线程安全
多线程程序处于一个多变的环境当中,可访问的全局变量和堆数据随时都可能被其他的线程改变。因此多线程程序在并发时数据的一致性变得非常重要。
竞争和原子操作
多个线程同时访问一个共享数据,可能造成很恶劣的后果。下面是一个著名的例子,假设有两个线程分别要执行如图所示的C代码:

在很多体系结构上,++i的实现方法如下:
1.读取i到某个寄存器X;
2.X++;
3.将X的内容存储回i。
由于线程1和线程2并发执行,因此两个线程的执行序列很可能如下(注意,寄存器X的内容在不同的线程中是不一样的,这里用x[1]和x[2] 分别表示线程1和线程2中的X),如图所示:
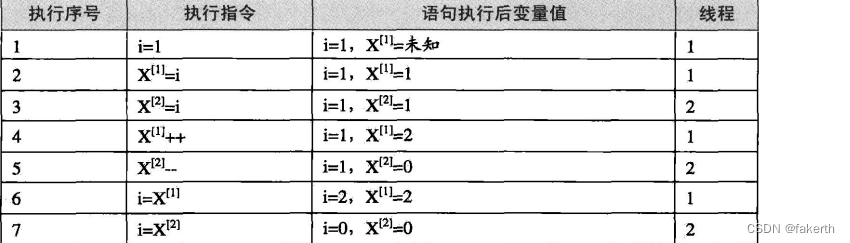
从程序逻辑来看,两个线程都执行完毕之后,i的值应该为1,但从之前的执行序列可以看到,i得到的值是0。实际上这两个线程如果同时执行的话,i的结果有可能是0或1或2。可见,两个程序同时读写同一个共享数据会导致意想不到的后果。
很明显,自增(++)操作在多线程环境下会出现错误是因为这个操作被编译为汇编代码之后不止一条指令,因此在执行的时候可能执行了一半就被调度系统打断,去执行别的代码。我们把单指令的操作称为原子的(Atomic),因为无论如何,单条指令的执行是不会被打断的。为了避免出错,很多体系结构都提供了一些常用操作的原子指令,例如 i386就有条inc指令可以直接增加一个内存单元值,可以避免出现上例中的错误情况。在 Windows里,有一套API专门进行一些原子操作如图所示,这些API称为Interlocked API。

使用这些函数时,Windows将保证是原子操作的,因此可以不用担心出现问题。遗憾的是,尽管原子操作指令非常方便,但是它们仅适用于比较简单特定的场合。在复杂的场合下,比如我们要保证一个复杂的数据结构更改的原子性,原子操作指令就力不从心了。这里我们需要更加通用的手段:锁。
同步与锁
为了避免多个线程同时读写同一个数据而产生不可预料的后果,我们需要将各个线程对同一个数据的访问同步(Synchronization)。所谓同步,既是指在一个线程访问数据未结束的时候,其他线程不得对同一个数据进行访问。如此,对数据的访问被原子化了。
同步的最常见方法是使用锁(Lock)。锁是一种非强制机制,每一个线程在访问数据或资源之前首先试图获取(Acquire) 锁,并在访问结束之后释放(Release) 锁。在锁已经被占用的时候试图获取锁时,线程会等待,直到锁重新可用。
二元信号量(Binary Semaphore) 是最简单的一种锁,它只有两种状态:占用与非占用。它适合只能被唯一一个线程独占访问的资源。当二元信号量处于非占用状态时,第一个试图获取该二元信号量的线程会获得该锁,并将二元信号量置为占用状态,此后其他的所有试图获取该二元信号量的线程将会等待,直到该锁被释放。
对于允许多个线程并发访问的资源,多元信号量简称信号量(Semaphore),它是一个很好的选择。一个初始值为N的信号量允许N个线程并发访问。线程访问资源的时候首先获取信号量,进行如下操作:
1.将信号量减1;
2.如果信号量的值小于0,则进入等待状态,否则继续执行。
访问完资源之后,线程释放信号量,进行如下操作:
1.将信号量的值加1;
2.如果信号量的值大于0,唤醒一个等待中的线程。
互斥量(Mutex) 和二元信号量很类似,资源仅同时允许一个线程访问,但和信号量不同的是,信号量在整个系统可以被任意线程获取并释放,也就是说,同一个信号量可以被系统中的一个线程获取之后由另一个线程释放。而互斥量则要求哪个线程获取了互斥量,哪个线程就要负责释放这个锁,其他线程越俎代庖去释放互斥量是无效的。
