目录
1、llama模型转换(pytorch格式转换为HuggingFace格式)
1.1、拉取Chinese-LLaMA-Alpaca项目
1.2、准备文件夹
1.3、下载llama官方原始模型
1.4、移动文件到指定位置
1.5、执行转换脚本
2、合并模型
2.1、下载Chinese-LLaMA-Plus-7B模型
2.2、下载chinese_alpaca_plus_lora_7b模型
2.3、执行合并脚本
3、准备数据集
4、进行二次预训练
4.1、修改run_pt.sh文件
4.1、运行run_pt.sh文件
4.2、训练后文件整理
4.3、合并模型
5、推理模型
5.1、命令行方式推理合并后的模型
5.2、Web图形界面方式推理合并后的模型
大家知道AI模型是怎么训练出来的吗?
AI模型的训练训练过程分为如下三个阶段
第一个阶段叫做无监督学习(PreTraining),就是输入大量的文本语料让GPT自己寻找语言的规律, 这样一个巨大的词向量空间就形成了,但是话说的漂亮并不一定正确。
第二个阶段叫做监督学习(Supervised Fine-Tuning,也叫微调),就是人工标注一些语料,教会GPT什 么该说,什么不该说。(训练数据集)
第三个阶段叫做强化学习(RM,也叫奖励模型训练),就是给GPT的回答进行打分,告诉他在他 的一众回答中,哪些回答更好。(验证数据集)
第一个阶段(无监督学习),又分为了底座模型预训练,及增量预训练,它们都属于无监督学习,基座模型预训练可以查看上篇文章:使用数据预训练一个AI语言模型
本文主要来聊聊有了一个底座模型之后,如何继续使用大量文本进行增量预训练。
1、llama模型转换(pytorch格式转换为HuggingFace格式)
由于使用的底座模型是llama,官方公布的是PyTorch版本,为了方便后续使用,需转换为HuggingFace格式
1.1、拉取Chinese-LLaMA-Alpaca项目
# 我的文件路径为如下
cd /root/autodl-fs
git clone https://github.com/ymcui/Chinese-LLaMA-Alpaca.git1.2、准备文件夹
以下命令依次执行!
cd Chinese-LLaMA-Alpaca
mkdir model
cd model
mkdir llama
mkdir output
mkdir llama/7B
1.3、下载llama官方原始模型
wget https://agi.gpt4.org/llama/LLaMA/tokenizer.model -O ./tokenizer.model
wget https://agi.gpt4.org/llama/LLaMA/tokenizer_checklist.chk -O ./tokenizer_checklist.chk
wget https://agi.gpt4.org/llama/LLaMA/7B/consolidated.00.pth -O ./7B/consolidated.00.pth
wget https://agi.gpt4.org/llama/LLaMA/7B/params.json -O ./7B/params.json1.4、移动文件到指定位置
mv tokenizer.model llama
mv tokenizer_checklist.chk consolidated.00.pth params.json llama/7B1.5、拉取transformers项目并安装依赖
cd /root/autodl-fs
git clone https://github.com/huggingface/transformers.git
pip install torch==1.13.1 -i https://pypi.mirrors.ustc.edu.cn/simple/
pip install sentencepiece==0.1.97 -i https://pypi.mirrors.ustc.edu.cn/simple/
pip install peft==0.3.0 -i https://pypi.mirrors.ustc.edu.cn/simple/
pip uninstall tokenizers
