一、爬虫概述
爬虫是指利用网络抓取模块对某个网站或者某个应用中有价值的信息进行提取。还可以模拟用户在浏览器或者APP应用上的操作行为,实现程序自动化。简单来说就是我们把互联网有价值的信息都比喻成大的蜘蛛网,而各个节点就是存放的数据,而蜘蛛网的上蜘蛛比喻成爬虫,而爬虫是可以自动抓取互联网信息的程序,从互联网上抓取一切有价值的信息,并且把站点的信息爬到本地并且存储方便使用。
二、爬虫构架
Python爬虫架构主要由五个部分组成,分别是调度器、URL管理器、网页下载器、网页解析器、应用程序(爬取的有价值数据)。
1.调度器:相当于一台电脑CPU,主要负责调度URL管理器、下载器、解析器之间协调工作。
2.URL管理器:包括待爬取的URL地址和已爬取的URL地址,防止重复抓取URL和循环抓取URL,实现URL管理器主要用三种方式,通过内存、数据库、缓存数据库来实现。
URL(外文名:Uniform Resource Locator,中文名:统一资源定位符),统一资源定位符是对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。通常由网络协议、服务器域名、资源在服务器中位置组成。例如我们最熟悉的豆瓣电影排行榜TOP250 https://movie.douban.com/top250。
http - - 网络协议 movie.douban.com - - 服务器域名 top250 - - 资源在服务器中位置
3.网页下载器:通过传入一个URL地址来下载网页,将网页转换成一个字符串,网页下载器有urllib2(Python官方基础模块)包括需要登录、代理、和cookie,requests(第三方包)。
4.网页解析器:将一个网页字符串进行解析,可以按照我们的要求来提取出我们有用的信息,也可以根据DOM树的解析方式来解析。网页解析器有正则表达式(直观,将网页转成字符串通过模糊匹配的方式来提取有价值的信息,当文档比较复杂的时候,该方法提取数据的时候就会非常的困难)、html.parser(Python自带的)、beautifulsoup(第三方插件,可以使用Python自带的html.parser进行解析,也可以使用lxml进行解析,相对于其他几种来说要强大一些)、lxml(第三方插件,可以解析 xml 和 HTML),html.parser 和 beautifulsoup 以及 lxml 都是以 DOM 树的方式进行解析的。
5.应用程序:就是从网页中提取的有用数据组成的一个应用。
三、爬虫流程
1.发起请求:通过htttp协议向目标站点服务器发送发送一个包含headers(标头)、data(数据)等信息的request(请求),等待服务器响应。这个请求的过程就像我们打开浏览器,在浏览器地址栏输入一个网址然后点击回车。
HTTP 协议是 Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网( World Wide Web )服务器传输超文本到本地浏览器的传送协议。
万维网是一个由许多互相链接的超文本组成的系统,通过互联网访问。在这个系统中,每个有用的事物,称为一样“资源”;并且由一个全局“统一资源标识符”(URI)标识;这些资源通过HTTP(Hypertext Transfer Protocol)传送给用户,而后者通过点击链接来获得资源。
HTTP 是一个基于 TCP/IP 通信协议来传递数据(HTML 文件、图片文件、查询结果等)。
HTTPS 协议是 HyperText Transfer Protocol Secure(超文本传输安全协议)的缩写,是一种通过计算机网络进行安全通信的传输协议。
