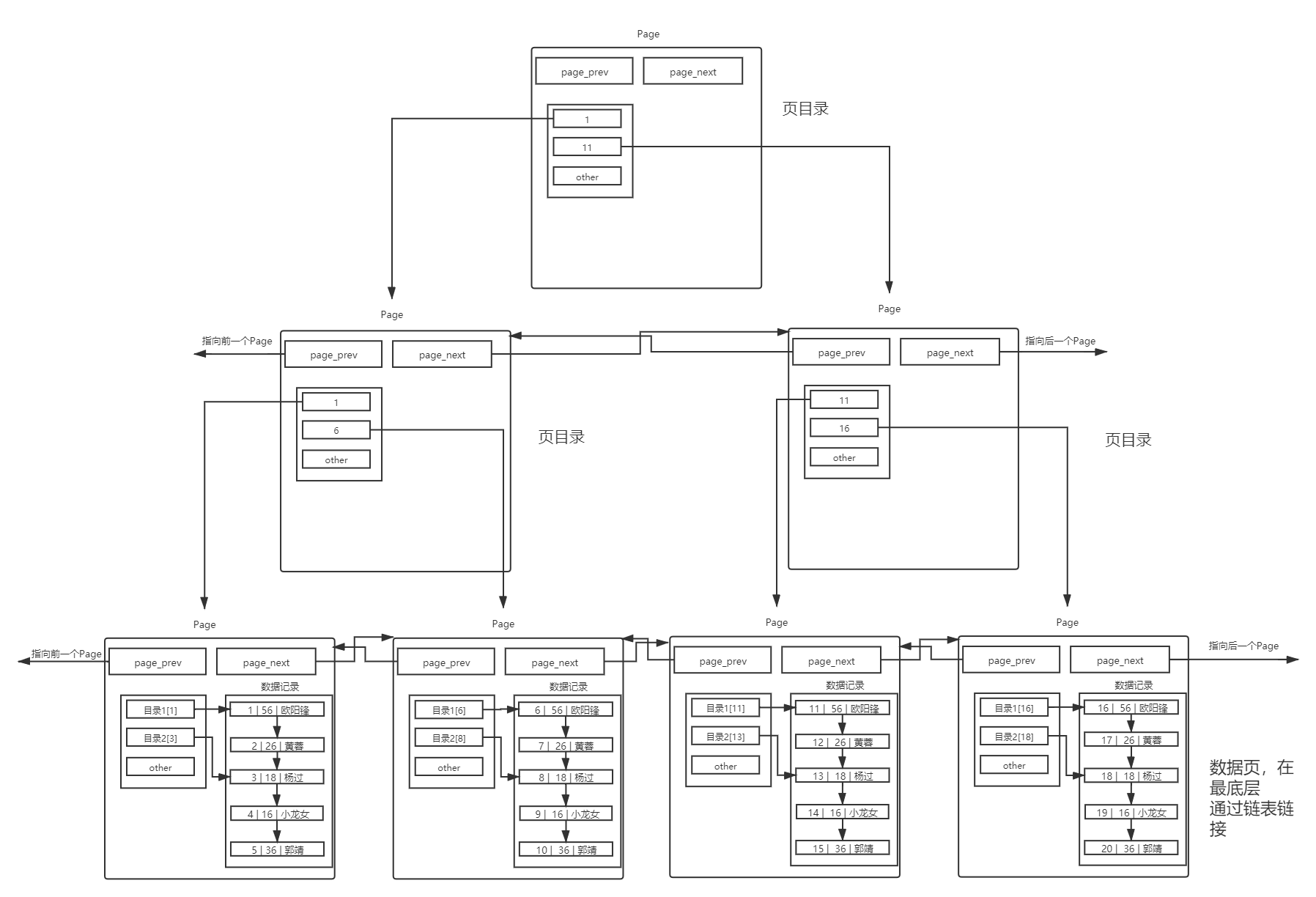
前言
硬件层面:使用固态硬盘、扩大内存、加大带宽等等
架构层面:主从复制实现读写分离【一主一 或 双主双从】
表结构层面:对表结构进行垂直拆分、水平分表、分库分表。常用的数据库中间件有:MySQL Proxy、MyCat以及ShardingSphere等等
索引层面:索引帮助MySQL高效获取数据的数据结构,优化索引的本质就是通过减少IO量和IO次数来提高查询效率
MySQL数据类型
在业务允许范围内,数据类型所占用的存储空间越少越好
数值类型
tinyint【占用1byte=8bit】:一般用于枚举数据
smallint【占用2byte=16bit】:可以用于较小范围的统计数据
mediumint 【占用3byte=24bit】:用于较大整数的计算
int|integer【占用4byte=24bit】:取值范围足够大
bigint【占用8byte=64bit】:处理巨大的整数时才会用到
浮点类型[MYSQL8.0开始不建议使用,未来会被删除]
float单精度浮点数【占用4byte=24bit】
double双精度浮点数【占用8byte=64bit】
建议使用 decimal 代替浮点型,例如:decimal(m,d)
m是数字的最大位数,范围是1-65
d是小数点后的位数,范围是0-30,并且不能大于m
如果m被省略了,m的值默认为10
如果d被省略了,d的值默认为0
字符和字符串类型
char:固定长度的字符串,最大长度255,实际存储的时候会自动删除末尾的空格
varchar:可变长度的字符串
blob:二进制方式进行存储
text:字符串方式进行存储
建议对含有大文本类型的字段进行垂直拆分,把大文本字段拆分到子表
日期类型
date【占用3byte=24bit】:
timestamp【占用4byte=32bit】:精确到秒
datetime【占用8byte=64bit】:精确到毫秒
MySQL索引的数据结构
在线演示
Hash
二叉树
平衡二叉树
红黑树
BTree 数据结构
