常见的推荐算法原理介绍,随着互联网的发展短视频运营越来越精准化,我们身边常见的抖音、火山小视频等软件让你刷的停不下来,这些软件会根据你的浏览行为推荐你感兴趣的相关内容,这就用到了很多推荐算法在里面。
在淘宝购物,在头条阅读新闻,在抖音刷短视频,背后其实都有智能推荐算法。这些算法不断分析、计算我们的购物偏好、浏览习惯,然后为我们推荐可能喜欢的商品、文章、视频。这些产品的推荐算法如此智能、高效,以至于我们常常一打开淘宝就买个不停一打开抖音就停不下来。
大数据平台只是提供了数据获取、存储、计算、应用的技术方案,真正挖掘这些数据之间的关系让数据发挥价值的是各种机器学习算法。在这些算法中,常见的当属智能推荐算法了,接下来就具体的分析一下:
一、人口统计的推荐原理
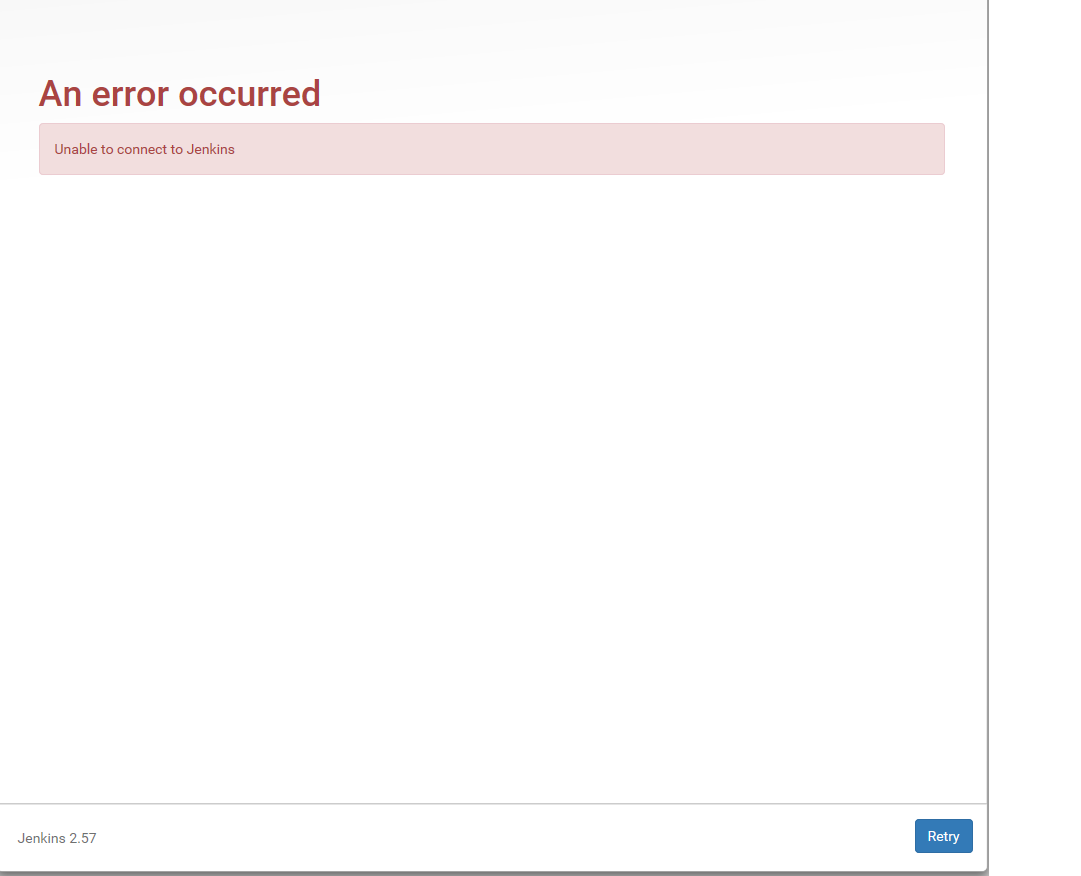
基于人口统计的推荐是相对简单的一种推荐算法,它会根据用户的基本信息进行分类,然后将商品推荐给同类用户: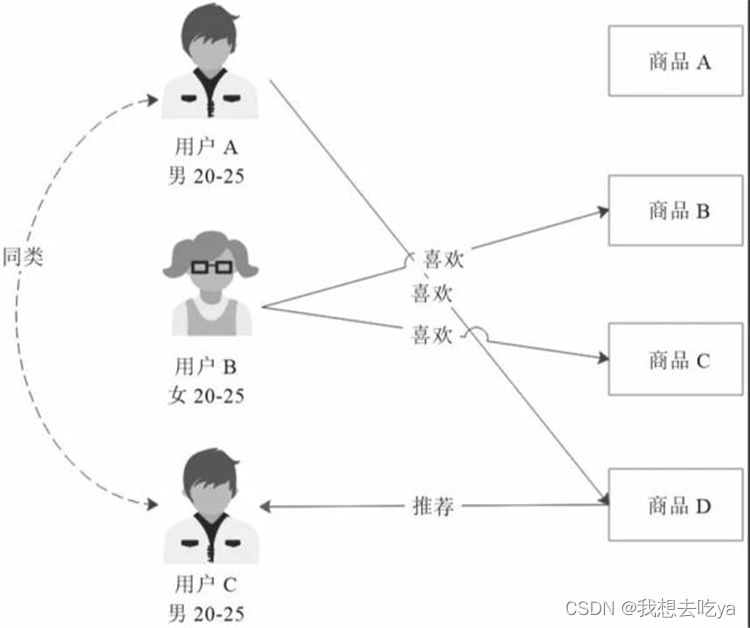
