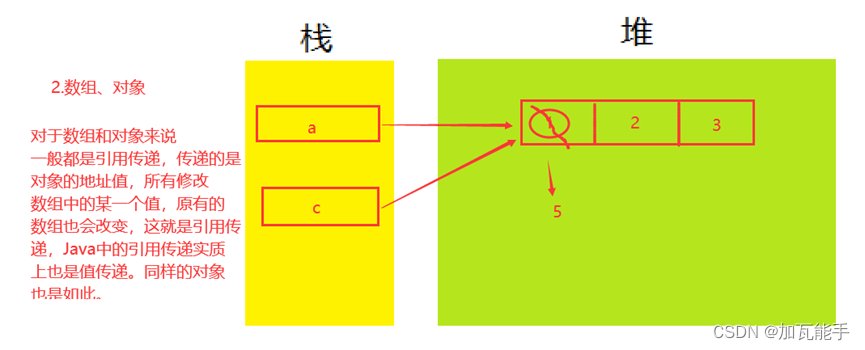
先来看看dict的大致结构:
debug所用demo如下:
void testDict();
int main(int argc, char **argv) {
testDict();
}
void testDict(){
dict *dict0 = dictCreate(&hashDictType, NULL);
//注意key要用sds,如果是普通字符串,长度会判为0,然后所有的key比对都是异常的
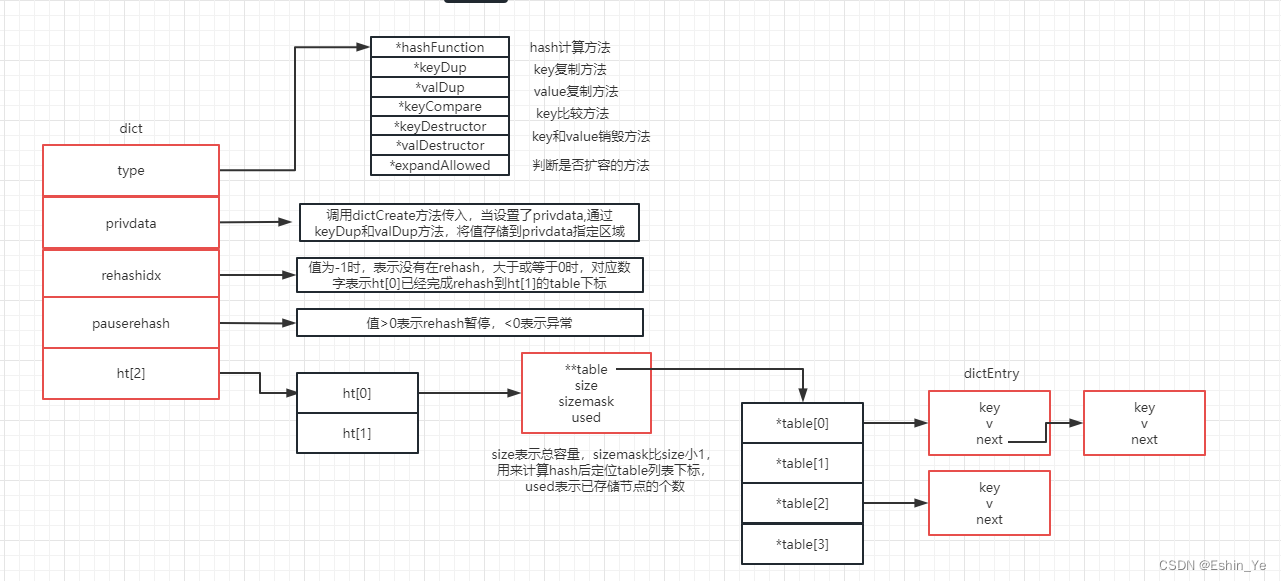
dictAdd(dict0,sdsnew("0001a"),"value");
dictAdd(dict0,sdsnew("0001aa"),"value");
dictAdd(dict0,sdsnew("0002a"),"value");