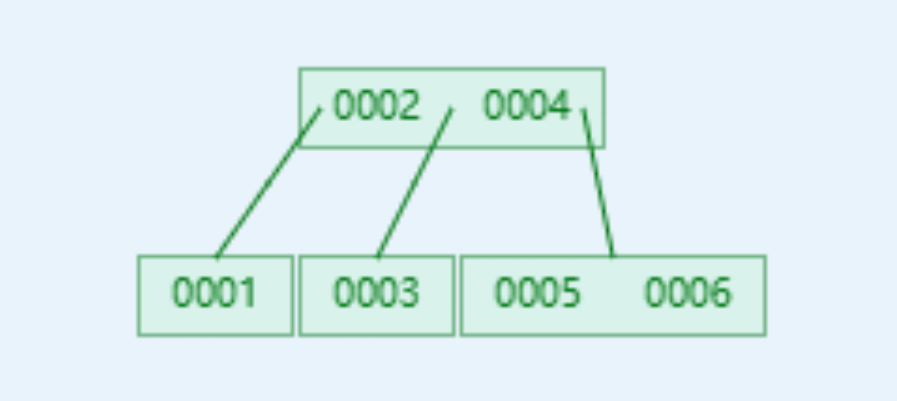
B树中每个节点最多存储(2个关键字、2个数据区、3个节点引用),一个节点如果超过2个关键字就会自动分裂
B树查找的时间复杂度为O(h * lgn),h为树高,n为每个节点存储关键字的数量
B树相对于平衡二叉树,在数据量相同的情况下,B数据的高度要低于平衡二叉树,减少了IO查询次数
B+Tree 数据结构
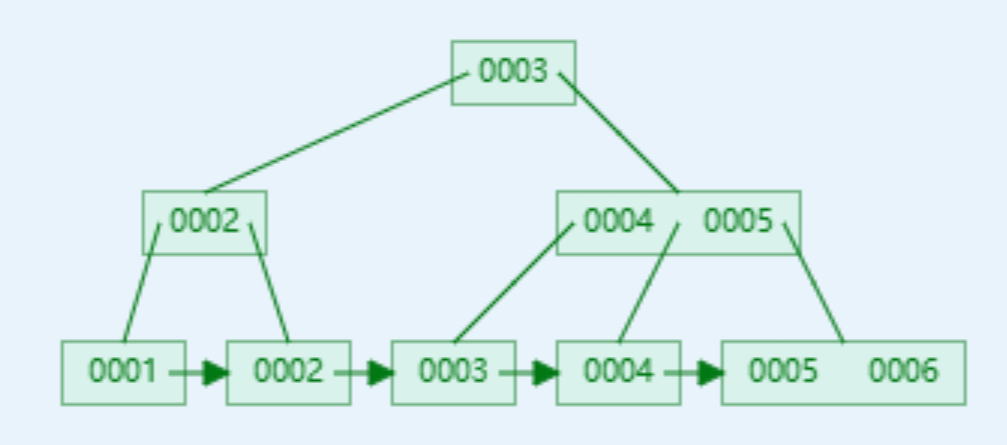
B+树中的根节点和支节点存储的是(关键字、节点引用),相比于B树,其单位节点要存储更多的关键字
B+树的叶子节点存储的是(关键字、数据区),叶子节点是顺序排列的并且相邻叶子节点具有相互引用的关系,非常适合排序
总结
B树的每个节点都存储了数据区、而B+树只有叶子节点才会存储数据区,所以B+树在检索时的IO消耗要小于B树
B+树的叶子节点都是顺序排列的并且相邻叶子节点具有相互引用的关系,所以非常适合做排序
MySQL索引
- 创建索引的原则
索引列的数据类型占用存储空间越少越好,因为索引本身也是占用磁盘空间的
索引列的数据可以为空,但是不建议为空
索引列的数据重复率不要超过80%
频繁更新的列不要创建索引
在业务允许范围内,建议使用自增长作为主键
1、普通索引
普通索引是最基本的索引,仅用于加速查询,没有任何限制:可以为空、可以重复
2、唯一索引
唯一索引与普通索引类似,但索引列的值必须唯一
3、主键索引
主键索引是一种特殊的唯一索引,一个表只能有一个主键,不允许有空值
4、组合索引(复合索引)
组合索引是多列值组成的一个索引,专门用于组合搜索,使用组合索引时遵循最左前缀原则
5、全文索引
全文索引主要用来查找文本中的关键字,而不是直接与索引中的值相比较,目前只有char、varchar,text 列上可以创建全文索引
6、空间索引
空间索引是对空间数据类型的字段建立的索引,分别是GEOMETRY、POINT、LINESTRING、POLYGON
创建空间索引的列,必须将其声明为NOT NULL,空间索引只能在存储引擎为MYISAM的表中创建