pip install tokenizers==0.13.3 -i https://pypi.mirrors.ustc.edu.cn/simple/
pip install transformers==4.28.1 -i https://pypi.mirrors.ustc.edu.cn/simple/1.5、执行转换脚本
cd /root/autodl-fs/transformers
python src/transformers/models/llama/convert_llama_weights_to_hf.py \
--input_dir /root/autodl-fs/Chinese-LLaMA-Alpaca/model/llama/ \
--model_size 7B \
--output_dir /root/autodl-fs/Chinese-LLaMA-Alpaca/model/output参数说明:
-
--input_dir:tokenizer.model存放路径 -
--model_size:其余llama文件存放路径 -
--output_dir:存放转换好的HF版权重路径
2、合并模型
由于原始llama模型对中文的支持不是很优秀,所以需合并一个Chinese-LLaMA-Plus-7B模型和chinese_llama_plus_lora_7b模型
2.1、下载Chinese-LLaMA-Plus-7B模型
链接:百度网盘 请输入提取码 提取码:082w
上传到/root/autodl-fs/llama_7b目录下并解压缩
cd /root/autodl-fs/llama_7b
mkdir chinese_llama_plus_lora_7b
unzip chinese_llama_plus_lora_7b.zip chinese_llama_plus_lora_7b2.2、下载chinese_alpaca_plus_lora_7b模型
链接:百度网盘 请输入提取码 提取码:yr3q
上传到/root/autodl-fs/llama_7b目录下并解压缩
cd /root/autodl-fs/llama_7b
mkdir chinese_alpaca_plus_lora_7b
unzip chinese_alpaca_plus_lora_7b.zip chinese_alpaca_plus_lora_7b
2.3、执行合并脚本
cd /root/autodl-fs/Chinese-LLaMA-Alpaca/
# 合并后的模型存放位置
mkdir model/firstmergemodel
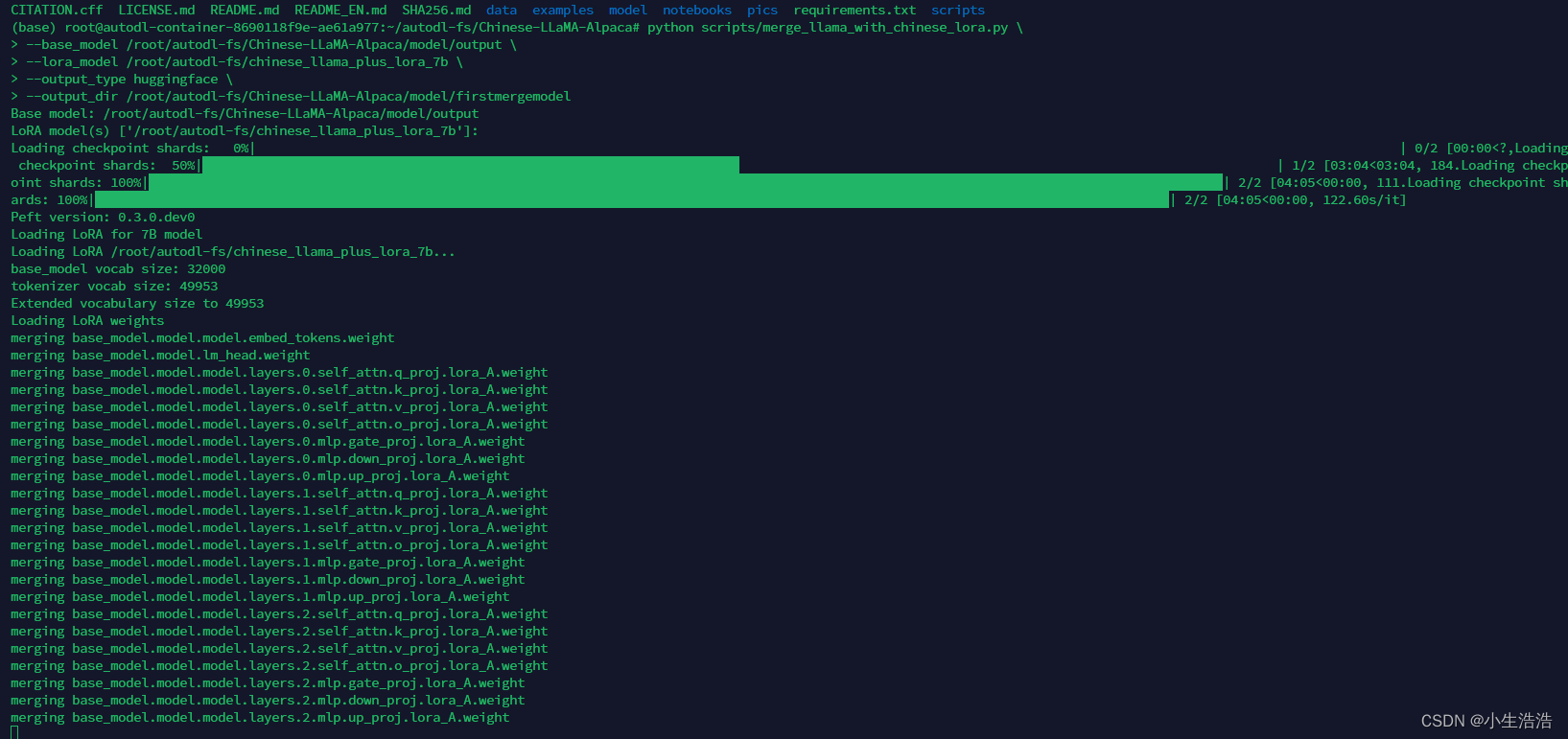
python scripts/merge_llama_with_chinese_lora.py \
--base_model /root/autodl-fs/Chinese-LLaMA-Alpaca/model/output \
--lora_model /root/autodl-fs/llama_7b/chinese_llama_plus_lora_7b,/root/autodl-fs/llama_7b/chinese_alpaca_plus_lora_7b \
--output_type huggingface \
--output_dir /root/autodl-fs/Chinese-LLaMA-Alpaca/model/firstmergemodels参数说明:
-
--base_model:存放HF格式的LLaMA模型权重和配置文件的目录 -
--lora_model:中文LLaMA/Alpaca LoRA解压后文件所在目录,也可使用🤗Model Hub模型调用名称,提供两个lora_model的地址,用逗号分隔。⚠️ 两个LoRA模型的顺序很重要,不能颠倒。先写LLaMA-Plus-LoRA然后写Alpaca-Plus-LoRA -
--output_type: 指定输出格式,可为pth或huggingface。若不指定,默认为pth -
--output_dir:指定保存全量模型权重的目录,默认为./ -
(可选)
--offload_dir:对于低内存用户需要指定一个offload缓存路径
3、准备数据集