dictAdd(dict0,sdsnew("0003a"),"value");
dictAdd(dict0,sdsnew("0004a"),"value");
dictAdd(dict0,sdsnew("0005a"),"value");
dictAdd(dict0,sdsnew("0006a"),"value");
dictAdd(dict0,sdsnew("0007a"),"value");
dictAdd(dict0,sdsnew("0008a"),"value");
}
主要数据结构如下:
//整体的dict结构,可参考开头的图
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];//包含两个,ht[1]在扩容rehash时使用
long rehashidx; //值为-1,表示没有rehash,>=0时,表示已经rehash的table下标
int16_t pauserehash;//
} dict;
//dict中ht[2]中元素的结构
typedef struct dictht {
dictEntry **table;//table数组,每个table是一个链表,链表由若干dictEntry组成
unsigned long size;//table数组大小
unsigned long sizemask;//用来计算下标的掩码
unsigned long used;//已经存储的元素dictEntry个数
} dictht;
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;//这个联合体中的这几个字段不知干嘛用的
int64_t s64;
double d;
} v;
struct dictEntry *next;
}
dictEntry;
一、先来看下dicticreate()

二、添加元素dictAdd()
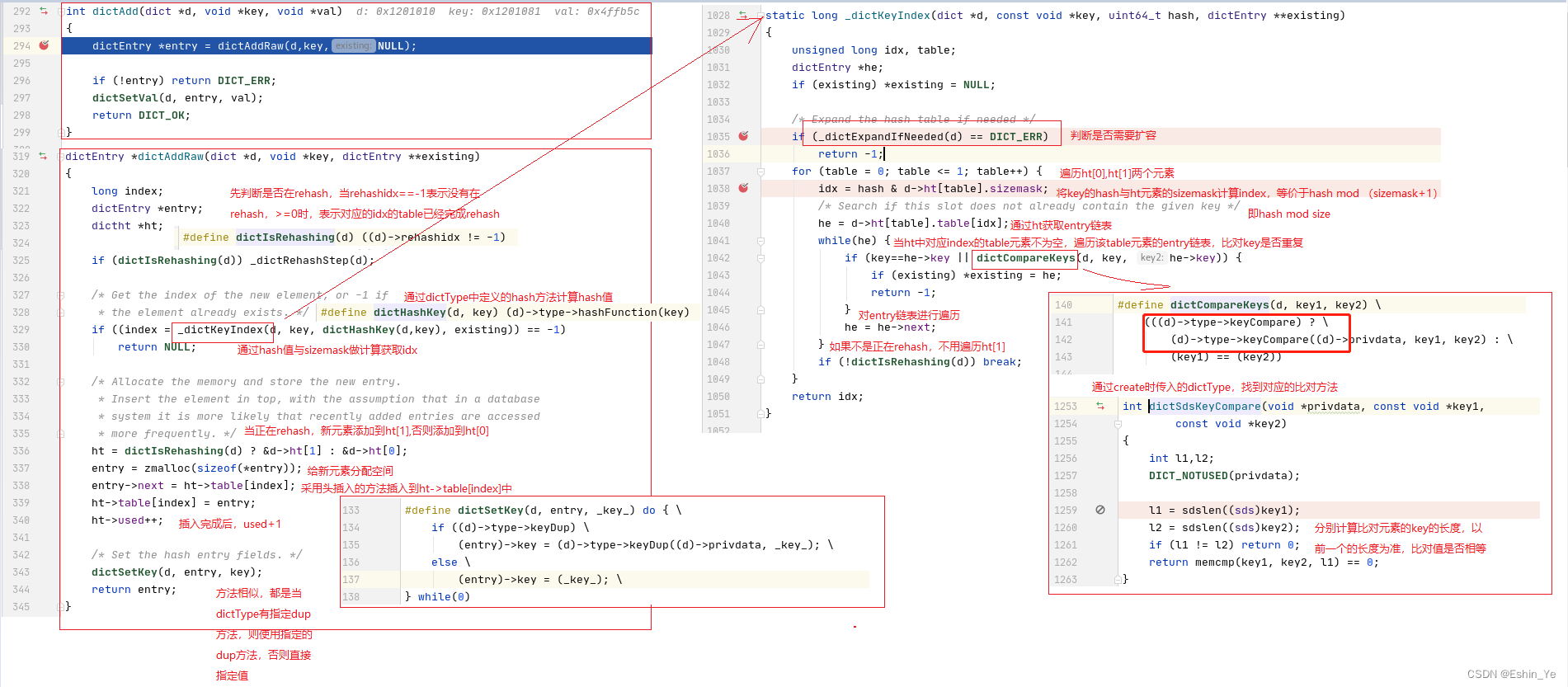
三、扩容_dictExpandIfNeeded()
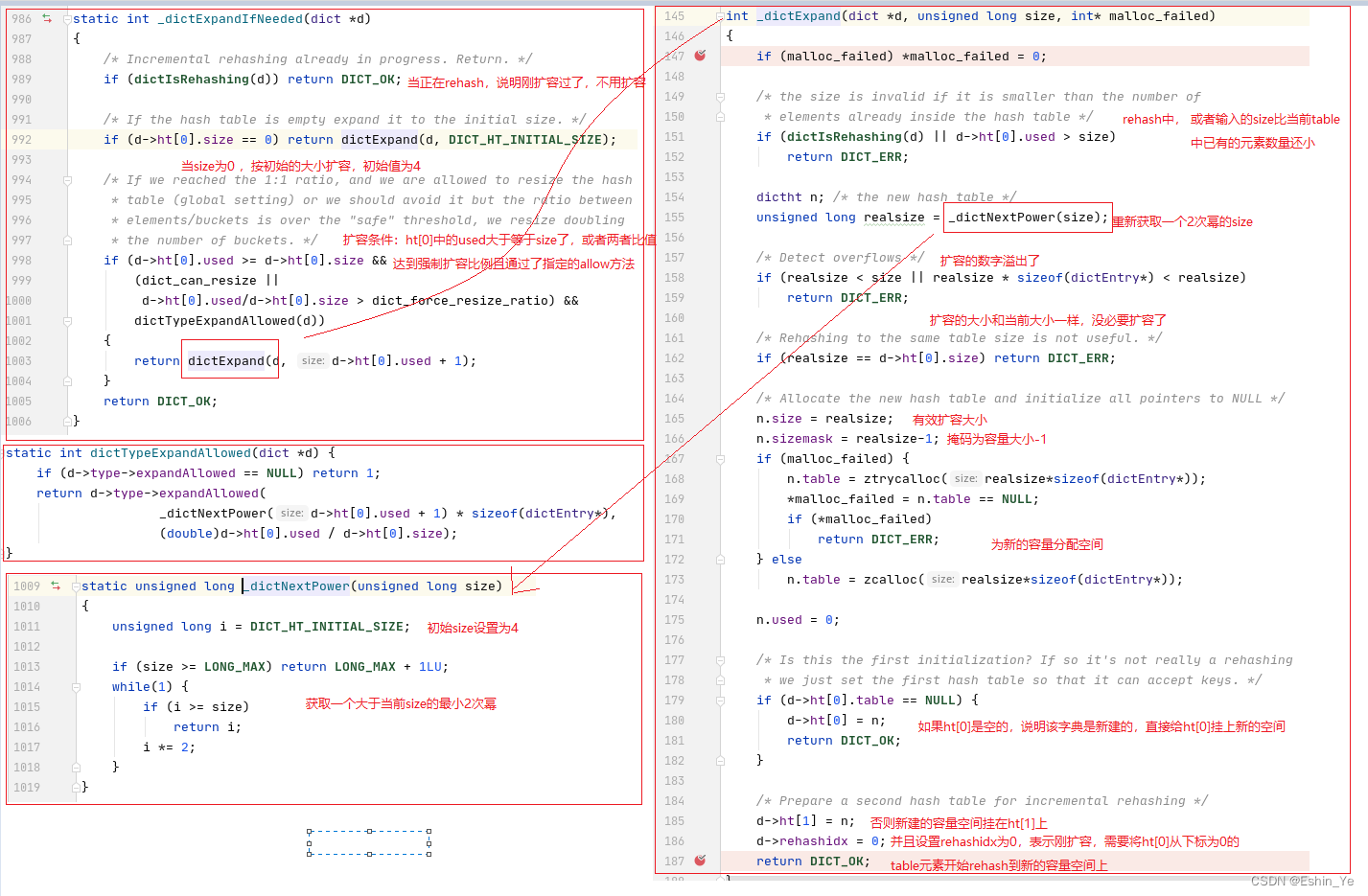
四、rehash
在完成扩容后,并不是一下子就把原来ht[0]中每个table的链都直接迁移到新的扩容空间,而是通过一种渐进的方式,在下一次新增元素、或者查询、删除时,在方法一开始先进行一次rehash操作主键将ht[0]中的每个table链rehash,一次只处理一个下标的table链。
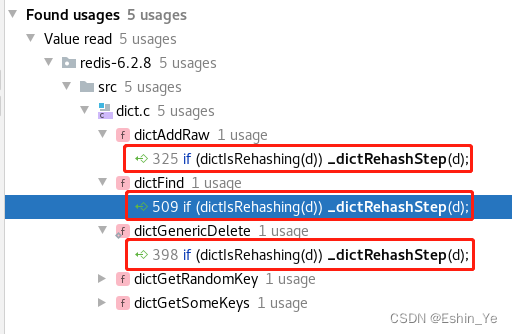

大致流程如下:
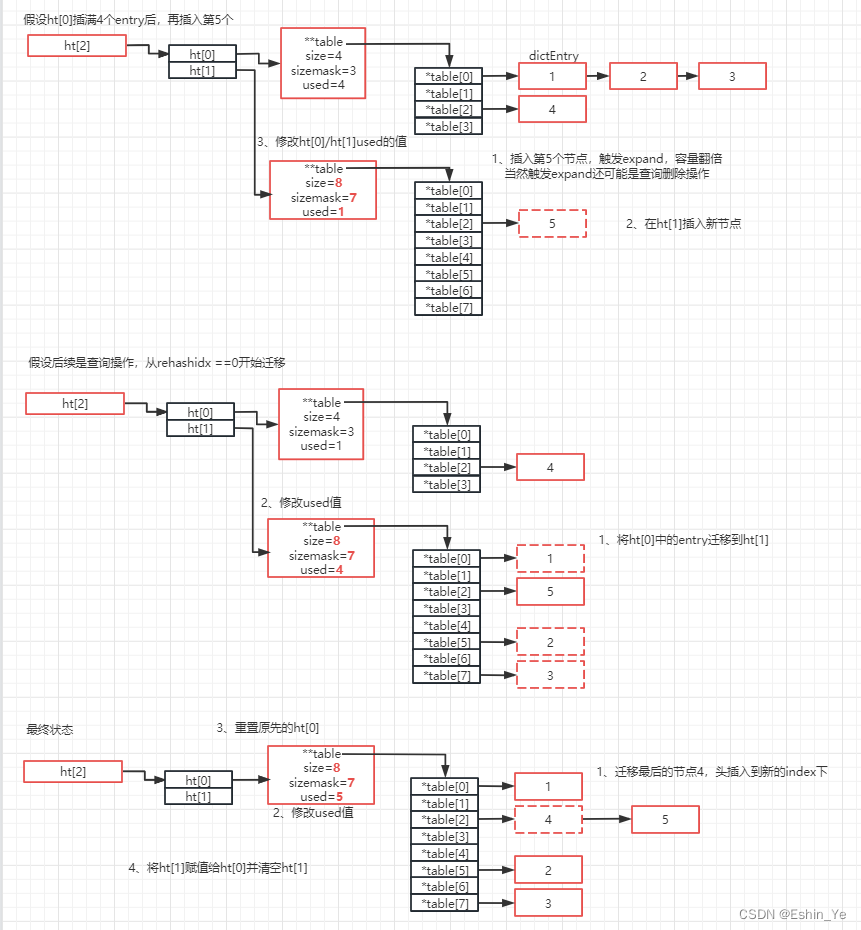
总体上,redis的字典,逻辑比java的hashmap还是简单很多的。