临界区(Critical Section) 是比互斥量更加严格的同步手段。在术语中,把临界区的锁的获取称为进入临界区,而把锁的释放称为离开临界区。临界区和互斥量与信号量的区别在于,互斥量和信号量在系统的任何进程里都是可见的,也就是说,一个进程创建了一个互斥量或信号量,另一个进程试图去获取该锁是合法的。然而,临界区的作用范围仅限于本进程,其他的进程无法获取该锁。除此之外,临界区具有和互斥量相同的性质。
读写锁(Read-Write Lock) 致力于一种更加特定的场合的同步。对于一段数据,多个线程同时读取总是没有问题的,但假设操作都不是原子型,只要有任何一个线程试图对这个数据进行修改,就必须使用同步手段来避免出错。如果我们使用上述信号量、互斥量或临界区中的任何一种来进行同步,尽管可以保证程序正确,但对于读取频繁,而仅仅偶尔写入的情况,会显得非常低效。读写锁可以避免这个问题。对于同一个锁,读写锁有两种获取方式,共享的(Shared) 或独占的(Exclusive)。当锁处于自由的状态时,试图以任何一种方式获取锁都能成功,并将锁置于对应的状态。如果锁处于共享状态,其他线程以共享的方式获取锁仍然会成功,此时这个锁分配给了多个线程。然而,如果其他线程试图以独占的方式获取已经处于共享状态的锁,那么它将必须等待锁被所有的线程释放。相应地,处于独占状态的锁将阻止任何其他线程获取该锁,不论它们试图以哪种方式获取。读写锁的行为可以总结如图所示:

条件变量(Condition Variable) 作为一种同步手段,作用类似于一个栅栏。对于条件变量,线程可以有两种操作,首先线程可以等待条件变量,一个条件变量可以被多个线程等待。其次,线程可以唤醒条件变量,此时某个或所有等待此条件变量的线程都会被唤醒并继续支持。也就是说,使用条件变量可以让许多线程一起等待某个事件的发生,当事件发生时(条件变量被唤醒),所有的线程可以一起恢复执行。
可重入(Reentrant)与线程安全
一个函数被重入,表示这个函数没有执行完成,由于外部因素或内部调用,又一次进入该函数执行。一个函数要被重入,只有两种情况:
1.多个线程同时执行这个函数。
2.函数自身(可能是经过多层调用之后)调用自身。
一个函数被称为可重入的,表明该函数被重入之后不会产生任何不良后果。举个例子,如下面这个sqr函数就是可重入的:
int sqr(int x)
{
return x * x;
}
一个函数要成为可重入的,必须具有如下几个特点:
1.不适用任何(局部)静态或全局的非const变量。
2.不返回任何(局部)静态或全局的非const变量。
3.仅依赖于调用方提供的参数。
4.不依赖任何单个资源的锁(mutex等)。
5.不调用任何不可重入的函数。
可重入是并发安全的强力保障,一个可重入的函数可以在多线程环境下放心使用。
过度优化
线程安全是一个非常烫手的山芋,因为即使合理地使用了锁,也不一定能保证线程安全,这是源于落后的编译器技术已经无法满足日益增长的并发需求。很多看似无错的代码在优化和并发面前又产生了麻烦。最简单的例子,让我们看看如下代码:
x=0
Thread1 Thread2
lock(); lock();
x++; x++;
unlock(); unlock();
由于有lock和unlock的保护,x++的行为不会被并发所破坏,那么x的值似乎必然是2了。然而,如果编译器为了提高x的访问速度,把x放到了某个寄存器里,那么我们知道不同线程的寄存器是各自独立的,因此如果Thread1先获得锁,则程序的执行可能会呈现如下的情况:
[Thread1]读取x的值到某个寄存器R[1](R[1]=0)
[Thread1]R[1]++(由于之后可能还要访问x,因此Thread1暂时不将R[1]写回x)
[Thread2]读取x的值到某个寄存器R[2](R[2]=0)
[Thread2]R[2]++(R[2]=1)
[Thread2]将R[2]写回至x(x=1)
[Thread1](很久以后)将R[1]写回至x(x=1)
可见在这样的情况下即使正确地加锁,也不能保证多线程安全。下面是一个例子:
x = y = 0;
Thread1 Thread2
