1. 图的定义
树形结构用于描述节点和节点之间的层次关系,而图形结构用于描述两个顶点之间是否连通的关系。在计算机科学中,图形结构是最灵活的数据结构之一,很多问题都可以使用图来求解。
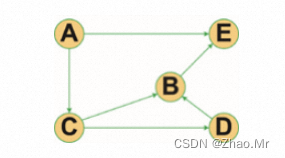
无向图是每条边都没有方向的图,同一个边的两个顶点没有次序关系。例如,(V1,V2)和(V2,V1)表示的是相同的边。

有向图是每条边都有方向的图,同一个边的两个顶点有次序关系。图中的每一条边都可以使用有序对<V1,V2>来表示。<V1,V2>是指从顶点V1指向顶点V2的一条边,V1表示尾部,而V2表示头部。因此<V1,V2>和<V2,V1>表示不同的两条边。
图的相关术语:
2. 图的遍历
图的遍历是指从图中的某个顶点(该顶点也可称为起始点)出发,按照某个特定的方式访问图中的各个顶点,使每个可访问到的顶点都被访问一次。图的遍历方式有两种,一种是深度优先遍历(也叫作深度优先搜索,简称为DFS),还有一种是广度优先遍历(也叫作广度优先搜索,简称为BFS)。
说明:起始点可以任意指定,起始点不同得到的遍历序列也不相同。
注意:在遍历时,每个顶点只能访问一次,不可重复访问。
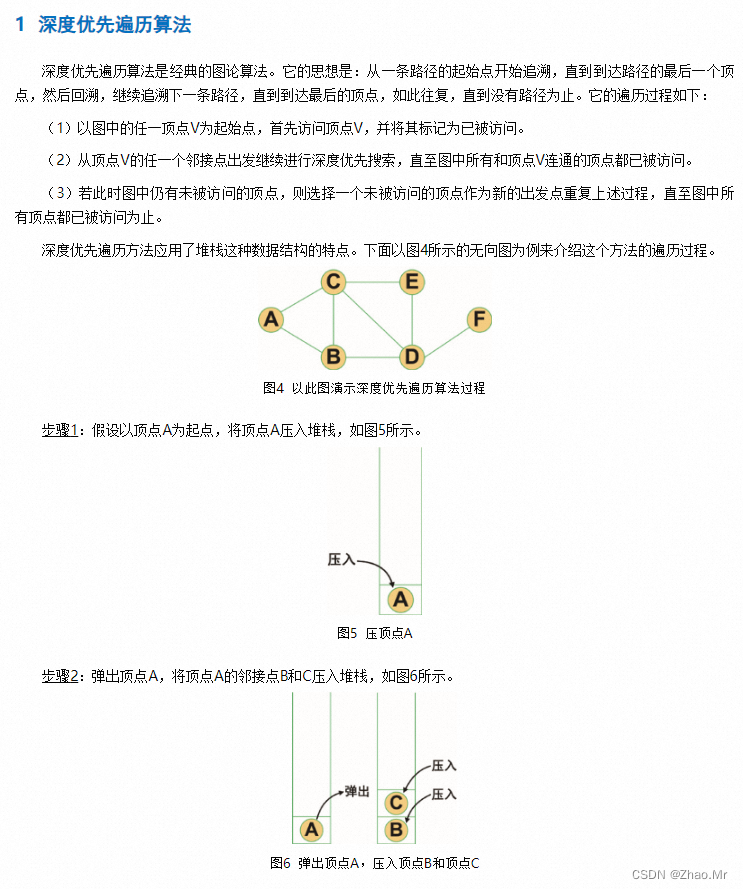


在该例中应用的深度优先遍历算法,代码如下:
def dfs(graph, start):
stack = [] # 定义堆栈
stack.append(start) # 将起始顶点压入堆栈
visited = set() # 定义集合
while stack:
vertex = stack.pop() # 弹出栈顶元素
if vertex not in visited: # 如果该顶点未被访问过
visited.add(vertex) # 将该顶点放入已访问集合
print(vertex,end = ' ') # 打印深度优先遍历的顶点
for w in graph[vertex]: # 遍历相邻的顶点
if w not in visited: # 如果该顶点未被访问过
stack.append(w) # 把顶点压入堆栈
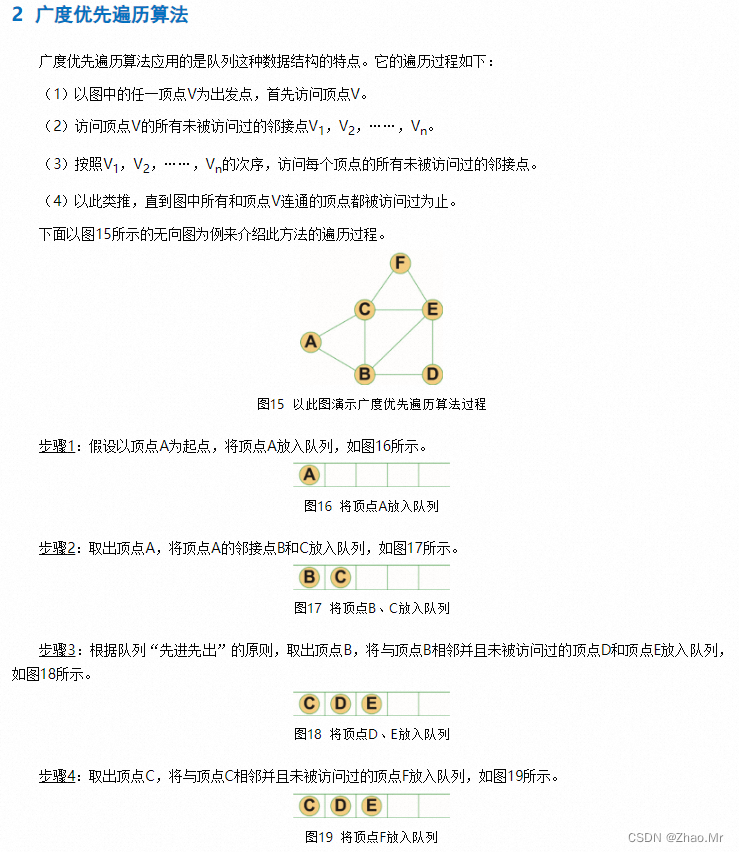
以顶点A为出发点,对该图进行深度优先遍历。
graph = { # 定义图的字典
"A": ["B","C"],
"B": ["A","D","E"],
"C": ["A","D","G"],
"D": ["B","C","F","H"],
"E": ["B","F"],
"F": ["D","E","G","H"],
"G": ["C","F","H"],
"H": ["D","F","G"],
}