mkdir /root/autodl-fs/Chinese-LLaMA-Alpaca/txttxt文件上传到该文件夹下
4、进行二次预训练
4.1、修改run_pt.sh文件
cd /root/autodl-fs/Chinese-LLaMA-Alpaca/scripts/training
vi run_pt.shrun_pt.sh文件如下
lr=2e-4
lora_rank=8
lora_alpha=32
lora_trainable="q_proj,v_proj,k_proj,o_proj,gate_proj,down_proj,up_proj"
modules_to_save="embed_tokens,lm_head"
lora_dropout=0.05
### 对原版llama的hf文件与chinese_llama_plus_lora_7b及chinese_Alpaca_plus_lora_7b合并后结果
pretrained_model=/root/autodl-fs/Chinese-LLaMA-Alpaca/model/firstmergemodels
### Chinese-Alpaca tokenizer所在的目录
chinese_tokenizer_path=/root/autodl-fs/llama_7b/chinese_alpaca_plus_lora_7b
### 预训练数据的目录,可包含多个以txt结尾的纯文本文件
dataset_dir=/root/autodl-fs/Chinese-LLaMA-Alpaca/txt
### 指定一个存放数据缓存文件的目录
data_cache=/root/autodl-fs/Chinese-LLaMA-Alpaca/cache
per_device_train_batch_size=1
per_device_eval_batch_size=1
training_steps=100
gradient_accumulation_steps=1
### 模型输出的路径
output_dir=/root/autodl-fs/Chinese-LLaMA-Alpaca/model/pt_output
deepspeed_config_file=ds_zero2_no_offload.json
torchrun --nnodes 1 --nproc_per_node 1 run_clm_pt_with_peft.py \
--deepspeed ${deepspeed_config_file} \
--model_name_or_path ${pretrained_model} \
--tokenizer_name_or_path ${chinese_tokenizer_path} \
--dataset_dir ${dataset_dir} \
--data_cache_dir ${data_cache} \
--validation_split_percentage 0.001 \
--per_device_train_batch_size ${per_device_train_batch_size} \
--per_device_eval_batch_size ${per_device_eval_batch_size} \
--do_train \
--seed 1 \
--fp16 \
--max_steps ${training_steps} \
--lr_scheduler_type cosine \
--learning_rate ${lr} \
--warmup_ratio 0.05 \
--weight_decay 0.01 \
--logging_strategy steps \
--logging_steps 10 \
--save_strategy steps \
--save_total_limit 3 \
--save_steps 500 \
--gradient_accumulation_steps ${gradient_accumulation_steps} \
--preprocessing_num_workers 8 \
--block_size 512 \
--output_dir ${output_dir} \
