前提是需要联网
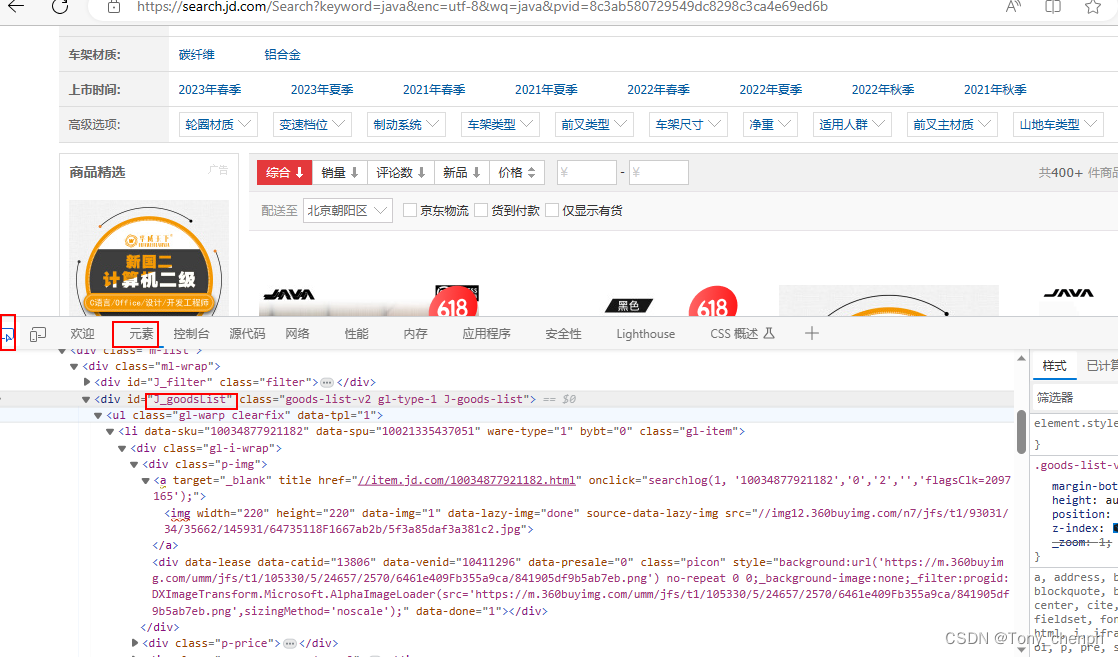
F12打开浏览器控制台,通过元素找到需要爬取的数据
1、添加网页解析依赖
<!--解析网页依赖-->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.10.2</version>
</dependency>2、编写工具类
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.IOException;
import java.net.URL;
public class HtmlParseUtil {
public static void main(String[] args) throws IOException {
search("java");
}
public static void search(String name) throws IOException {
//获取请求 https://search.jd.com/Search?keyword=java
String url = "https://search.jd.com/Search?keyword=" + name;
//解析网页(Jsoup返回的Document就是浏览器的document对象)
Document parse = Jsoup.parse(new URL(url), 30000);
//所有可以在js中使用的方法都可以通过parse.xxx()使用
Element j_goodsList = parse.getElementById("J_goodsList");
//输出获取的元素以html语言展示
// System.out.println(j_goodsList.html());
//获取所有的li元素
Elements li_list = j_goodsList.getElementsByTag("li");
//获取元素中的内容,这里的li就是每一个li标签的内容
for (Element li : li_list) {
String img = li.getElementsByTag("img").eq(0).attr("data-lazy-img");
String price = li.getElementsByClass("p-price").eq(0).text();
String shop = li.getElementsByClass("p-shop").eq(0).text();
String title = li.getElementsByClass("p-name").eq(0).text();
//创建一个实体类接收爬取出来的参数
System.out.println("img=" + img);
System.out.println("price=" + price);
System.out.println("shop=" + shop);
System.out.println("title=" + title);
System.out.println("======================================");
}
//将对象返回
// return xxx;
}
}