目录
一、分组算法如何计算
二、什么影响算法的安全性
三、密钥的使用次数限制
一、分组算法如何计算
分组算法包括3个部分:数据分组,分组运算和链接模式。
数据分组:将数据分割成加密函数能够处理的数据块,如果不能整分,就要补齐。分组数据的运算结构组合起来,就是密文数据。
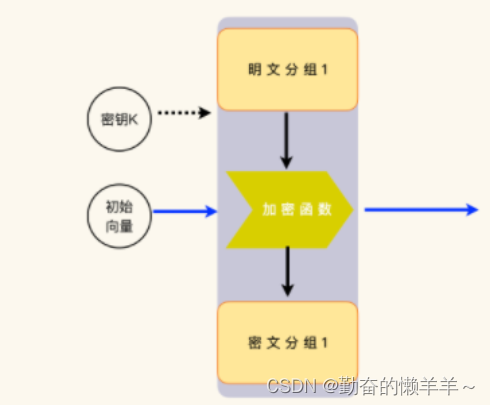
分组运算,是指通过加密函数将明文数据进行运算得到密文分组数据,再通过链接模式将 是一个分组运算和下一个分组运算联系起来。
第一个分组运算并没有是一个分组运算可以用,因此,就需要一个初始化的数据来承担这个角色,我们将这个初始化的数据称作初始化向量。

二、什么影响算法的安全性
加密函数
密钥
初始化向量
链接模式
数据补齐方案
初始化向量对算法安全性的影响
第一个数据块的计算,它的输入信息包括密钥,初始化向量,第一个明文数据分组。
如果密钥相同,第一个明文数据分组相同,初始化向量也相同,就会存在相同的输出。
因此,在一个对称密钥的生命周期里,初始化向量不能重复。
一个单纯的加密算法的实现,一般密钥办法记住一个初始化向量有没有用过,需要开发者自己想办法,常见的办法有两种:
★使用安全强度足够的随机数作为初始化向量。
★使用序列数,下一次使用初始化向量的数值,比上一次的数字自动加一或减一。
第一种,随机数的获取,有时候不是一个有效率的运算。如果随机数发生器选择不当,还会
造成加密运算的阻塞,进一步降低加密运算的效率。另外,由于解密需要相同的初始向量,
如何在加密端和解密端同步初始化向量,也是一个需要考虑的问题。
一个常见的解决办法,就是把初始化向量和加密数据一起发送给对方。
第二种,使用序列数,需要保持序列数的状态,还需要加密运算的同步。不过,序列数
状态的保持和同步,除了效率之外,还会衍生出其他的待解决的问题,比如分布式计算环境
下的序列数同步问题,比如攻击者会知道每一个初始化向量的问题。
如果你能够看到的问题无法解决,可以考虑使用随机数作为初始化向量。
一般的密钥算法库都不会提供缺省的、自动的初始化向量。应用程序需要根据使用场景来制定适当的初始化向量选择方案。
三、密钥的使用次数限制
一个128位的初始化向量,最多有2^128个不重复的数值。进一步的说,对于这
个算法,一个密钥最多只能使用2^128次。的确看起来,2^128是一个巨大的数字,一
般的应用程序也没有什么机会使用这么多次加密运算。
当然,还有其他因素限制密钥的使用次数。很多限制因素的叠加,就会使得密钥使用的限制
数远远低于初始化向量的许可数目。所以,我们心里一定要知道,密钥是有使用次数限制
的,并且要有检查密钥使用次数限制的习惯。