HTTPS 经由 HTTP 进行通信,但利用 SSL/TLS 来加密数据包,HTTPS 开发的主要目的,是提供对网站服务器的身份认证,保护交换资料的隐私与完整性。
HTTP 的 URL 是由 http:// 起始与默认使用端口 80,而 HTTPS 的 URL 则是由 https:// 起始与默认使用端口443。
2.获取响应: 如果服务器能正常响应,我们会得到一个response(请求),response(请求)的内容便是所要获取的内容,类型可能有html、json字符串,二进制数据(图片,视频等)等类型。这个过程就是服务器接收客户端的请求,进过解析发送给浏览器的网页html文件。
3.解析内容: 得到的内容可能是html,可以使用正则表达式,网页解析库进行解析。也可能是json,可以直接转为json对象解析。可能是二进制数据,可以做保存或者进一步处理。这一步相当于浏览器把服务器端的文件获取到本地,再进行解释并且展现出来。
4.保存数据: 保存的方式可以是把数据存为文本,也可以把数据保存到数据库,或者保存为特定的jpg、mp4 等格式的文件。这就相当于我们在浏览网页时,下载网页上的图片或者视频。
四、请求状态
当浏览者访问一个网页时,浏览者的浏览器会向网页所在服务器发出请求。当浏览器接收并显示网页前,此网页所在的服务器会返回一个包含 HTTP 状态码的信息头(server header)用以响应浏览器的请求。
1** 信息,服务器收到请求,需要请求者继续执行操作(100 - 客户端应继续请求);
2** 成功,操作被成功接收并处理(200 - 请求成功);
3** 重定向,需进一步的操作以完成请求(301 - 资源(网页等)被永久转移到其它URL);
4** 客户端错误,请求包含语法错误或无法完成请求(404 - 请求资源(网页等)不存在);
5** 服务器错误,服务器在处理请求的过程中发生了错误(500 - 内部服务器错误)。
五、请求方法
HTTP 请求方式一共有 9 种,分别为 POST 、GET 、HEAD、PUT 、PATCH 、 OPTIONS 、DELETE 、CONNECT 、 TRACE 。其中前三种 POST 、GET 、HEAD 是 HTTP 1.0 定义的,后六种 PUT 、PATCH 、 OPTIONS 、DELETE 、CONNECT 、 TRACE 是 HTTP 1.1 定义的。
1.GET请求指定的页面信息,并返回实体主体;
2.HEAD类似于 GET 请求,只不过返回的响应中没有具体的内容,用于获取报头;
3.POST向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST 请求可能会导致新的资源的建立和/或已有资源的修改;
4.PUT从客户端向服务器传送的数据取代指定的文档的内容;
5.DELETE请求服务器删除指定的页面;
6.CONNECTHTTP/1.1 协议中预留给能够将连接改为管道方式的代理服务器;
7.OPTIONS允许客户端查看服务器的性能;
8.TRACE回显服务器收到的请求,主要用于测试或诊断;
9.PATCH是对 PUT 方法的补充,用来对已知资源进行局部更新 。
六、网页构成
1、HTML(超文本标记语言):网页的本质就是超文本标记语言,他是将网页的各个部分标记出来让浏览器进行解析的。
2、CSS(层叠样式表):HTML用来进行标记,但是标记出来的网页比较混乱,美观程度比较差,CSS就是将HTML标记出来的内容合理摆放,并且对网页中的内容进行美化用的。即:HTML用来搭建一个框架,CSS用来美化这个框架。
