文章目录
- 前言
- 踩坑日记
- 刨根问底
- 解决方案
- 小结
前言
最近一直在开发项目中的新需求,其中有一个需求是“解析文件(.txt文件,一行就是一条数据)中的数据并进行入库操作”。其实这个需求也很简单,无非就是将文件中每一行数据转换为一个对象,将每一个对象都存储到 list 集合中,最终执行批量入库的操作。但就是这么一个简单的需求却让我踩了一个大坑…
踩坑日记
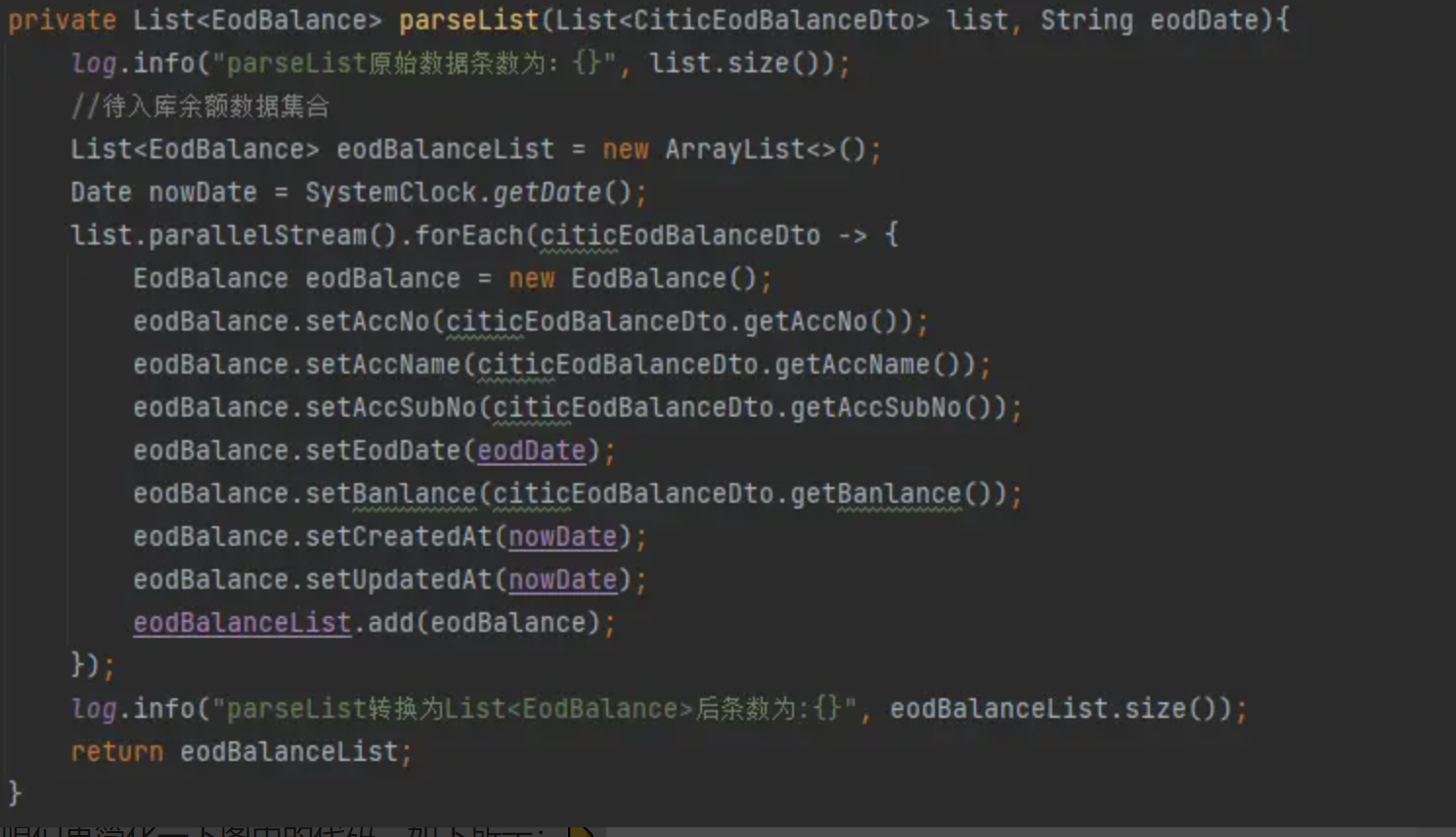
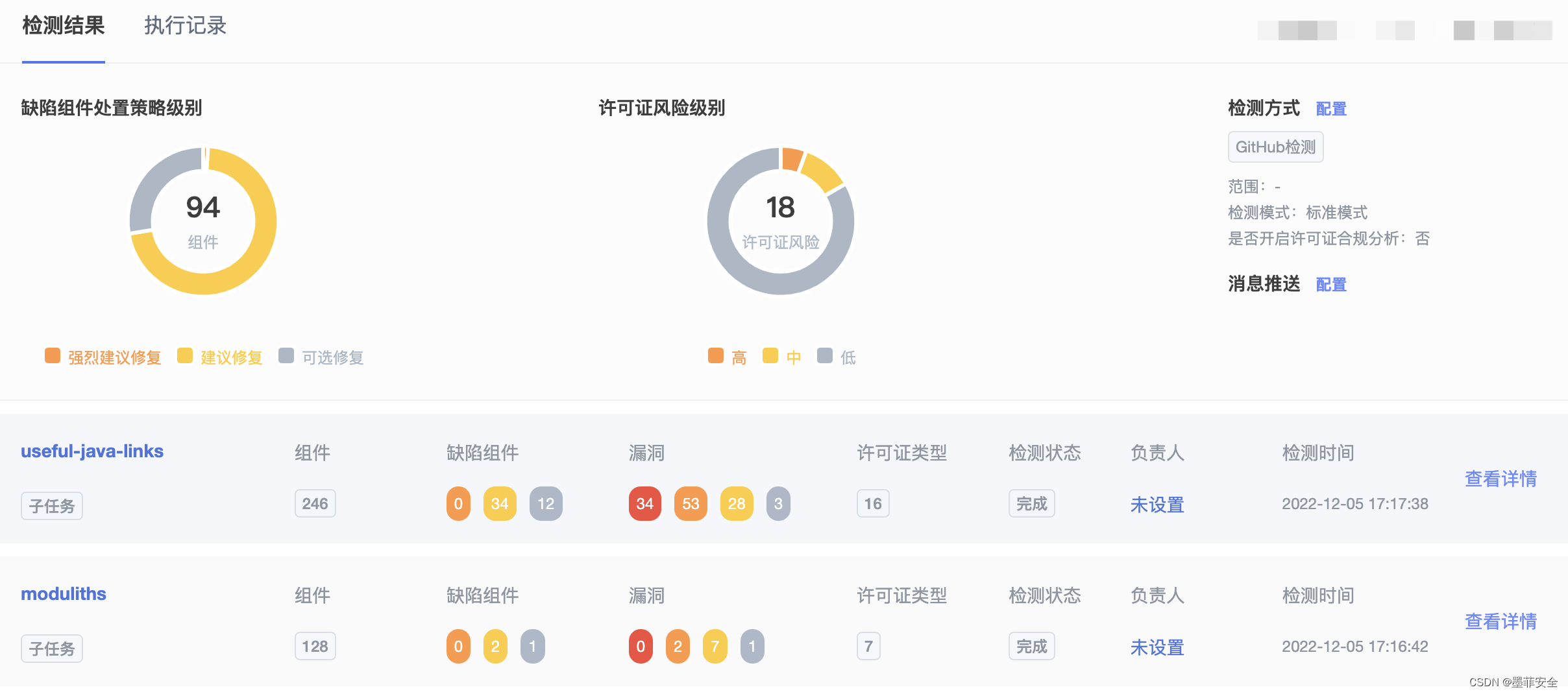
各位小伙伴先看一下上图中的代码,不知道各位小伙伴有没有看出什么问题呢?👆 可能这么看起来有些不好理解,咱们再简化一下图中的代码,如下所示:👇
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
for (int i = 0; i < 10000; i++) {
list.add(i);
}
System.out.println("a:"+list.size());