用户A和用户C的年龄相近、性别相同,可以将他们划分为同类。用户A喜欢商品D,因此推测用户C可能也喜欢这个商品,系统就可以将这个商品推荐给用户。在实践中,还应该根据用户收入、居住地区、学历、职业等各种因素对用户进行分类,以使推荐的商品更加准确。
二、商品属性的推荐原理
基于商品属性的推荐和基于人口统计的推荐相似,只是它是根据商品的属性进行分类,然后根据商品分类进行推荐:
基于商品属性的推荐
电影A和电影D都是科幻、战争类型的电影,如果用户A喜欢电影A,很有可能他也会喜欢电影D,因此就可以给用户A推荐电影D。这和我们的生活常识也是相符合的。如果一个人连续看了几篇关于篮球的新闻,那么再给他推荐一篇篮球的新闻,他很大可能会有兴趣看。
三、用户的协同过滤推荐
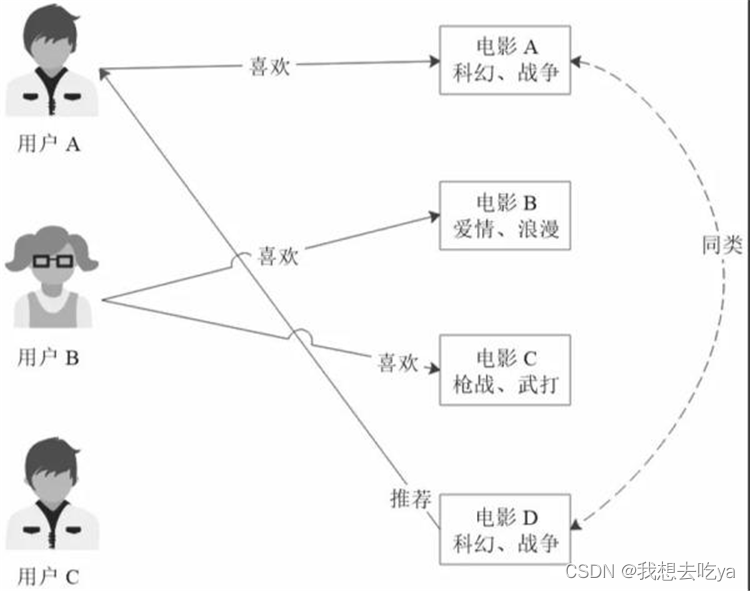