MySQL存储引擎
| 存储引擎 | MyISAM | InnoDB |
|---|---|---|
| 支持事务 | 否 | 是 |
| 支持行锁 | 否 | 是 |
| 支持外键 | 否 | 是 |
| 支持表锁 | 是 | 是 |
| 支持全文索引 | 是 | 5.6+支持 |
| 适合的操作类型 | 大量查询 | 大量的添加、删除、修改 |
| MySQL默认存储引擎为InnoDB,可以通过修改配置文件的方式来指定MyISAM |
聚簇索引 和 非聚簇索引
MySQL 默认数据引擎 InnoDB 中,数据在进行添加时必须和某一个索引列进行绑定,绑定优先级如下:
1、如果有主键,则和主键进行绑定
2、如果没有主键,则和唯一键进行绑定
3、如果没有唯一键,则根据系统生成的6字节rowid进行绑定
结论:和数据进行绑定的索引称之为聚簇索引,反之为非聚簇索引。一张表中只能有一个聚簇索引,非聚簇索引可以有多个
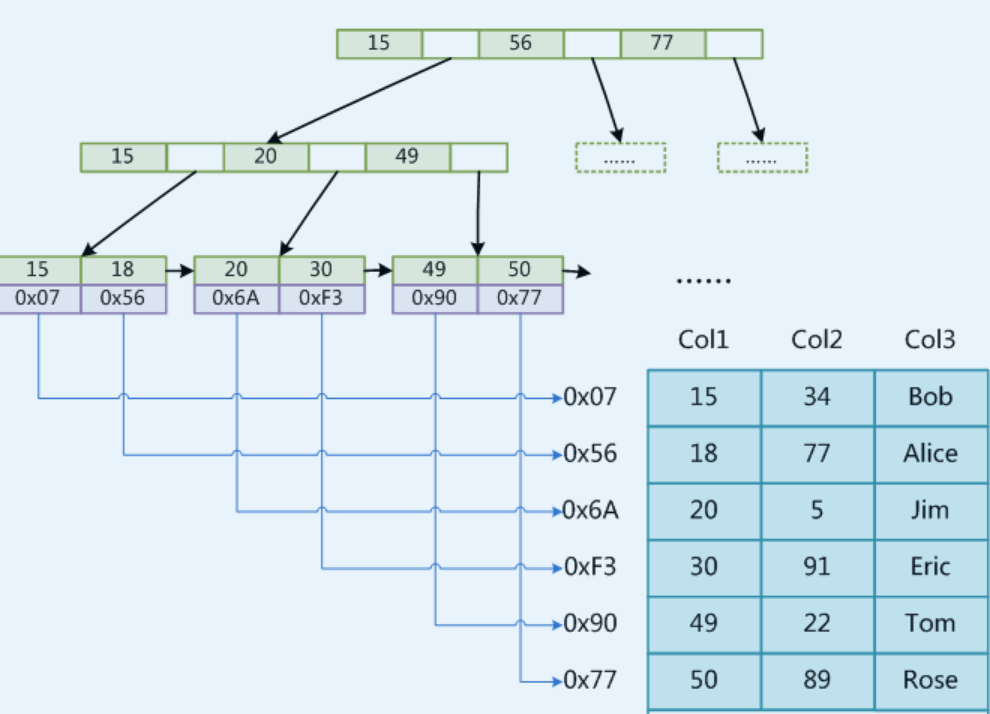
MyISAM
该数据引擎中只有非聚簇索引,非聚簇索引的key和data是分开存储的】
MyISAM引擎使用B+Tree作为索引结构,叶节点的data域存放的是数据记录的内存地址
InnoDB
该数据引擎中既有聚簇索引又有非聚簇索引
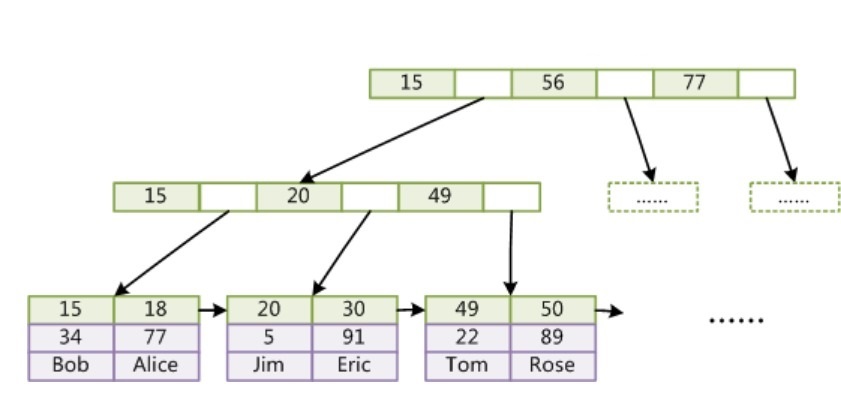
InnoDB引擎使用B+Tree作为索引结构,聚簇索引中叶子节点的data域存放的是完整的数据记录
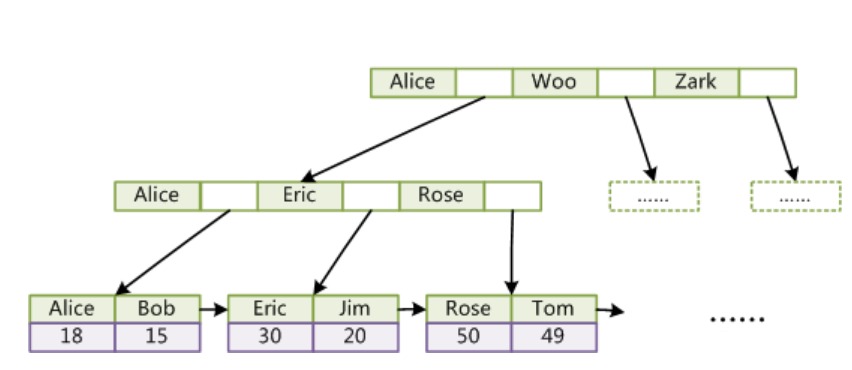
InnoDB引擎使用B+Tree作为索引结构,非聚簇索引中叶子节点的data域存放的是主键
MySQL执行计划 - explain
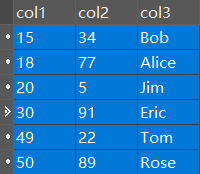
- 测试数据
CREATE TABLE `demo` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(10) COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '名称',