def dfs(graph, start):
stack = [] # 定义堆栈
stack.append(start) # 将起始顶点压入堆栈
visited = set() # 定义集合
while stack:
vertex = stack.pop() # 弹出栈顶元素
if vertex not in visited: # 如果该顶点未被访问过
visited.add(vertex) # 将该顶点放入已访问集合
print(vertex,end = ' ') # 打印深度优先遍历的顶点
for w in graph[vertex]: # 遍历相邻的顶点
if w not in visited: # 如果该顶点未被访问过
stack.append(w) # 把顶点压入堆栈
print("图中各顶点的邻接点:")
for key,value in graph.items(): # 遍历图的字典
print("顶点",key,"=>",end=" ") # 打印顶点
for v in value: # 遍历顶点的邻接点
print(v,end=" ") # 打印顶点的邻接点
print()
print("深度优先遍历的顶点:")
dfs(graph,"A") # 调用函数并设置起点为A

在该例中应用的广度优先遍历算法,代码如下:
def bfs(graph, start):
queue = [] # 定义队列
queue.append(start) # 将起始顶点放入队列
visited = set() # 定义集合
visited.add(start) # 将起始顶点放入已访问集合
while queue:
vertex = queue.pop(0) # 取出队列第一个元素
print(vertex,end = ' ') # 打印广度优先遍历的顶点
for w in graph[vertex]: # 遍历相邻的顶点
if w not in visited: # 如果该顶点未被访问过
visited.add(w) # 将该顶点放入已访问集合
queue.append(w) # 把顶点放入队列
以顶点A为出发点,进行广度优先遍历。
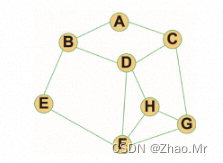
graph = { # 定义图的字典
"A": ["B","C"],
"B": ["A","D","E"],
"C": ["A","D","G"],
"D": ["B","C","F","H"],
"E": ["B","F"],
"F": ["D","E","G","H"],
"G": ["C","F","H"],
"H": ["D","F","G"],
}
def bfs(graph, start):