--overwrite_output_dir \
--ddp_timeout 30000 \
--logging_first_step True \
--lora_rank ${lora_rank} \
--lora_alpha ${lora_alpha} \
--trainable ${lora_trainable} \
--modules_to_save ${modules_to_save} \
--lora_dropout ${lora_dropout} \
--torch_dtype float16 \
--gradient_checkpointing \
--ddp_find_unused_parameters False4.1、运行run_pt.sh文件
sh run_pt.sh
4.2、训练后文件整理
训练后的LoRA权重和配置存放于
/root/autodl-fs/Chinese-LLaMA-Alpaca/model/pt_output/pt_lora_model,可用于后续的合并流程。
-
创建一个文件夹
${lora_model},用于存放LoRA模型cd /root/autodl-fs/Chinese-LLaMA-Alpaca/model/pt_output/pt_lora_model mkdir lora_model -
将
${output_dir}中训练好的adapter_model.bin移动到${lora_model}cp adapter_model.bin lora_model cd lora_model -
将Chinese-Alpaca-LoRA 中的tokenizer相关文件复制到
${lora_model}cp /root/autodl-fs/llama_7b/chinese_alpaca_plus_lora_7b/*token* . -
将Chinese-Alpaca-LoRA中的
adapter_config.json复制到${lora_model}cp /root/autodl-fs/llama_7b/chinese_alpaca_plus_lora_7b/adapter_config.json . -
编辑
${lora_model}/adapter_config.json文件,修改其中的参数,确认其中的lora_alpha,r,modules_to_save,target_modules等参数与实际训练用的参数一致。
4.3、合并模型
cd /root/autodl-fs/Chinese-LLaMA-Alpaca/model
mkdir ptmerge_model
cd /root/autodl-fs/Chinese-LLaMA-Alpaca
python scripts/merge_llama_with_chinese_lora.py \
--base_model /root/autodl-fs/Chinese-LLaMA-Alpaca/model/firstmergemodels \
--lora_model /root/autodl-fs/Chinese-LLaMA-Alpaca/model/pt_output/pt_lora_model/lora_model \
--output_type huggingface \
--output_dir /root/autodl-fs/Chinese-LLaMA-Alpaca/model/ptmerge_model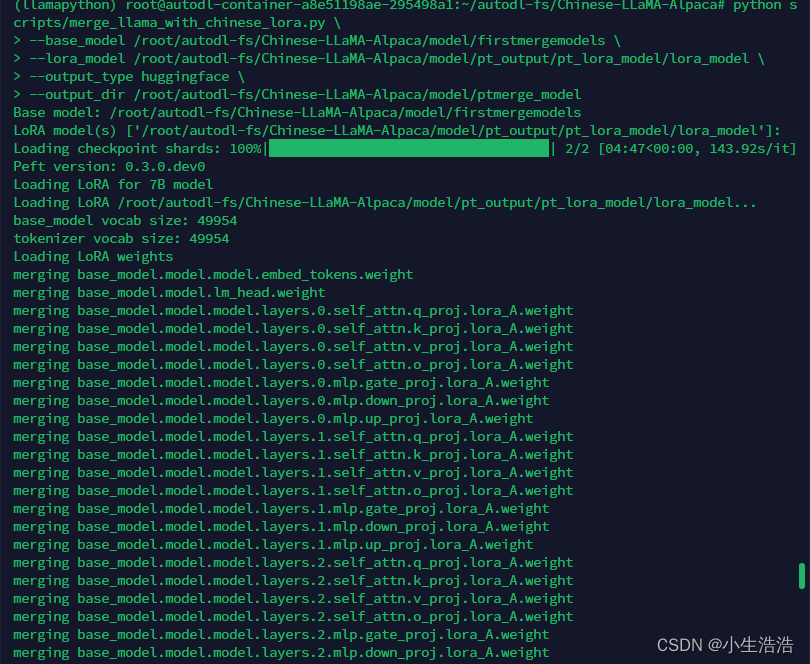
5、推理模型
5.1、命令行方式推理合并后的模型
cd /root/autodl-fs/Chinese-LLaMA-Alpaca
python scripts/inference/inference_hf.py --base_model model/ptmerge_model --with_prompt --interactive
5.2、Web图形界面方式推理合并后的模型
cd /root/autodl-fs/Chinese-LLaMA-Alpaca
python scripts/inference/gradio_demo.py --base_model model/ptmerge_model