目录
数据准备
1、查询指定字段包含指定内容的文档
2、指定输出的文档字段查询(“_source”)
3、排序查询(默认根据指定字段升序asc排序)(“sort”)
4、分页查询
5、布尔查询(多条件查询)
6、数据过滤(“filter”)
7、精确查询(term)
8、两个类型text和keyword
9、高亮查询(“highlight”)
10、自定义高亮标签
elasticsearch查询操作大致可分为以下几种(这些操作MySQL也可以做,但是在大数据量的情况下有可能会出现效率较慢的情况)而elasticsearch可以说是解决这种问题的灵丹妙药,为查询而生,特别是大数据量的模糊查询
匹配查询 match
按照条件查询 (must、must_not、should)
精确查询 (term)
区间范围查询(filer ->range)
匹配字段查询
多条件查询(布尔查询)
高亮查询 (highlight)
数据准备
使用kibana执行操作,将数据保存在elasticsearch中
PUT /book/_doc/1
{
"name":"数据结构",
"desc":"基础学习数据结构与算法",
"price":15
}
PUT /book/_doc/2
{
"name":"Java",
"desc":"这是一本java基础学习",
"price":40
}
PUT /book/_doc/3
{
"name":"Linux",
"desc":"服务器命令操作",
"price":35
}
PUT /book/_doc/4
{
"name":"c语言",
"desc":"入门教程",
"price":20
}查看索引详细信息,es帮着我们自动推断并设置了字段类型
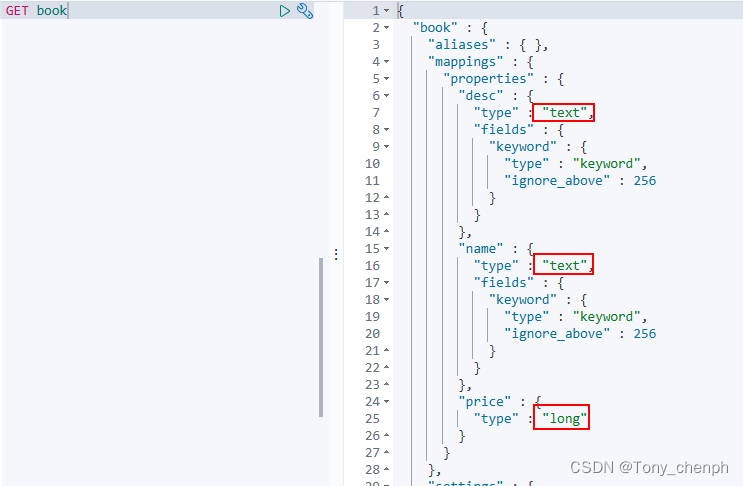