基于用户的协同过滤推荐是根据用户的喜好进行用户分类,然后根据用户分类进行推荐: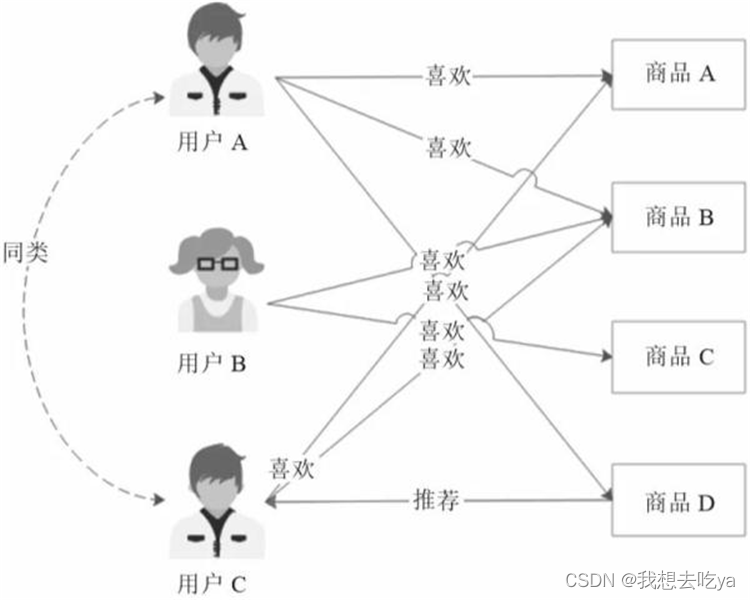
基于用户的协同过滤推荐
用户A和用户C都喜欢商品A和商品B,根据他们的喜好可以分为同类。用户A还喜欢商品D,那么将商品D推荐给用户C,他可能也会喜欢。
现实中,跟我们有相似喜好、品味的人也常常被我们当作同类,我们也愿意去尝试他们喜欢的其他东西。
四、商品的协同过滤推荐
基于商品的协同过滤推荐则是根据用户的喜好对商品进行分类,然后根据商品分类进行推荐: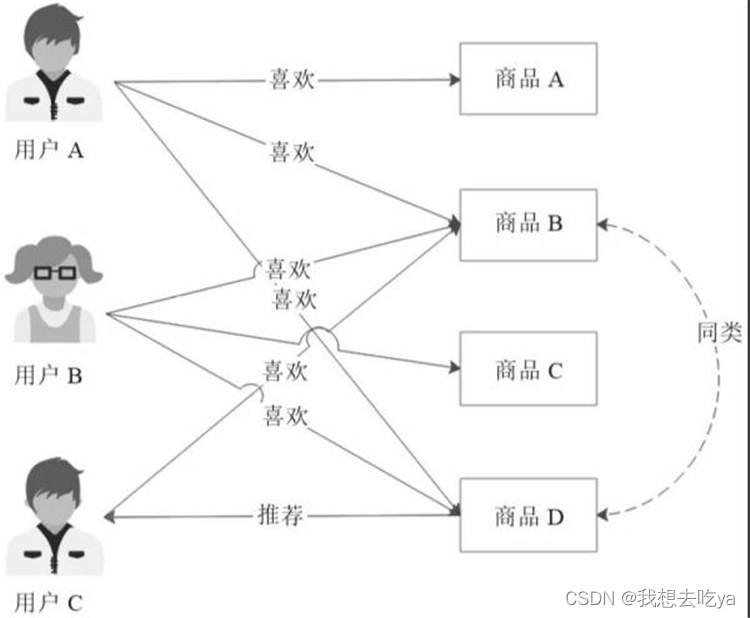
基于商品的协同过滤推荐
喜欢商品B的用户A和用户B都喜欢商品D,那么商品B和商品D就可以分为同类。对于同样喜欢商品B的用户C,很有可能也喜欢商品D,就可以将商品D推荐给用户C。
描述的推荐算法比较简单,但事实上要想做好推荐其实是非常难的,用户不要你觉得他喜欢而要自己觉得喜欢。现实中,有很多智能推荐的效果并不好被用户吐槽是“人工智障”。推荐算法的优化需要不断地收集用户的反馈不断地迭代算法和升级数据。