3、客户端脚本语言(JavaScript):JavaScript是一种基于对象和事件驱动并具有相对安全性的客户端脚本语言。同时也是一种广泛用于客户端Web开发的脚本语言,常用来给HTML网页添加动态功能,用来进行网站和客户的交互。
HTML、CSS、JavaScript关系:HTML用来进行标记,CSS让页面更加美化、JavaScript来进行交互,分工很明确。
4、web服务器:一般指网站服务器,是指驻留于因特网上某种类型计算机的程序,可以处理浏览器等Web客户端的请求并返回相应响应,也可以放置网站文件,让全世界浏览;可以放置数据文件,让全世界下载。目前最主流的三个Web服务器是Apache、 Nginx 、IIS。
5、数据库:数据库指的是以一定方式储存在一起、能为多个用户共享、具有尽可能小的冗余度的特点、是与应用程序彼此独立的数据集合。在web里面他是用来让服务器端脚本语言来调用的。常用的数据库:Oracle、MySQL、SQL Server、DB2、MariDB。
冗余度就是从安全角度考虑多余的一个量,这个量就是为了保障仪器、设备或某项工作在非正常情况下也能正常运转。
七、网页文档
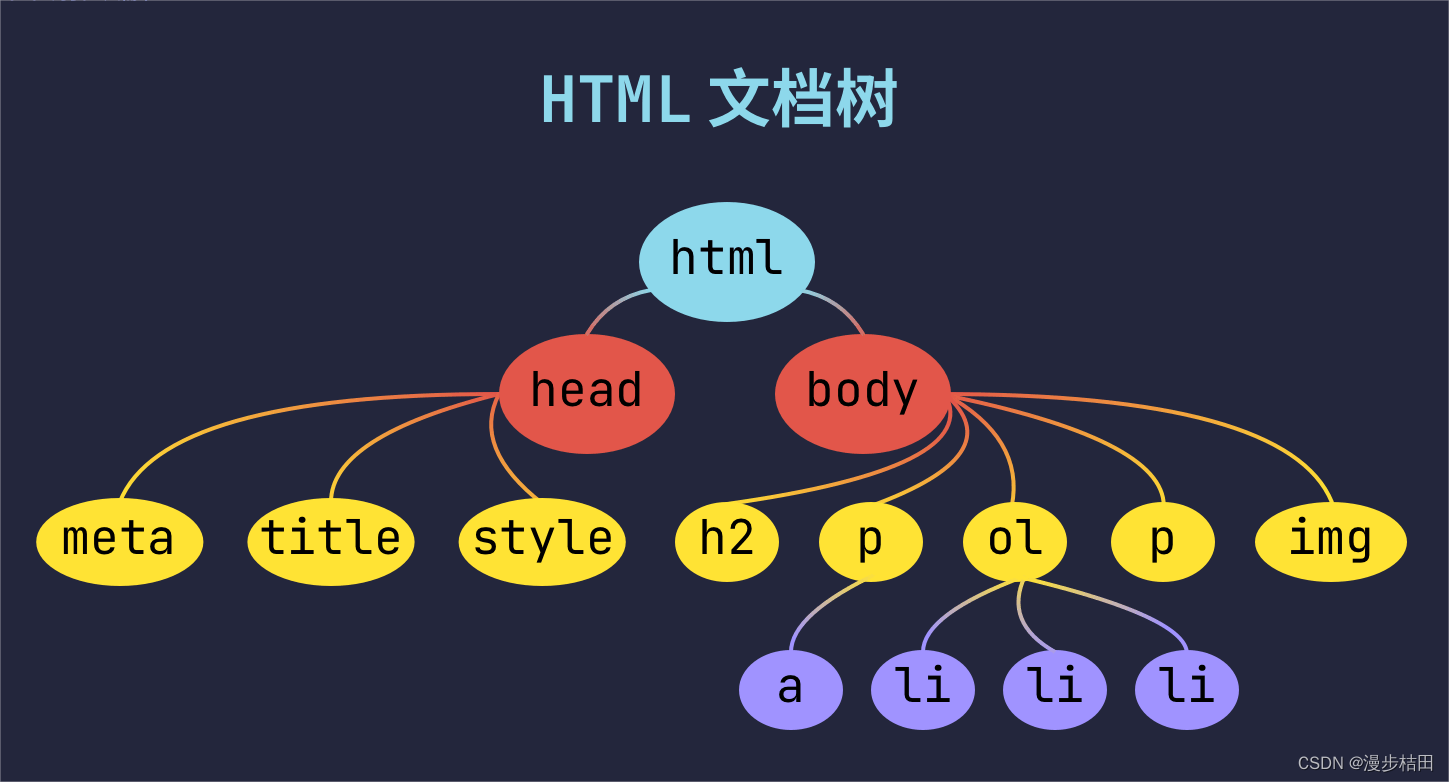
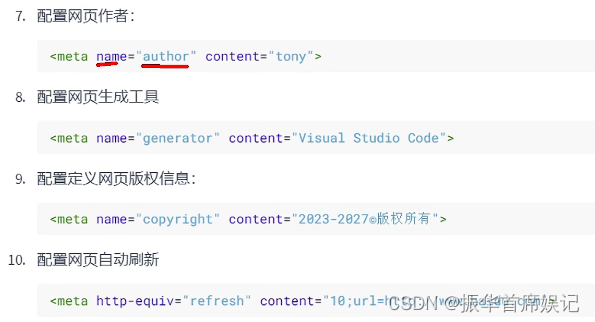
<!DOCTYPE html> 声明为 HTML文档
<html>..</html> 网页的根元素
<head>..</head> 元素包含了文档的元数据
<meta charset="utf-8"> 定义网页编码格式为 utf-8。
<title>..<title> 元素描述了文档的标题
<style type="text/css"> 用于为 HTML 文档定义CSS样式信息。
<body>..</body> 表示用户可见的内容
<div>..</div> 表示框架
<p>..</p > 表示段落
<ul>..</ul> 定义无序列表
<ol>..</ol> 定义有序列表
<li>..</li> 表示列表项
< img src="" alt=""> 表示图片
<h1>..</h1> 表示标题
<a href="">..</a > 表示超链接
八、requests
1.requests定义
Requests 是一个基于 Python 的 HTTP 库,它是可以在 Python 内置模块的基础上进行高度封装,使得发出 HTTP 请求变得更加简单和方便。Requests 可以通过 Apache2 Licensed 许可证进行开发。使用 Requests 库可以轻松完成浏览器相关的任何操作,包括模拟浏览器的请求。Requests 库可以用于网络爬虫,使得爬虫能够更加便捷迅速地实现。
2.requests参数
requests.request(method,url,**kwargs)
method:请求方式 url: 请求网址 **kwargs:控制访问参数,为可选项。
params: 请求参数,字典或字节序列作为参数传入,常用于发送 GET 请求时使用;
headers: 设置请求头,字典作为参数传入;
cookies: 字典cookies 值 , 用户身份信息;
proxies: 设置ip代理,字典作为参数传入;
data: 字典、字节或文件对象作为参数;
json: JSON格式的数据作为参数;
verify: 请求网站时是否需要验证证书,认证SSL证书开关;
cert : 本地SSL证书
timeout: 设置响应时间,一旦超过,程序会报错;
allow_redirects: 是否允许重定向, 布尔类型数据,默认为Ture;
files: 上传文件相关参数,以字典或文件对象的形式传递;
auth: 指定登陆时的账号和密码,元组作为参数传入,支持HTTP认证功能;