在使用kabina时,输入关键字kibina会有提示,点击enter即可帮助我们自动补全API命令,但是注意如果输入了”_doc”则没有了提示
1、查询指定字段包含指定内容的文档
查询文档中name包含数据的文档记录
第一种方式GET book/_doc/_search?q=name:数据
第二种方式
GET book/_doc/_search
{
"query": {
"match":{
"name": "数据"
}
}
}
2、指定输出的文档字段查询(“_source”)
查询文档中name包含数据的文档记录,并只要查出文档记录的name和desc
GET book/_doc/_search
{
"query": {
"match":{
"name": "数据"
}
},
"_source":["name","desc"]
}
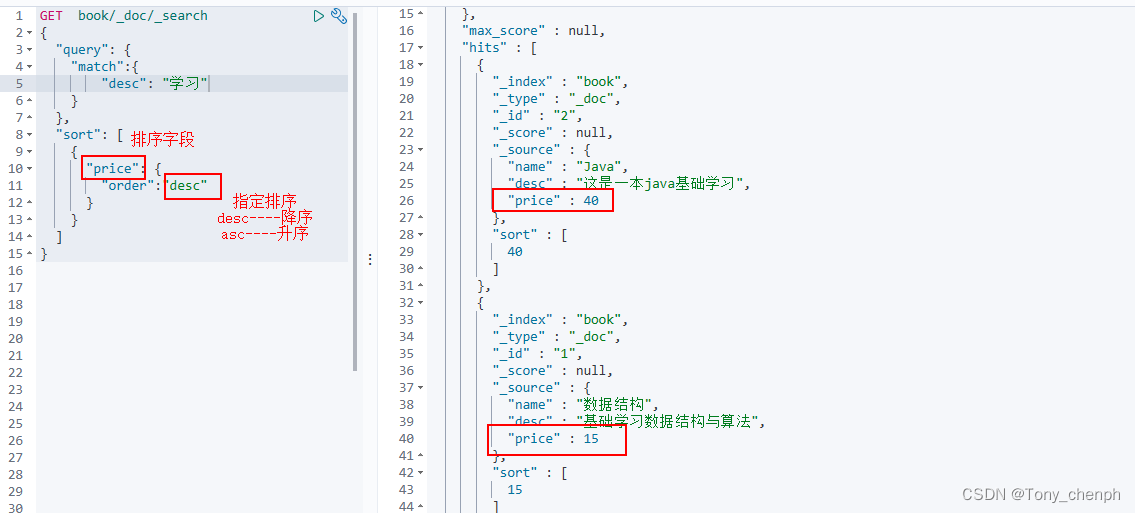
3、排序查询(默认根据指定字段升序asc排序)(“sort”)
查询desc包含学习的文档并根据价格排序
GET book/_doc/_search
{
"query": {
"match":{
"desc": "学习"
}
},
"sort": [
{
"price": {
"order":"desc"
}
}
]
}
4、分页查询
查询desc包含学习的文档,只要第一页的第一条
GET book/_doc/_search
{
"query": {
"match":{
"desc": "学习"
}
},
"sort": [
{
"price": {
"order":"desc"
}
}
],
"from": 0,
"size":1
}
数据下标还是从0开始的
5、布尔查询(多条件查询)