猎聘大数据研究院发布了《2022未来人才就业趋势报告》
从排名来看,2022年1-4月各行业中高端人才平均年薪来看,人工智能行业中高端人才平均年薪最高,为31.04万元;金融行业中高端人才以27.69万元的平均年薪位居第二;通信、大数据行业中高端人才平均年薪分别为27.51万元、25.23万元,位列第三、第四;IT/互联网行业中高端人才平均年薪23.02万元,位列第七。
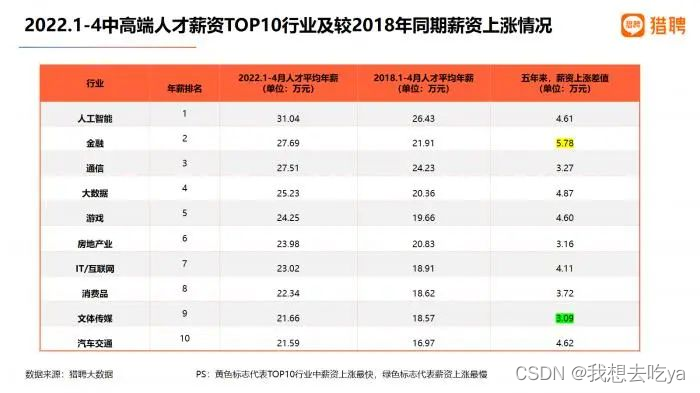
图表来源:《2022未来人才就业趋势报告》
如果你觉得很高,被平均了这样?那么打开Boss直聘,搜大数据工程师:
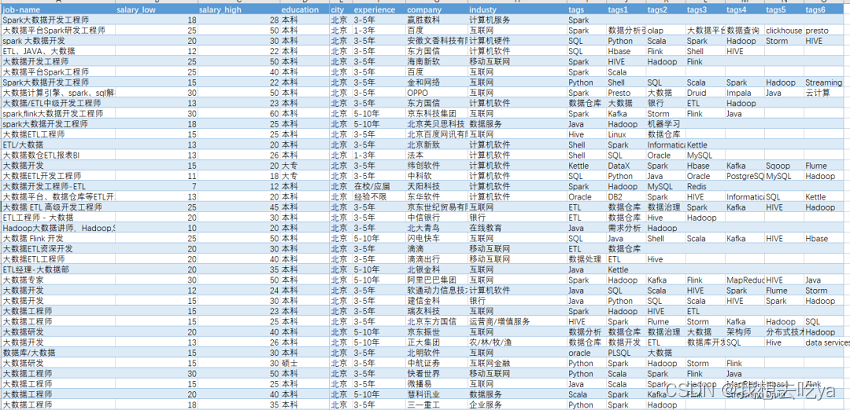
我们来做下数据分析:
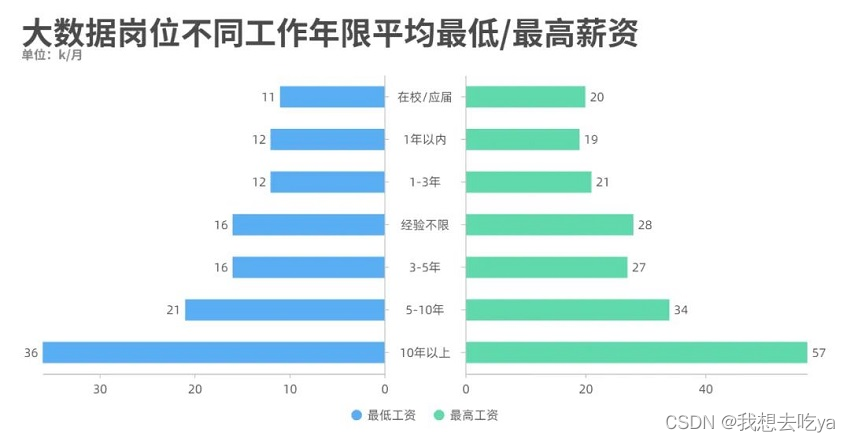