queue = [] # 定义队列
queue.append(start) # 将起始顶点放入队列
visited = set() # 定义集合
visited.add(start) # 将起始顶点放入已访问集合
while queue:
vertex = queue.pop(0) # 取出队列第一个元素
print(vertex,end = ' ') # 打印广度优先遍历的顶点
for w in graph[vertex]: # 遍历相邻的顶点
if w not in visited: # 如果该顶点未被访问过
visited.add(w) # 将该顶点放入已访问集合
queue.append(w) # 把顶点放入队列
print("图中各顶点的邻接点:")
for key,value in graph.items(): # 遍历图的字典
print("顶点",key,"=>",end=" ") # 打印顶点
for v in value: # 遍历顶点的邻接点
print(v,end=" ") # 打印顶点的邻接点
print()
print("广度优先遍历的顶点:")
bfs(graph,"A") # 调用函数并设置起点为A
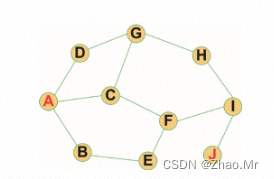
广度优先遍历可以应用在查找最短路径的问题中。假设在A城市到B城市之间有多条线路,每条线路都可能经过一些不同的城镇,应用图的广度优先遍历算法就可以找出A城市到B城市之间的最短路径。找出A城市到J城市之间最短的一条路径。
# 存储BFS结果
class BFSResult:
def __init__(self):
self.visited = [] # 已访问顶点
self.parent = {} # 上一级顶点
# 广度优先搜索
def bfs(graph,start):
r= BFSResult()
r.parent = {start:None} # 起始顶点的上一级顶点为None
r.visited.append(start) # 起始顶点加入已访问顶点列表
fronter = [start]
while fronter:
next = []
for u in fronter: # 遍历上一级顶点
for v in graph[u]: # 遍历当前顶点的相邻顶点
if v not in r.visited: # 如果该顶点未被访问
r.visited.append(v) # 将顶点加入已访问顶点列表
r.parent[v] = u # 定义当前顶点的上一级顶点
next.append(v)
fronter = next
return r
# 返回最短路径
def find_shortest_path(bfs_result,end):