`phone` varchar(11) COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '用户手机号',
`age` varchar(2) COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '用户年龄',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci
CREATE TABLE `demo1` (
`col1` varchar(10) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '列一',
`col2` varchar(11) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '列二',
`col3` varchar(10) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '列三',
UNIQUE KEY `IDX_UNIQUE` (`col1`) USING BTREE,
KEY `IDX_NORMAL` (`col3`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
执行计划相关字段
-
id
表示查询中执行select子句或操作表的顺序 -
select_type【查询类型】
sample: 简单查询,不包含子查询和union
primary: 查询中包含任何复杂的子查询,则最外层的查询将被标记为Primary
union: 若第二个select出现在union之后,则被标记为union
dependent union: 与union类似,此处表示 union 或 union all 联合而成的结果会受外部表影响
union result: 从 union 表获取结果的select
subquery: 在select或where列表中包含子查询
dependent subquery: subquery的子查询要受到外部表查询的影响
derived: from子句中出现的子查询
-
table【表名称】
-
partitions
-
type【访问类型】
访问效率从高到低以此为:一般情况下,查询至少达到range级别,最好能达到ref级别
system >
const >
eq_ret >
ref >
fulltext >
ref_or_null >
index_merge >
unique_subquery >
index_subquery >
range >
index > 全所以扫描
all 全表扫描
- possible_keys
- key
- key_len
- ref
- rows
- filtered
- extra
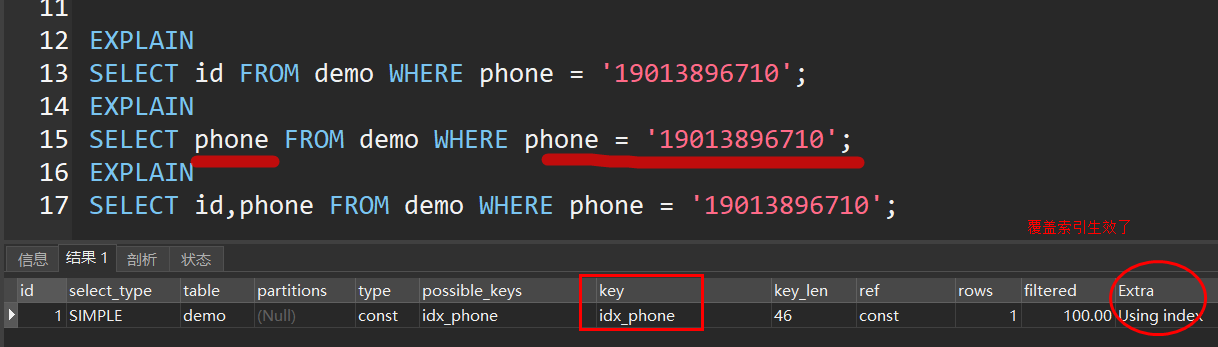
通过覆盖索引避免回表
因为非聚簇索引的叶子节点上存储的是主键ID,所以在使用非聚簇索引查询时,首先会得到一个主键ID,然后再根据主键ID去聚簇索引上查找数据,以上称之为回表查询
当查询字段(select列)和查询条件字段(where子句)全都包含在一个索引 (普通索引、唯一索引、联合索引)中,可以直接使用索引查询而不需要回表,这就是覆盖索引
普通索引 和 唯一索引
ALTER TABLE `demo` ADD UNIQUE INDEX `idx_phone` (`phone`); -- 添加索引
ALTER TABLE `demo` DROP INDEX `idx_phone`; -- 删除索引

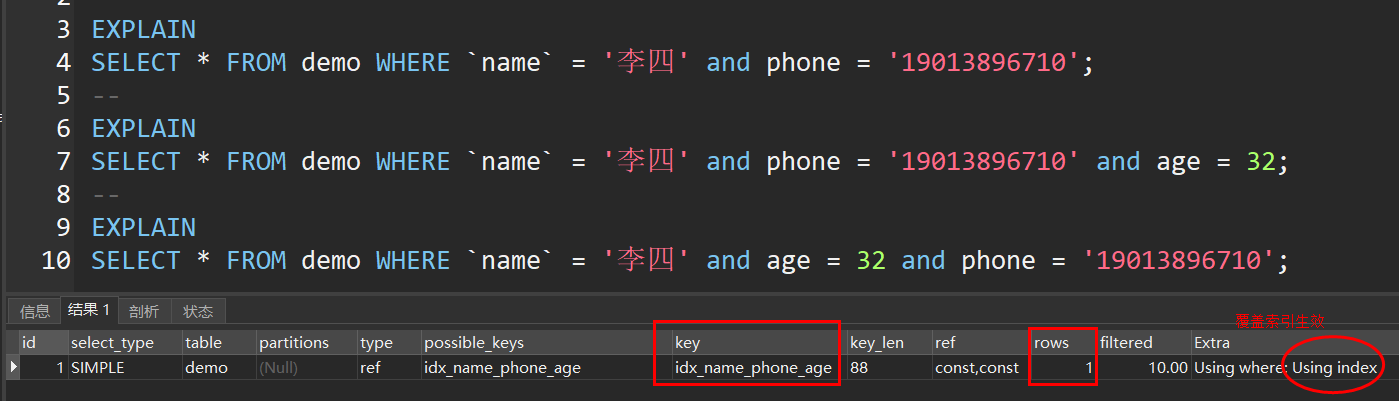
组合索引
ALTER TABLE `demo` ADD KEY `idx_name_phone_age` (`name`, `phone`, `age`); -- 添加索引