薪资那一列都有一个最低薪资和最高薪资,我们通过不同城市来对比分析一下,发现北京的工资水平最高,最低为22k,最高为38k。
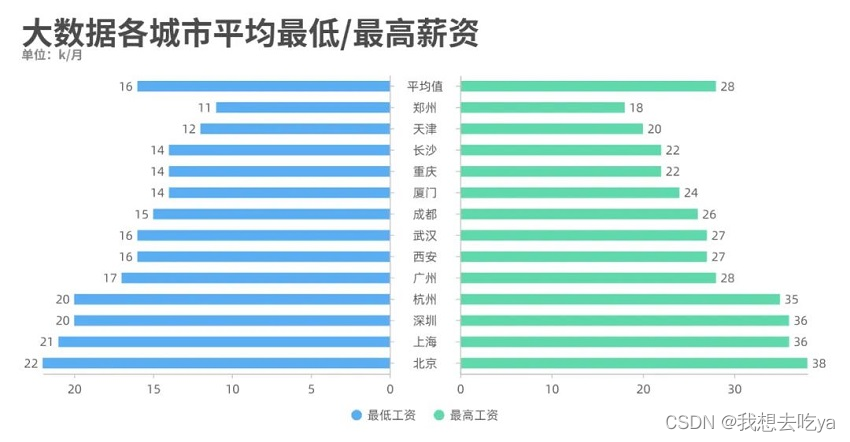
工作年限也是一个制约工资水平的很大因素,从图中可以看出,即使是刚毕业,也能达到一个11-20k的薪资范围。
而学历要求来说,大部分为本科,其次为大专和硕士,其他比较少,以至于在图中并没有显示出来。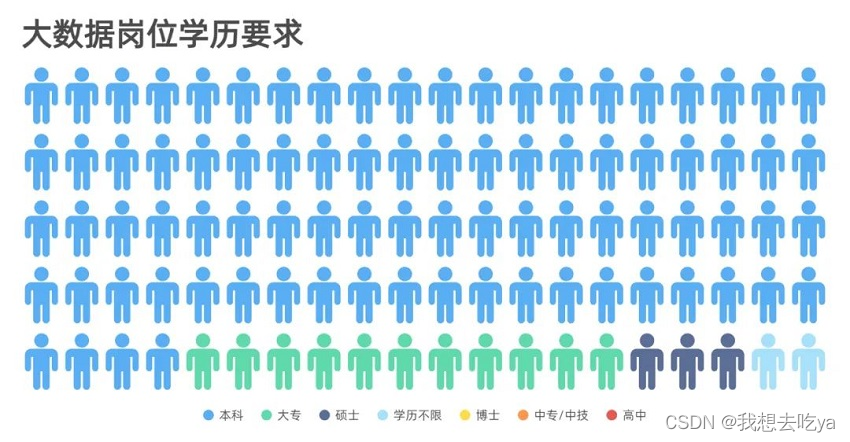
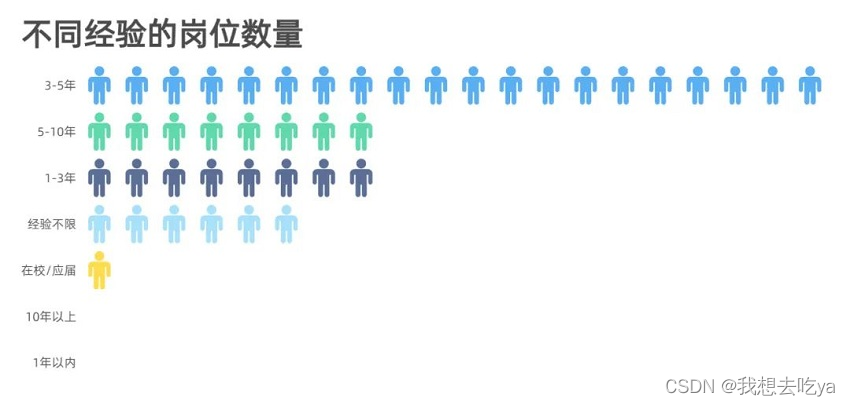
企业对不同岗位的要求以3-5年的居多,企业当然是需要有一定工作经验的员工,但是在实际招聘中,如果你有项目经验,且理论知识没问题,企业也会放宽条件。
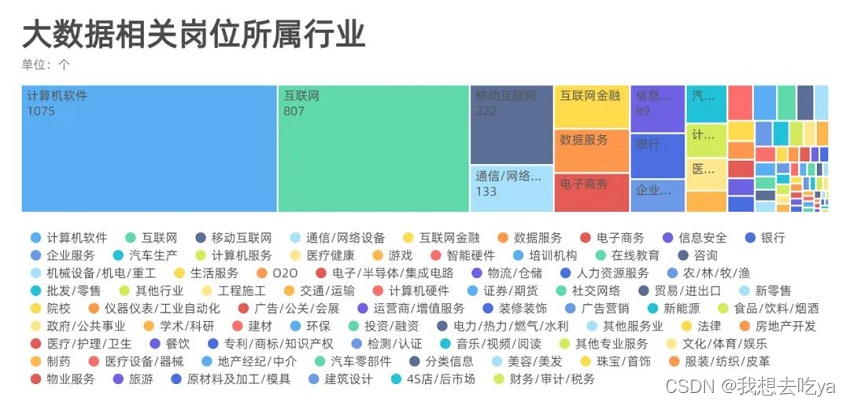
分析不同行业, 我们发现,大数据岗位需求分布在各行各业,主要还是在计算机软件和互联网最多,也有可能是这个招聘软件决定的,毕竟Boss直聘还是以互联网行业为主。