stream: 获取内容立即下载开关,布尔值,默认为True,为True时会先下载响应头,当Reponse调用content方法时才下载响应体。
3.requests属性
url:返回响应的URL地址;
status_code:返回响应状态码,例如200表示请求成功,404表示请求的资源不存在等;
headers:返回响应头信息,是一个字典类型;
text:返回响应的内容,是一个字符串类型;
content:返回响应的二进制内容,是一个bytes类型;
encoding:返回响应内容的编码格式;
cookies:返回响应的cookie信息,是一个字典类型;
json():返回响应的json格式数据,如果响应内容不是json格式,则会抛出异常;
history:返回请求历史,是一个列表类型,其中每个元素都是一个response对象。
九、BeautifulSoup(bs4 )
1.BeautifulSoup定义
BeautifulSoup是一个工具箱,通过解析文档为用户提供需要抓取的数据。因为简单,所以不需要多少代码就可以写出一个完整的应用程序。 Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为UTF-8编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时你仅仅需要说明一下原始编码方式就可以了。 Beautiful Soup已成为和lXML、HTML一样出色的Python解释器,为用户灵活地提供不同的解析策略或强劲的速度。 所以说,利用它可以省去很多烦琐的提取工作,提高了解析效率。
2.BeautifulSoup解析
| 解释器 | 用法 | 优点 | 缺点 |
| Python | BeautifulSoup(markup, “html.parser”) | Python的内置标准库、执行速度适中、文档容错能力强 | Python 2.7.3及Python 3.2.2之前的版本文档容错能力差 |
| xml HTML | BeautifulSoup(markup, “lxml”) | 速度快、文档容错能力强 | 需要安装C语言库 |
| lxml XML | BeautifulSoup(markup, “xml”) | 速度快、唯一支持XML的解析器 | 需要安装C语言库 |
| html5lib | BeautifulSoup(markup, “html5lib”) | 最好的容错性、以浏览器的方式解析文档、生成HTML5格式的文档 | 速度慢、不依赖外部扩展 |
3.BeautifulSoup方法
1)find_all():搜索当前tag的所有tag子节点,并判断是否符合过滤器的条件。返回值类型是bs4.element.ResultSet,是一个包含所有符合过滤条件的 tag子节点的列表。
find_all(name, attrs, recursive, text, **kwargs)
name:要搜索的标签的名称或正则表达式。
attr :要匹配的标签属性。可以是一个字典或一个函数,函数返回 True 表示匹配成功。
recursive 参数: 调用tag的 find_all() 方法时,Beautiful Soup会检索当前tag的所有子孙节点。如果只想搜索tag的直接子节点,可以使用参数 recursive=False 。
text 参数:要搜索的文本。可以是一个字符串或一个函数,函数返回 True 表示匹配成功。
**kwargs参数:其他参数将传递给Beautiful Soup解析器。
2)find():同上,只不过返回的值是筛选到的第一个tag子节点,类型为bs4.element.Tag。