ALTER TABLE `demo` DROP INDEX `idx_name_phone_age`; -- 删除索引
EXPLAIN
SELECT * FROM demo WHERE `name` = '李四' and phone = '19013896710';
--
EXPLAIN
SELECT * FROM demo WHERE `name` = '李四' and phone = '19013896710' and age = 32;
--
EXPLAIN
SELECT * FROM demo WHERE `name` = '李四' and age = 32 and phone = '19013896710';
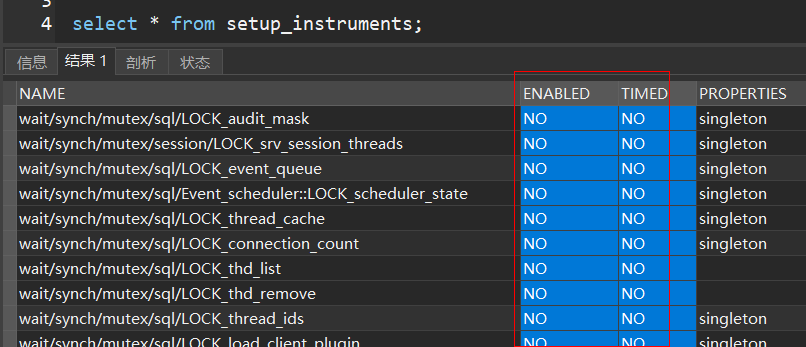
MySQL性能监控工具 - Performance Schema
Performance Schema 默认是开启的,如果需要关闭,必须通过修改 /etc/my.cnf 文件,一般不建议关闭
查看具体配置项的开启情况
select * from setup_instruments;
select * from setup_consumers;
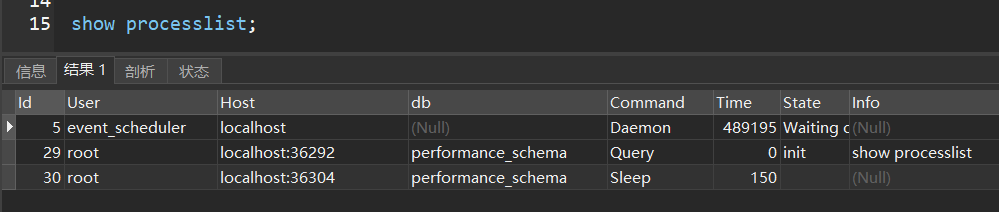
update setup_instruments set ENABLED = 'YES',TIMED = 'YES' where `NAME` like 'wait%';
update setup_consumers set ENABLED = 'YES' where `NAME` like 'wait%';
监控数据库的连接情况
show processlist;
常用统计sql
--1、哪类的 SQL 执行最多?
SELECT DIGEST_TEXT, COUNT_STAR, FIRST_SEEN,LAST_SEEN FROM events_statements_summary_by_digest ORDER BY COUNT_STAR DESC;
--2、哪类 SQL 的平均响应时间最多?