来看看哪些公司在招聘大数据相关岗位,从这个超过15的数量来看,华为,腾讯,阿里,字节,这些大厂对这个岗位的需求量还是很大的。
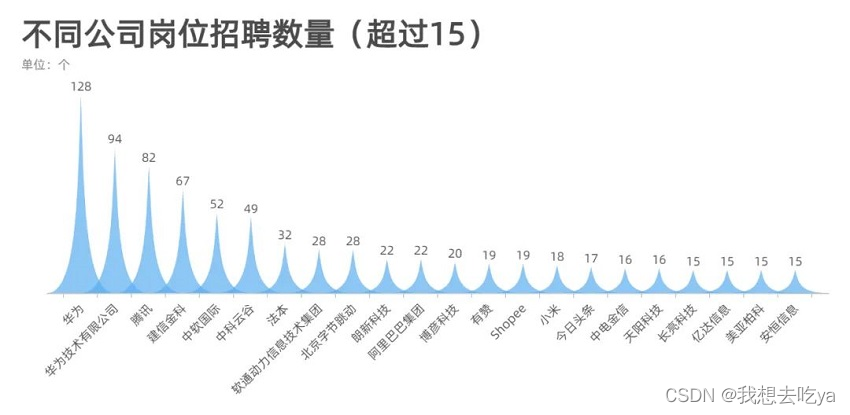
那么这些岗位都需要什么技能呢?Spark,Hadoop,数据仓库,Python,SQL,Mapreduce,Hbase等等

根据国内的发展形势,大数据未来的发展前景会非常好。自 2018 年企业纷纷开始数字化转型,一二线城市对大数据领域的人才需求非常强烈,未来几年,三四线城市的人才需求也会大增。
在大数据领域,国内发展的比较晚,从 2016 年开始,仅有 200 多所大学开设了大数据相关的专业,也就是说 2020 年第一批毕业生才刚刚步入社会,我国市场环境处于急需大数据人才但人才不足的阶段,所以未来大数据领域会有很多的就业机遇。
薪资高、缺口大,自然成为职场人的“薪”选择!