查询文档中desc包含学习且name包含数据的记录
must(and),所有条件都要match到才可以查询出来
GET book/_doc/_search
{
"query": {
"bool":{
"must": [
{
"match": {
"desc": "学习"
}
},
{
"match": {
"name": "数据"
}
}
]
}
}
}
相当于select * from book where desc=”学习” and name=”数据”;
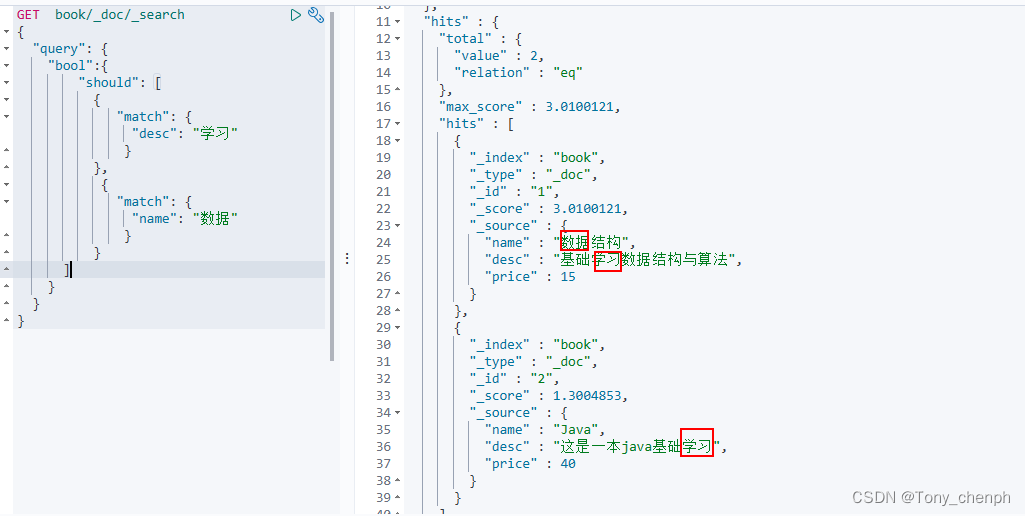
should(or),只要match到其中一个条件即可查询出来
GET book/_doc/_search
{
"query": {
"bool":{
"should": [
{
"match": {
"desc": "学习"
}
},
{
"match": {
"name": "数据"
}
}
]
}
}
}
must_not(or),只要match到其中一个条件,文档记录都不会查询出来
GET book/_doc/_search
{
"query": {
"bool":{
"must_not": [
{
"match": {
"desc": "学习"
}
},
{
"match": {
"name": "数据"
}
}
]
}
}
}
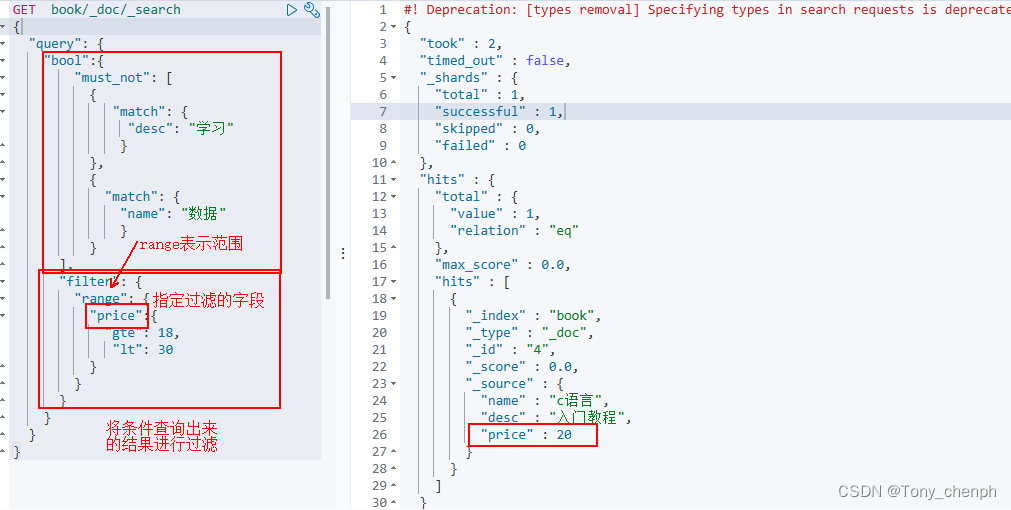
6、数据过滤(“filter”)
查询出desc不包含学习,name不包含数据的,价格大于等于18且小于30([18,30))的文档记录
GET book/_doc/_search
{
"query": {
"bool":{
"must_not": [
{
"match": {
"desc": "学习"