start_vertex = bfs_result.visited[0] # 起始顶点
vertex_list = [end] # 最短路径顶点列表
if end != start_vertex: # 如果设置的终点不是起始顶点
parent_vertex = bfs_result.parent[end] # 获取终点的上一级顶点
vertex_list.insert(0,parent_vertex) # 将上一级顶点加入最短路径顶点列表
while parent_vertex != start_vertex and parent_vertex != None:
parent_vertex = bfs_result.parent[parent_vertex]
vertex_list.insert(0,parent_vertex)
return vertex_list # 返回最短路径顶点列表
if __name__ == '__main__':
graph = { # 定义图的字典
'A':['B','C','D'],
'B':['A','E'],
'C':['A','F','G'],
'D':['A','G'],
'E':['B','F'],
'F':['C','E','I'],
'G':['C','D','H'],
'H':['G','I'],
'I':['F','H','J'],
'J':['I']
}
bfs_result = bfs(graph,'A')
print('A城市到J城市的最短路径:')
result = find_shortest_path(bfs_result, 'J')
print(' -> '.join(result))
3. 最小生成树
一个图的生成树是以最少的边连通图中的所有顶点,且不产生回路的连通子图。如果一个图有n个顶点,那么生成树会含有图中全部顶点,但只有n-1条边。如果为图的每条边设置一个权重,这种图就叫加权图
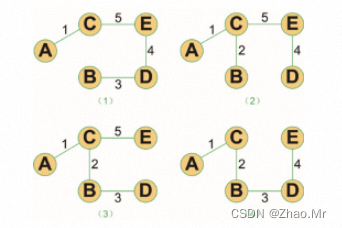


有四个地区A、B、C、D需要建设水资源工程。假设四个地区自建水库的费用分别是6、5、12、3,各地区之间建立引水管道的费用可以在图中使用权重表示。试着给出一个最优化的水资源配置方案,在保证每个地区都能用上水的前提下,使得整个引水工程需要的费用最低。
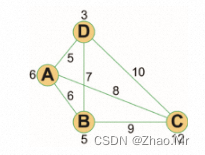
def prim(graph):
vertex_list = ["A","B","C","D"] # 顶点列表
cost = [6, 5, 12, 3] # 费用列表
visited = [0, 0, 0, 0] # 顶点是否已访问的列表,0表示未访问