任何学习过程都需要一个科学合理的学习路线,才能够有条不紊的完成我们的学习目标。Python+大数据所需学习的内容纷繁复杂,难度较大,为大家整理了一个全面的Python+大数据学习路线图,帮大家理清思路,攻破难关!
Python+大数据学习路线图详细介绍
第一阶段 大数据开发入门
学前导读:从传统关系型数据库入手,掌握数据迁移工具、BI数据可视化工具、SQL,对后续学习打下坚实基础。
1.大数据数据开发基础MySQL8.0从入门到精通
MySQL是整个IT基础课程,SQL贯穿整个IT人生,俗话说,SQL写的好,工作随便找。本课程从零到高阶全面讲解MySQL8.0,学习本课程之后可以具备基本开发所需的SQL水平。
2022最新MySQL知识精讲+mysql实战案例_零基础mysql数据库入门到高级全套教程
第二阶段 大数据核心基础
学前导读:学习Linux、Hadoop、Hive,掌握大数据基础技术。
2022版大数据Hadoop入门教程
Hadoop离线是大数据生态圈的核心与基石,是整个大数据开发的入门,是为后期的Spark、Flink打下坚实基础的课程。掌握课程三部分内容:Linux、Hadoop、Hive,就可以独立的基于数据仓库实现离线数据分析的可视化报表开发。
2022最新大数据Hadoop入门视频教程,最适合零基础自学的大数据Hadoop教程
第三阶段 千亿级数仓技术
学前导读:本阶段课程以真实项目为驱动,学习离线数仓技术。
数据离线数据仓库,企业级在线教育项目实战(Hive数仓项目完整流程)
本课程会、建立集团数据仓库,统一集团数据中心,把分散的业务数据集中存储和处理 ;目从需求调研、设计、版本控制、研发、测试到落地上线,涵盖了项目的完整工序 ;掘分析海量用户行为数据,定制多维数据集合,形成数据集市,供各个场景主题使用。
大数据项目实战教程_大数据企业级离线数据仓库,在线教育项目实战(Hive数仓项目完整流程)
第四阶段 PB内存计算
学前导读:Spark官方已经在自己首页中将Python作为第一语言,在3.2版本的更新中,高亮提示内置捆绑Pandas;课程完全顺应技术社区和招聘岗位需求的趋势,全网首家加入Python on Spark的内容。
1.python入门到精通(19天全)
python基础学习课程,从搭建环境。判断语句,再到基础的数据类型,之后对函数进行学习掌握,熟悉文件操作,初步构建面向对象的编程思想,最后以一个案例带领同学进入python的编程殿堂。
全套Python教程_Python基础入门视频教程,零基础小白自学Python必备教程
2.python编程进阶从零到搭建网站
学完本课程会掌握Python高级语法、多任务编程以及网络编程。
Python高级语法进阶教程_python多任务及网络编程,从零搭建网站全套教程
3.spark3.2从基础到精通
Spark是大数据体系的明星产品,是一款高性能的分布式内存迭代计算框架,可以处理海量规模的数据。本课程基于Python语言学习Spark3.2开发,课程的讲解注重理论联系实际,高效快捷,深入浅出,让初学者也能快速掌握。让有经验的工程师也能有所收获。
Spark全套视频教程,大数据spark3.2从基础到精通,全网首套基于Python语言的spark教程
4.大数据Hive+Spark离线数仓工业项目实战
通过大数据技术架构,解决工业物联网制造行业的数据存储和分析、可视化、个性化推荐问题。一站制造项目主要基于Hive数仓分层来存储各个业务指标数据,基于sparkSQL做数据分析。核心业务涉及运营商、呼叫中心、工单、油站、仓储物料。
全网首次披露大数据Spark离线数仓工业项目实战,Hive+Spark构建企业级大数据平台
![[Java反序列化]—Shiro反序列化(二)](https://img-blog.csdnimg.cn/ecee47959ecd4808bcb006a6c30fc981.png)






![[思考进阶]02 如何进行认知升级?](https://img-blog.csdnimg.cn/5f36ccd62eb9467c85e63a4d18f9336b.png#pic_center)