}
},
{
"match": {
"name": "数据"
}
}
],
"filter": {
"range": {
"price":{
"gte": 18,
"lt": 30
}
}
}
}
}
}
| gte(greater than equal) | 大于等于 |
| gt(greater than ) | 大于 |
| lte(less than equal) | 小于等于 |
| lt(less than ) | 小于 |
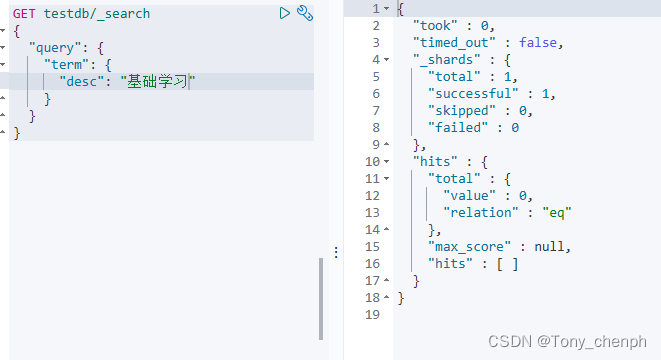
7、精确查询(term)
term查询是直接根据倒排索引指定的词条进行精确查询的
match会使用分词器解析,先分析文档,然后再通过分析的文档进行模糊查询
效率:term>match
term不会对查询条件进行分词
keyword不会对存储的数据进行分词
GET book/_doc/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"price": {
"value": 20
}
}
},
{
"term": {
"price": {
"value": 15
}
}
}
]
}
}
}
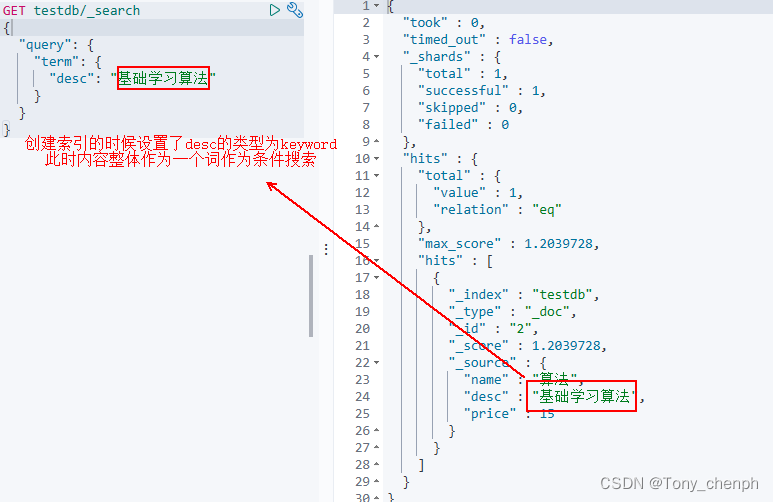
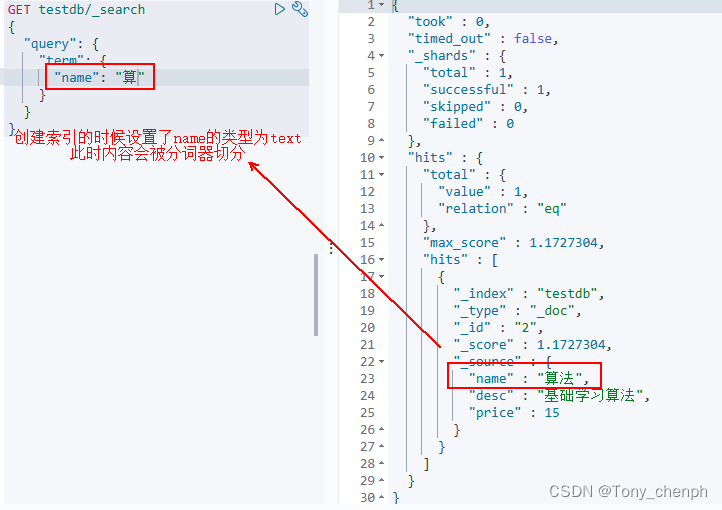
8、两个类型text和keyword
text:内容会被分词器解析
keyword: 内容不会被分词器解析,整体作为一个关键词
使用keyword作为analyzer,执行结果

text内容整体作为一个关键词解析出来,不会被分词器拆开
使用standard作为analyzer
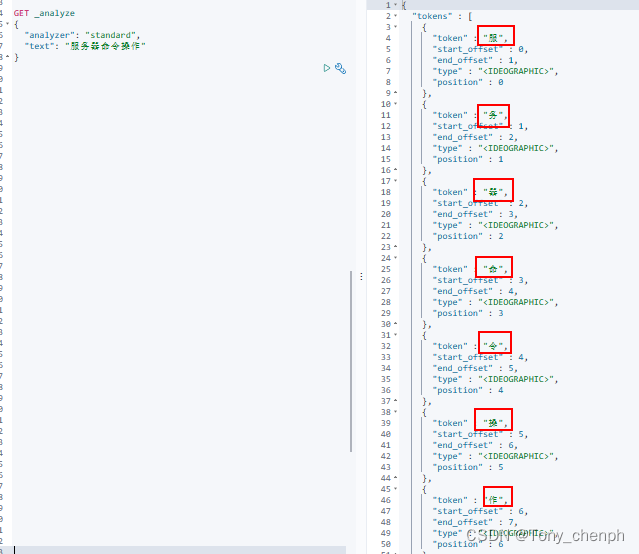