BeautifulSoup还有10个类似find_all()和find()的查找方法用来搜索文档的不同部分。
find_parent():查找父节点;
find_parents():递归查找父节点。
find_next_siblings():查找后面的兄弟节点;
find_next_sibling():查找后面满足条件的第一个兄弟节点。
find_previous_siblings():方法返回所有符合条件的前面的兄弟节点;
find_previous_sibling():方法返回第一个符合条件的前面的兄弟节点。
find_all_next():查找后面所有节点;
find_next():查找后面第一个满足条件的节点。
find_all_previous():查找前面所有满足条件的节点;
find_previous():查找前面第一个满足条件的节点。
3)selector():使用 CSS 选择器选取元素。支持大多数 CSS 选择器语法。
4)descendants():返回所有子孙元素。
5)parents():返回所有祖先元素。
6)next_siblings():返回当前元素之后的所有同级元素。
7)previous_siblings():返回当前元素之前的所有同级元素。
4.BeautifulSoup属性
1)tag.name: tag对应的名称;
2)tag.attrs: tag属性的键值对;
3)tag['class']:tag属性class键对应的值,还可直接赋值进行修改;
4)tag.contents: 将tag的子节点以列表方式输出;
5)tag.children:返回tag的子节点迭代器;
6)tag.descendants:可以对所有tag的子孙节点进行递归循环。
5.BeautifulSoup方法
1)tag.get_text(): 获取tag中间的文本,可能包含子tag;
2)tag.get(‘href’): 获取tag里href属性对应的值,等价于tag[‘href’]。
十、CSS选择器
1.基本选择器
| 选择器 | 示例 | 说明 |
| .class | .intro | 选择class="intro"的所有节点 |
| #id | #firstname | 选择id="firstname"的所有节点 |
| * | * | 选择所有节点 |
| element | p | 选择所有p节点 |
| element,element | div,p | 选择所有div节点和所有p节点 |
| element element | div p | 选择div节点内部的所有p节点 |
| element>element | div>p | 选择父节点为div节点的所有p节点 |
| element+element | div+p | 选择紧接在div节点之后的所有p节点 |
| element~element | p~ul | 选择和p元素拥有相同父节点,并且在p元素之后的ul节点 |
| [attribute^=value] | a[src^=“https”] | 选择其src属性值以"https"开头的每个a节点 |
| [attribute$=value] | a[src$=".png"] | 选择其src属性以".png"结尾的所有a节点 |
| [attribute*=value] | a[src*=“abc”] | 选择其src属性中包含"abc"子串的每个a节点 |
| [attribute] | [target] | 选择带有target属性所有节点 |
| [attribute=value] | [target=_blank] | 选择target="_blank"的所有节点 |