SELECT DIGEST_TEXT,AVG_TIMER_WAIT FROM events_statements_summary_by_digest ORDER BY COUNT_STAR DESC;
--3、哪类 SQL 排序记录数最多?
SELECT DIGEST_TEXT, SUM_SORT_ROWS FROM events_statements_summary_by_digest ORDER BY COUNT_STAR DESC;
--4、哪类 SQL 扫描记录数最多?
SELECT DIGEST_TEXT,SUM_ROWS_EXAMINED FROM events_statements_summary_by_digest ORDER BY COUNT_STAR DESC;
--5、哪类 SQL 使用临时表最多?
SELECT DIGEST_TEXT,SUM_CREATED_TMP_TABLES,SUM_CREATED_TMP_DISK_TABLES FROM events_statements_summary_by_digest
ORDER BY COUNT_STAR DESC;
--6、哪类 SQL 返回结果集最多?
SELECT DIGEST_TEXT,SUM_ROWS_SENT FROM events_statements_summary_by_digest ORDER BY COUNT_STAR DESC;
--7、哪个表物理 IO 最多?
SELECT file_name, event_name, SUM_NUMBER_OF_BYTES_READ,SUM_NUMBER_OF_BYTES_WRITE FROM file_summary_by_instance
ORDER BY SUM_NUMBER_OF_BYTES_READ + SUM_NUMBER_OF_BYTES_WRITE DESC;
--8、哪个表逻辑 IO 最多?
SELECT object_name,COUNT_READ, COUNT_WRITE, COUNT_FETCH,SUM_TIMER_WAIT FROM table_io_waits_summary_by_table
ORDER BY sum_timer_wait DESC;
--9、哪个素引访问最多?
SELECT OBJECT_NAME, INDEX_NAME,COUNT_FETCH,COUNT_INSERT,COUNT_UPDATE,COUNT_DELETE FROM table_io_waits_summary_by_index_usage
ORDER BY SUM_TIMER_WAIT DESC;
--10、哪个索引从来没有用过?
SELECT OBJECT_SCHEMA, OBJECT_NAME, INDEX_NAME FROM table_io_waits_summary_by_index_usage
WHERE INDEX_NAME IS NOT NULL AND COUNT_STAR = 0 AND OBJECT_SCHEMA < 'mysal'
ORDER BY OBJECT_SCHEMA,OBJECT_NAME;
--11、哪个等待事件消耗时间最多?
SELECT EVENT_NAME,COUNT_STAR,SUM_TIMER_WAIT,AVG_TIMER_WAIT FROM events_waits_summary_global_by_event_name
WHERE event_name != 'idle'
ORDER BY SUM_TIMER_WAIT DESC;
--12-1、剖析某条 SQL 的执行情况,包括 statement 信息,stege 信息,wait 信息
SELECT EVENT_ID,sqL_text FROM events_statements_history WHERE sql_text LIKE '*%count(*)%';
--12-2、查看每个阶段的时间消耗
SELECT event_id, EVENT_NAME,SOURCE, TIMER_END - TIMER_START FROM events_stages_history_long WHERE NESTING_EVENT_ID = 1553;
--12-3、查看每个阶段的锁等待情况
SELECT event_id, event_name,source,timer_wait,object_name, index_name, operation,nesting_event_id FROM events_waits_history_long WHERE nesting_event_id = 1553;
where条件优化
- 测试表结构
CREATE TABLE `demo` (
`id` int NOT NULL AUTO_INCREMENT,
`name` varchar(10) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '名称',
