epoch.bdp.bill.util.BillDataUtils.getSubAreaData(BillDataUtils.java:993)
at com.epoch.bdp.bill.util.BillDataUtils.getSubAreaData(BillDataUtils.java:1005)
at com.epoch.bdp.bill.util.BillDataUtils.getAreaData(BillDataUtils.java:948)
at com.epoch.bdp.bill.util.BillDataUtils.getRowById(BillDataUtils.java:4714)
at com.epoch.ifp.expenseclaim.service.billvaluechange.AmortizeAmountChangeService.doProcess(AmortizeAmountChangeService.java:49)
at com.epoch.ifp.expenseclaim.service.listener.BillValueChangeButterflyEffectListener.onApplicationEvent(BillValueChangeButterflyEffectListener.java:87)
at com.epoch.ifp.expenseclaim.service.listener.BillValueChangeButterflyEffectListener.onApplicationEvent(BillValueChangeButterflyEffectListener.java:34)
at org.springframework.context.event.SimpleApplicationEventMulticaster.doInvokeListener(SimpleApplicationEventMulticaster.java:172)
at org.springframework.context.event.SimpleApplicationEventMulticaster.invokeListener(SimpleApplicationEventMulticaster.java:165)
at org.springframework.context.event.SimpleApplicationEventMulticaster.multicastEvent(SimpleApplicationEventMulticaster.java:139)
at org.springframework.context.support.AbstractApplicationContext.publishEvent(AbstractApplicationContext.java:402)
at org.springframework.context.support.AbstractApplicationContext.publishEvent(AbstractApplicationContext.java:359)
at com.epoch.infrastructure.util.service.ApplicationContextAwareUtils.publishEvent(ApplicationContextAwareUtils.java:181)
at com.epoch.bdp.bill.model.vo.billdata.BillRowData.setDataAfter(BillRowData.java:196)
at com.epoch.bdp.bill.model.vo.billdata.BillRowData.setData(BillRowData.java:495)
at com.epoch.bdp.bill.model.vo.billdata.BillRowData.setData(BillRowData.java:400)
从上往下追溯业务代码,排除工具类Utils,最终我们得到可能是以业务代码的AmortizeAmountChangeService.doProcess
monitor
为了验证我们得到的业务代码(AmortizeAmountChangeService.doProcess)是否是问题发生处,我们可以利用monitor进行监控,每5秒打印该方法的调用频率:
monitor -c 5 com.epoch.ifp.expenseclaim.service.billvaluechange.AmortizeAmountChangeService doProcess

平均处理时间0.02秒,属于正常响应。但是5秒内该方法处理时间高达700~800次,明显不太正常,由此可以推断该方法存在大量调用,验证了上述“线程可能存在深度递归或者死循环”的问题
watch
通过代码分析,AmortizeAmountChangeService.doProcess用于监听资金变更时修改。因此我们利用watch方法,尝试打印它的上下文,找到关键单据编码
watch com.epoch.ifp.expenseclaim.service.billvaluechange.AmortizeAmountChangeService doProcess "params[0].getBillDataVO()" -x 2 | grep billCode
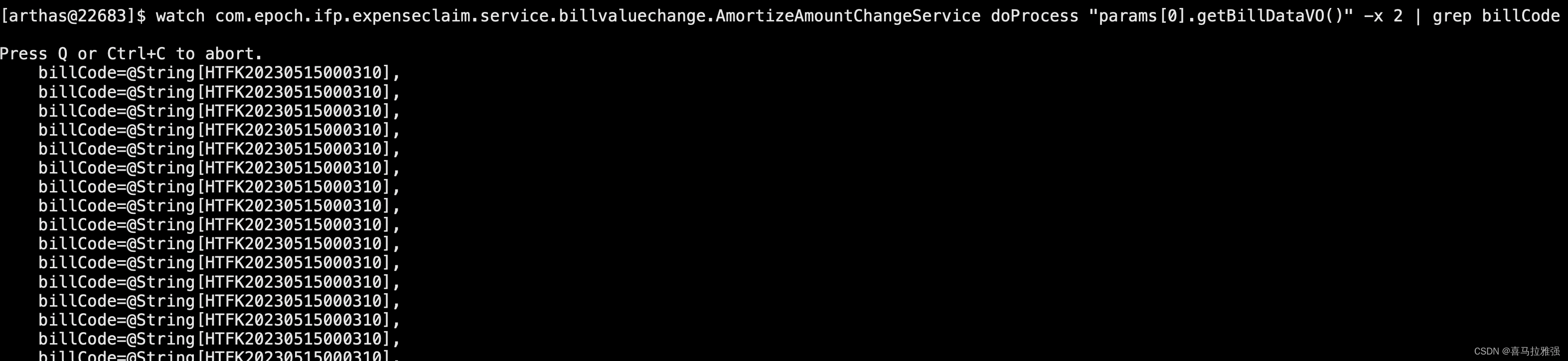
得到单据号HTFK20230515000310,拿着这个单据号去业务系统查询,分析系统的操作痕迹
结论
最终,我们定位到了故障起因。用户在上传大批量发票的时候,会触发金额修改接口,该接口在大量并发请求时会占用过量系统资源。当系统资源不够使用时发生频繁GC,最终消耗大量CPU资源,系统卡顿。