List<Integer> streamList = new ArrayList<>();
list.parallelStream().forEach(streamList::add);
System.out.println("b:"+streamList.size());
}
}
各位小伙伴看看简化后的代码,猜测一下 a 和 b 输出的值分别是多少呢?这里就不卖关子了,咱们直接揭晓答案
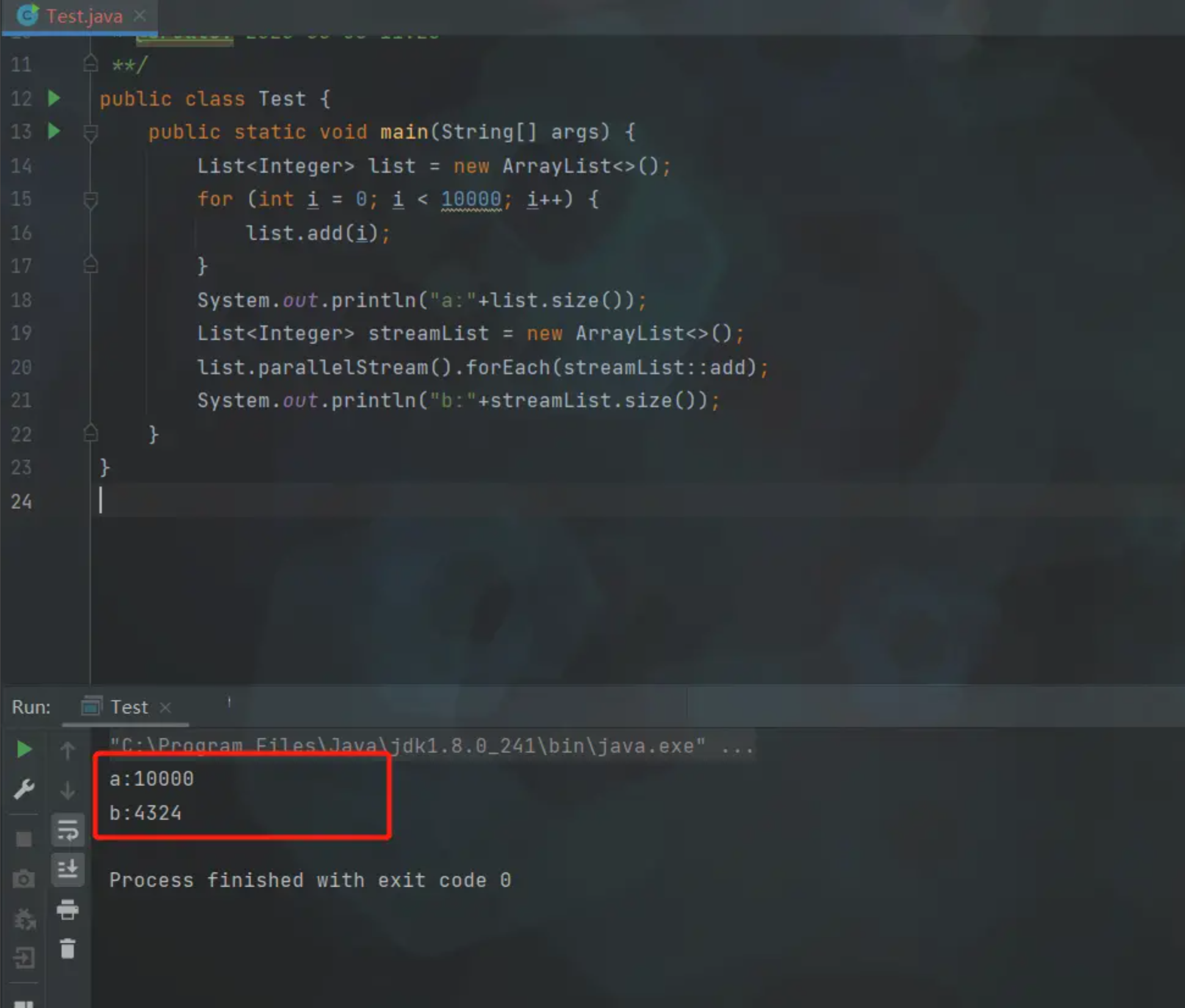
结果可能和大多数小伙伴猜测的都不太一样,a 和 b 的值居然不相等,且 b 的值 永远都会小于 a,同时在多次执行之后可能会出现数组下标越界异常,显然这里的代码是不符合逻辑的
这也是我在项目中遇倒的问题所在,解析完文件后,通过 parallelStream().forEach() 遍历结果进行处理,但是最终入库的数据条数总是小于文件中的数据条数。
刨根问底
经过一番探索,也是终于找到了问题答案…
Stream(流)是 JDK8 中引入的一种类似与迭代器(Iterator)的单向迭代访问数据的工具。ParallelStream