`phone` varchar(11) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '用户手机号',
`age` int NOT NULL COMMENT '用户年龄',
`remark` varchar(255) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '备注',
PRIMARY KEY (`id`),
KEY `idx_name_phone_age` (`name`,`phone`,`age`),
KEY `idx_remark` (`remark`)
) ENGINE=InnoDB AUTO_INCREMENT=17808 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
- SQL 性能优化的 type 指标
explain 中的 type:至少要达到 range 级别,要求是 ref 级别,consts 最好
1、consts:单表中最多只有一个匹配行(主键或者唯一索引),在优化阶段即可读取到数据
2、ref:使用普通的索引
3、range:对索引进行范围检索
4、index:索引物理文件全扫,速度非常慢
组合索引需要遵循最左前缀原则

查询条件避免隐式转化

注意1:组合索引下,如果出现数据的隐士转化会触发优化器优化,索引也是生效的

注意:如果查询条件的数据类型和索引的不匹配,则会触发隐士转化,导致索引失效
查询条件避免计算或使用函数
注意:mysql8.0开始,通过函数索引可以避免索引字段使用函数时失效的情况
like(满足指定条件)

注意:模糊搜索%开头会导致索引失效,%结尾索引生效的几率时随机的
or(不推荐)

注意1:or两边的字段不同时,两边的索引都要生效才行


注意2:or连接的字段相同时,or 条件很多的情况下,可以使用in来优化
is null(不推荐)
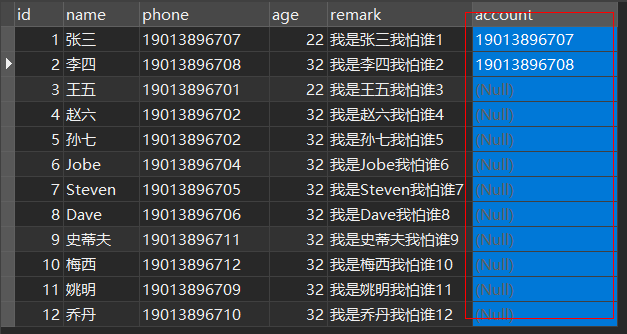

注意:当 null 数据超过80%时索引会失效,所以不建议使用,建议使用默认值代替
is not null(不推荐)
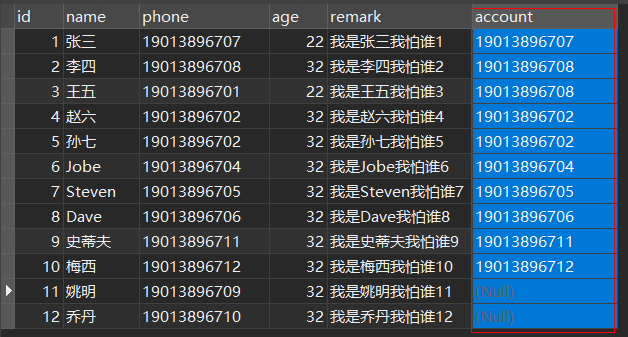

注意:当 is not null 数据超过80%时索引会失效,所以不建议使用,建议使用默认值代替
in 和 exists 比较
select * from A where id in (select id from B)
# in里面的B表先执行,适合于外表大而内表小的情况
select * from A where exists(select * from B where 表B.id=A.id)
# exists以外层A表为驱动表,适合于外表小而内表大的情况
not in(不推荐)
– 优化方案:左连接,条件:至少需要2个查询条件命中索引
select temp1.*,temp2.user_id as userId from order_count temp1 left join (
select user_id from order_count where user_id in (‘1649123035720’,‘1649123035724’)
) temp2 on temp1.user_id = temp2.user_id
where temp2.user_id is null and temp1.user_id = ‘1649123035728’;
group by 优化
Using filesort:通过索引或者全表扫描,读取满足条件数据,再在排序缓冲区 sort buffer 中排序,所以返回的数据不是通过索引直接返回的
Using index:通过有序索引顺序扫描直接返回有序数据,不需要额外的排序,所以效率比较高
根据多字段排序时,遵循左前缀原则
order by 优化
分组操作时,通过索引来提高效率,索引使用也要满足左前缀原则
limit 优化
对于 limit m,n 分页查询,越往后面翻页(即m越大的情况下)SQL的耗时会越来越长。当检索数据为 limit m,n 时,则需要排序前 m+n 条记录,最终只返回 m和m+n 间的 n 条数据,其他数据丢弃
使用索引覆盖 + 子查询优化
因为有主键 id,并且在上面建了索引,所以可以先在索引树中找到开始位置的 id 值,再根据找到的 id 值查询行数据
select id,name from table_name where id > (select id from table_name order by id limit 866612, 1)
起始位置重定义(效率最高)
可以取前一页的最大行数的id(将上次遍历到的最末尾的数据ID传给数据库,然后直接定位到该ID处,再往后面遍历数据),然后根据这个最大的id来限制下一页的起点。比如此列中,上一页最大的id是866612
select id,name from table_name where id > 866612 limit 20
join 关优化
驱动表
被驱动表