则会使用分词器将每个文字作为一个词解析出来
创建索引测试两个类型的区别
PUT testdb
{
"mappings": {
"properties": {
"name":{
"type" :"text"
},
"desc":{
"type": "keyword"
}
}
}
}
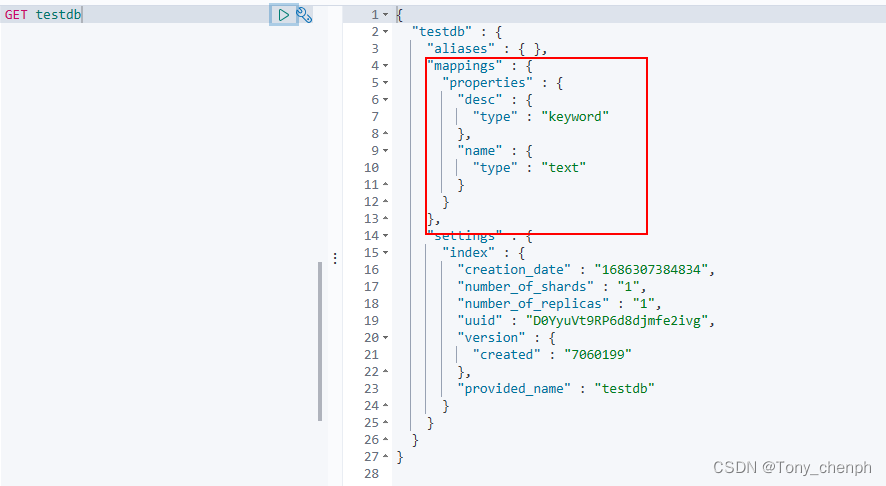
同样把数据录入到elasticsearch中
PUT /testdb/_doc/1
{
"name":"数据结构",
"desc":"基础学习数据结构与算法",
"price":15
}
PUT /testdb/_doc/2
{
"name":"数据结构",
"desc":"基础学习数据结构与算法2",
"price":15
}
9、高亮查询(“highlight”)
GET book/_search
{
"query": {
"match": {
"name": "数据"
}
},
"highlight": {
"fields": {
"name": {}
}
}
}
默认把搜索条件匹配到的每个字加上<em>标签
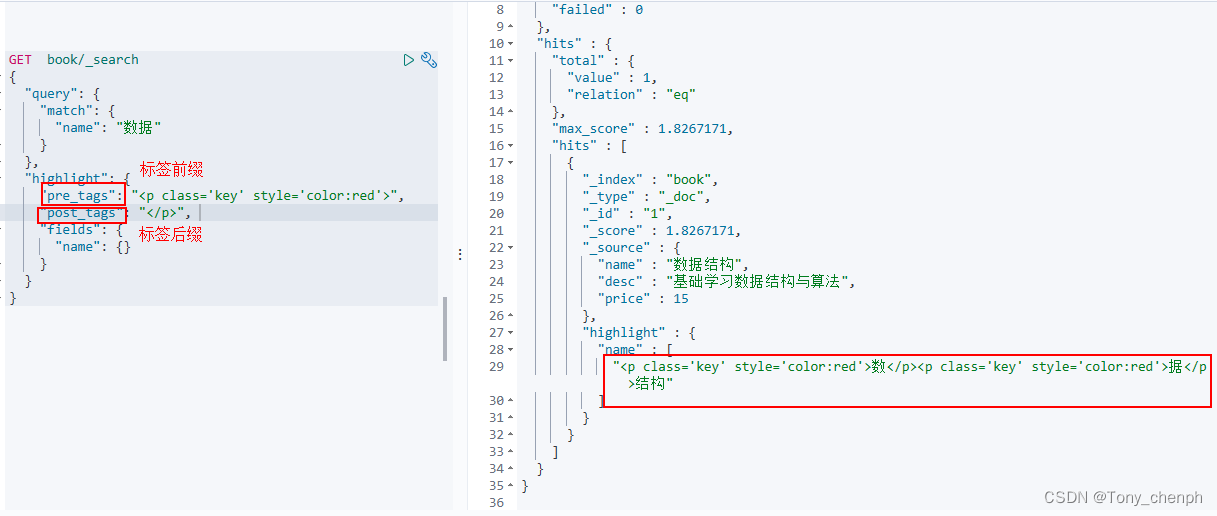
10、自定义高亮标签
"pre_tags":定义标签前缀
"post_tags": 定义标签后缀
例如
GET book/_search
{
"query": {
"match": {
"name": "数据"
}
},
"highlight": {
"pre_tags": "<p class='key' style='color:red'>",
"post_tags": "</p>",
"fields": {
"name": {}
}
}
}