则是并行的流,它通过 Fork/Join 框架来拆分任务,加速流的处理过程。Fork/Join 的框架是通过把一个大任务不断 fork
成许多子任务,然后多线程执行这些子任务,最后再 Join 这些子任务得到最终结果。咱们回到实例代码中来解释一下,就是先将 list 集合
fork 成多段,然后多线程添加到 streamList 的结合中,而 streamList 是ArrayList 类型,ArrayList
的 add() 方法并不能保证原子性。
咱们先看一下 ArrayList 中 add() 方法的源码
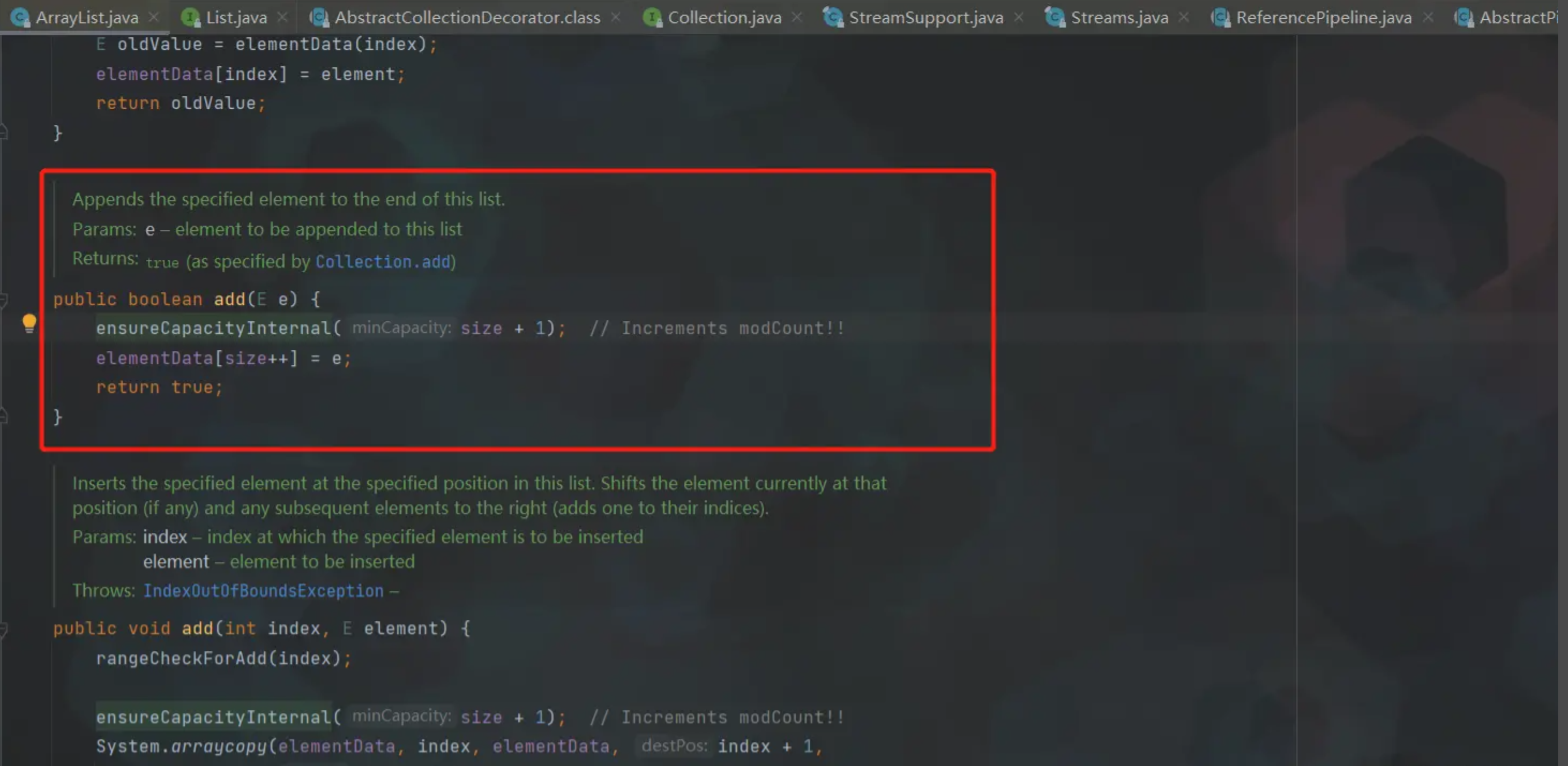
众所周知,ArrayList 作为 Collection 中极重要的一员,是非线程安全的,所以 ArrayList 并不适合多线程高并发的情况,在多线程高并发时会出现内部某些位置为 null 的情况。核心原因是,ArrayList 的add() 的方法不是线程安全的,是非原子性的,add操作可以简单理解为两个步骤:
- ensureCapacityInternal(size + 1) :确认当前 ArrayList 中的数组是否还可以加入新的元素。如果不行,就会再申请一个:int newCapacity = oldCapacity + (oldCapacity >> 1) 大小的数组(即容量变为原来的 1.5 倍),然后将数据复制过去。
- elementData[size++] = e:将元素添加到 elementData 数组中。
那么在多线程高并发情况下,如果有A、B两个线程同时执行 add() 方法,在第一步校验数组容量时,A、B线程都发现当前无需扩容,还可以继续添加一个元素;因此A、B线程都进入了第二步,此时,A线程先执行完,数组容量已满,然后B线程再对 elementData 赋值时,就会出现我们上面说到的情况,要么是数据丢失,要么是抛出数组下标越界的异常。
解决方案
问题原因我们已经找到了,那么问题的解决方案也就呼之欲出了~
- 方案一:将 parallelStream 改成 stream,或者直接使用 foreach 遍历处理。也就是放弃多线程的写法,改为传统的单线程处理。
- 方案二:使用 list = new CopyOnWriteArrayList<>(); 这是个线程安全的类。从源码上看,CopyOnWriteArrayList 在 add 操作时,通过 ReentrantLock 进行加锁,防止并发写。但是每次 add 操作都是把原数组中的元素拷贝一份到新数组中,然后在新数组中添加新元素,最后再把引用指向新数组,这也就会频繁的创建数组(千万别忘了数组需要一块连续的内存空间)。所以当实际业务逻辑中存在大量 add 操作时,要谨慎使用 CopyOnWriteArrayList 。
- 方案三:使用包装类 list = Collections.synchronizedList(Arrays.asList());
我们在使用 parallelStream 之前,一定要仔细思考一下自己的业务逻辑是否真的需要多线程并发处理。其实在实际应用场景中,并不是所有的问题都适合使用并发来解决,比如当数据量不大时,顺序执行往往比并行执行更快,毕竟准备线程池和其它相关资源也是需要时间的。但是,当任务涉及到 I/O 操作并且任务之间不互相依赖时,那么并行化就是一个不错的选择。
小结
本人经验有限,有些地方可能讲的没有特别到位,如果您在阅读的时候想到了什么问题,欢迎在评论区留言,我们后续再一一探讨