n = len(vertex_list) # 图的顶点个数
for i in range(0,n):
k = 0
min = float("inf") # 最小值初始化
for j in range(0,n):
if(not visited[j] and cost[j]<min):
min = cost[j] # 获取费用列表最小值
k = j # 获取费用列表最小值的索引
visited[k] = 1 # 标记为已访问
for j in range(0,n):
if(not visited[j] and graph[k][j]<cost[j]):
cost[j] = graph[k][j] # 更新费用列表
return cost
def main():
graph = [[0, 6, 8, 5], # 图的权重列表
[6, 0, 9, 7],
[8, 9, 0, 10],
[5, 7, 10, 0]]
lowcost = prim(graph) # 调用函数
total_cost = 0 # 总费用初始化
for n in lowcost:
total_cost += n # 计算总费用
print("建立引水工程最小费用列表:"+str(lowcost))
print("四个地区建立引水工程最小费用为"+str(total_cost))
if __name__ == '__main__':
main() # 调用函数
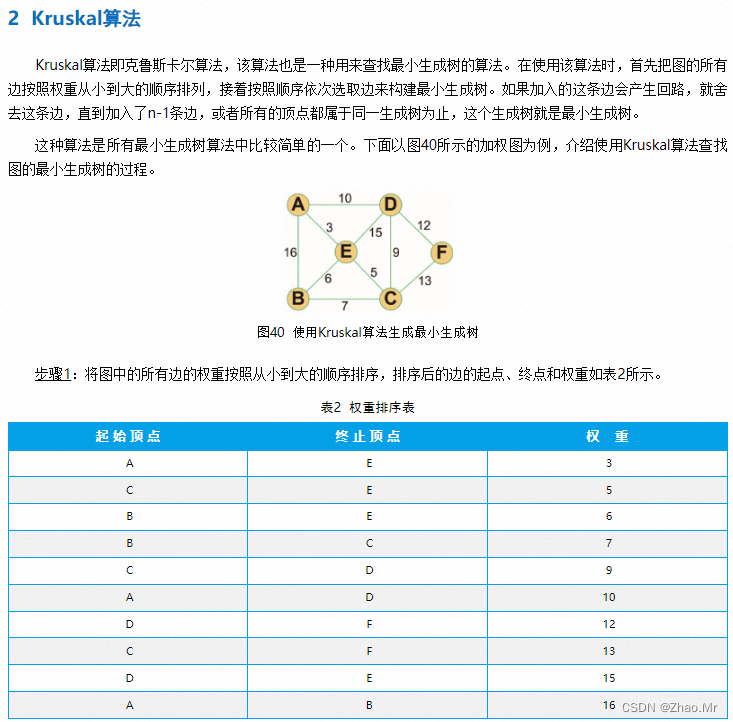
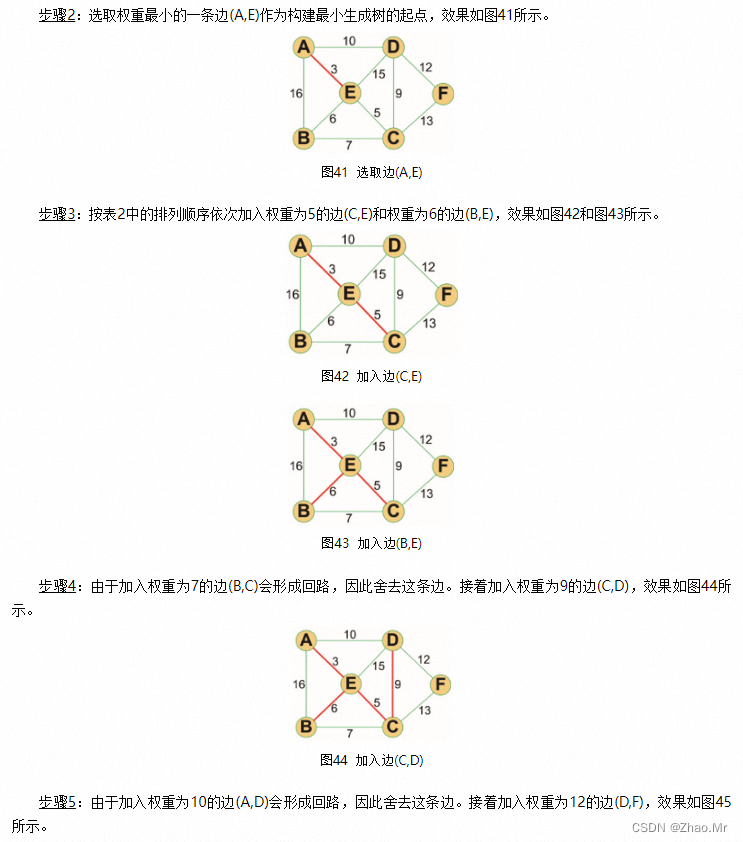
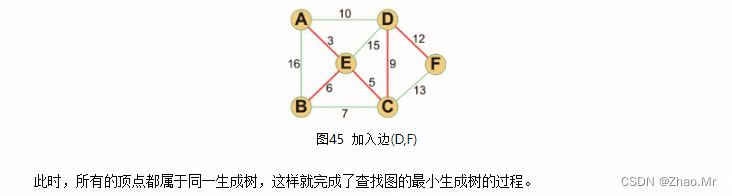
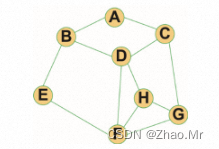
应用Kruskal算法获取最小生成树解决各城镇公路互通的问题。一共有七个城镇A、B、C、D、E、F、G,将各城镇之间的公路以及各城镇之间修建公路的成本在图中表示。试着根据给出的数据,求出使每个城镇都有公路连通最低成本的方案。

def Kruskal(vertex_list, edges):
all_vertex_list = vertex_list # 获取所有顶点列表
tree_name_list = [] # 树名称列表
for n in all_vertex_list:
tree_name_list.append(n) # 初始化树名称列表
MST = [] # 最小生成树列表
edges = sorted(edges, key=lambda element: element[2]) # 对所有边按权重升序排列