x = 1; y = 1;
r1 = y; r2 = x;
很显然,r1和r2至少有一个为1,逻辑上不可能同时为0。然而,事实上r1=r2=0的情况确实可能发生。原因在于早在几十年前,CPU就发展出了动态调度,在执行程序的时候为了提高效率有可能交换指令的顺序。同样,编译器在进行优化的时候,也可能为了效率而交换毫不相干的两条相邻指令(如x=1和r1=y)的执行顺序。也就是说,以上代码执行的时候可能是这样的:
x = y = 0;
Thread1 Thread2
r1 = y; y = 1;
x = 1; r2 = x;
那么r1=r2=0就完全可能了。我们可以使用volatile关键字试图阻止过度优化,volatile基本可以做到两件事情:
1.阻止编译器为了提高速度将一个变量缓存到寄存器内而不写回。
2.阻止编译器调整操作volatile变量的指令顺序。
可见volatile可以完美地解决第一个问题,但是volatile是否也能解决第二个问题呢?答案是不能。因为即使volatile能够阻止编译器调整顺序,也无法阻止CPU动态调度换序。
另一个颇为著名的与换序有关的问题来自于Singleton模式的double-check。一段典型的double-check 的singleton 代码是这样的:
volatile T* pInst = 0;
T* GetInstance()
{
if(pInst == NULL)
{
lock();
if(pInst == NULL)
PInst = new T;
unlock();
}
return pInst;
}
抛开逻辑,这样的代码乍看是没有问题的,当函数返回时,PInst总是指向一个有效的对象。而lock和 unlock 防止了多线程竞争导致的麻烦。双重的if在这里另有妙用,可以让lock的调用开销降低到最小。我们可以自己揣摩。
但是实际上这样的代码是有问题的。问题的来源仍然是CPU的乱序执行。C++里的new其实包含了两个步骤:
1.分配内存;
2.调用构造参数。
所以pInst = new T包含了三个步骤:
1.分配内存;
2.在内存的位置上调用构造参数;
3.将内存的地址赋给pInst。
在这三步中,2和3的顺序是可以颠倒的。也就是说,完全有可能出现这样的情况:pInst 的值已经不是NULL,但对象仍然没有构造完毕。这时候如果出现另外一个对GetInstance的并发调用,此时第一个if 内的表达式pInst==NULL为false,所以这个调用会直接返回尚未构造完全的对象的地址(pInst)以提供给用户使用。那么程序这个时候会不会崩溃就取决于这个类的设计如何了。
从上面两个例子可以看到CPU的乱序执行能力让我们对多线程的安全保障的努力变得异常困难。因此要保证线程安全,阻止 CPU 换序是必需的。遗憾的是,现在并不存在可移植的阻止换序的方法。通常情况下是调用CPU提供的一条指令,这条指令常常被称为barrier。一条barrier 指令会阻止CPU将该指令之前的指令交换到barrier之后,反之亦然。换句话说,barrier指令的作用类似于一个拦水坝,阻止换序“穿透”这个大坝。
许多体系结构的CPU都提供 barrier指令,不过它们的名称各不相同,例如POWERPC提供的其中一条指令名叫1wsync。我们可以这样来保证线程安全:
#define barrier() _asm_ volatile ("lwsync")
volatile T* pInst = 0;
T* GetInstance()
{
if(!pInst)
{
lock();
if(!pInst)
{
T* temp = new T;
barrier();
PInst = temp;
}
unlock();
}
return pInst;
}
由于barrier的存在,对象的构造一定在barrier执行之前完成,因此当pInst被赋值时,对象总是完好的。