| [attribute~=value] | [title~=china] | 选择title属性包含单词"china"的所有节点 |
| [attribute|=value] | [lang|=zh] | 选择lang属性值以"zh"开头的所有节点 |
2.位置选择器
| 选择器 | 示例 | 说明 |
| :first-of-type | p:first-of-type | 选择每个p元素是其父级的第一个p元素 |
| :last-of-type | p:last-of-type | 选择每个p元素是其父级的最后一个p元素 |
| :only-of-type | p:only-of-type | 选择每个p元素是其父级的唯一p元素 |
| :only-child | p:only-child | 选择每个p元素是其父级的唯一子元素 |
| :nth-child(n) | p:nth-child(2) | 选择每个p元素是其父级的第二个子元素 |
| :nth-last-child(n) | p:nth-last-child(2) | 选择每个p元素的是其父级的倒数第二个子元素 |
| :nth-of-type(n) | p:nth-of-type(2) | 选择每个p元素是其父级的第二个p元素 |
| :nth-last-of-type(n) | p:nth-last-of-type(2) | 选择每个p元素的是其父级的倒数第二个p元素 |
| :last-child | p:last-child | 选择每个p元素是其父级的最后一个子级。 |
3.其他选择器
| 选择器 | 示例 | 说明 |
| :not(selector) | :not(p) | 选择非p节点的节点 |
| :empty | p:empty | 选择没有子节点的p节点 |
| ::selection | ::selection | 选择被用户选取的节点 |
| :focus | input:focus | 选择获得焦点的input节点 |
| :root | :root | 选择文档的根节点 |
| :enabled | input:enabled | 选择每个启用的input节点 |
| :disabled | input:disabled | 选择每个禁用的input节点 |
| :checked | input:checked | 选择每个被选中的input节点 |
| :link | a:link | 选择所有未被访问的链接 |
| :visited | a:visited | 选择所有已被访问的链接 |
| :active | a:active | 选择活动链接 |
| :hover | a:hover | 选择鼠标指针位于其上的链接 |
| :first-letter | p:first-letter | 选择每个p节点的首字母 |
| :first-line | p:first-line | 选择每个p节点的首行 |
| :first-child | p:first-child | 选择属于父节点的第一个子节点的每个p节点 |
| :before | p:before | 在每个p节点的内容之前插入内容 |
| :after | p:after | 在每个p节点的内容之后插入内容 |
| :lang(language) | p:lang(it) | 选择带有以"it"开头的lang属性值的每个p节点 |
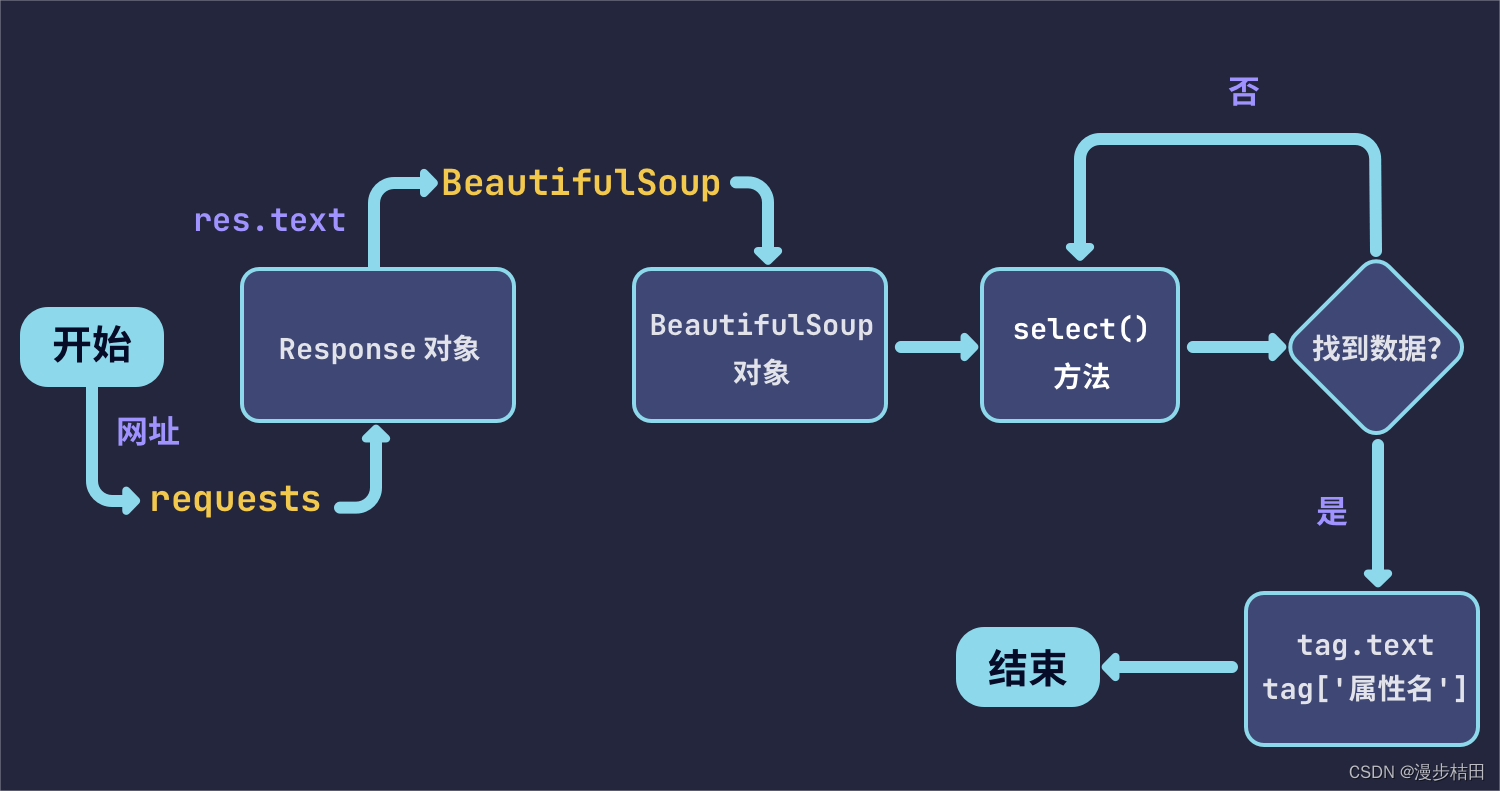
有兴趣的小伙伴可以参照爬虫电影排行榜(requests + bs4 )进行学习。