while len(MST) != len(vertex_list) - 1: # 最小生成树中的边为n-1时退出循环
element = edges.pop(0) # 获取权重最小的边
vertex_start = element[0] # 边的起始顶点
vertex_end = element[1] # 边的终止顶点
# 起始顶点所在树的名称
name1 = tree_name_list[all_vertex_list.index(vertex_start)]
# 终止顶点所在树的名称
name2 = tree_name_list[all_vertex_list.index(vertex_end)]
# 如果两个顶点不在同一树中,即加入边后不会形成回路
if name1 != name2:
MST.append(element) # 把边加入最小生成树列表
# 将所有树名称name2改为name1
for n in range(0,len(tree_name_list)):
if tree_name_list[n] == name2:
tree_name_list[n] = name1
return MST # 返回最小生成树列表
def main():
vertex_list = ["A","B","C","D","E","F","G"] # 图的所有顶点列表
# 图的所有边组成的列表
edges = [("A", "B", 10), ("A", "F", 3),
("A", "G", 6), ("B", "C", 7),
("B", "G", 8), ("C", "D", 9),
("C", "G", 5), ("D", "E", 15),
("D", "G", 10), ("E", "F", 12),
("E", "G", 13), ("F", "G", 9)]
tree_list = Kruskal(vertex_list, edges) # 调用函数
print("实现各城镇公路互通的方案如下:")
for n in tree_list:
print("({:s}—{:s})".format(n[0],n[1]))
total_price = 0 # 最低成本初始化
for n in tree_list:
total_price += n[2] # 计算最低成本
print("\n各城镇公路互通的最低成本:"+str(total_price))
if __name__ == '__main__':
main() # 调用函数
4. 最短路径问题
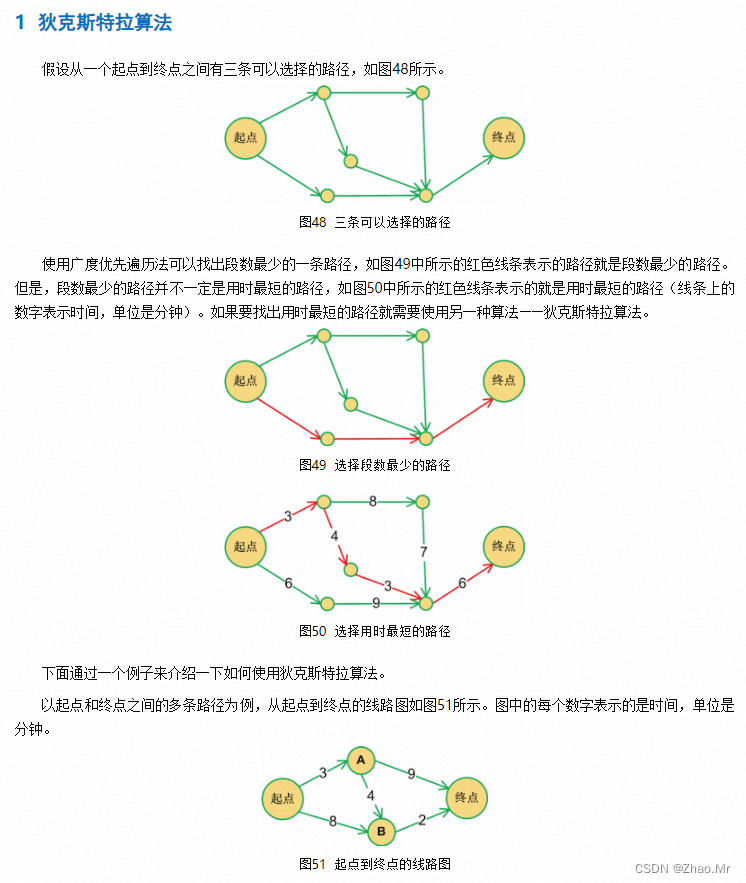
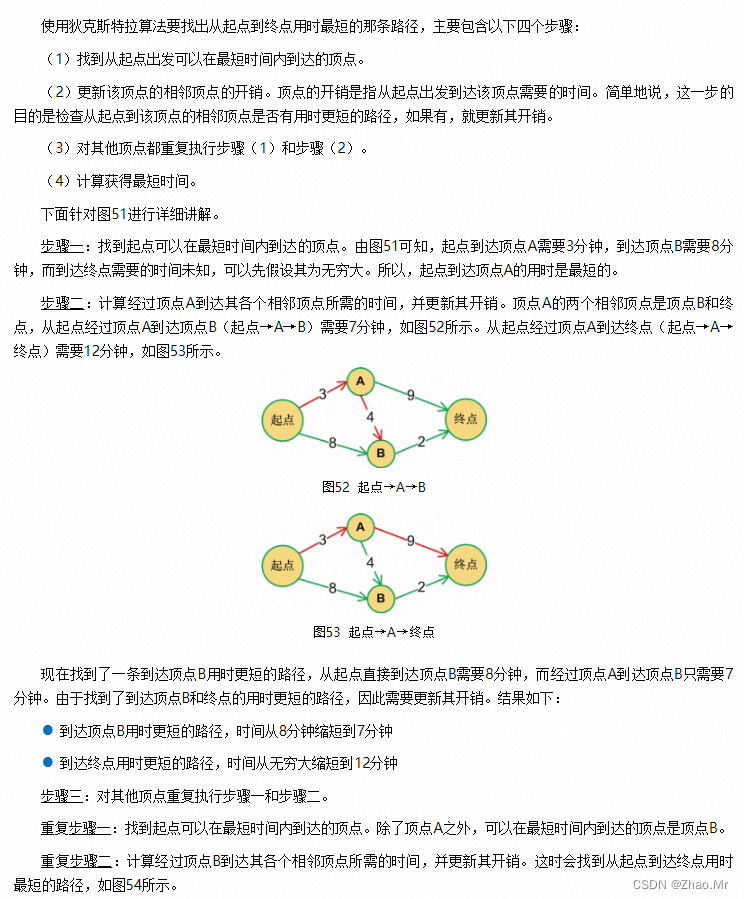
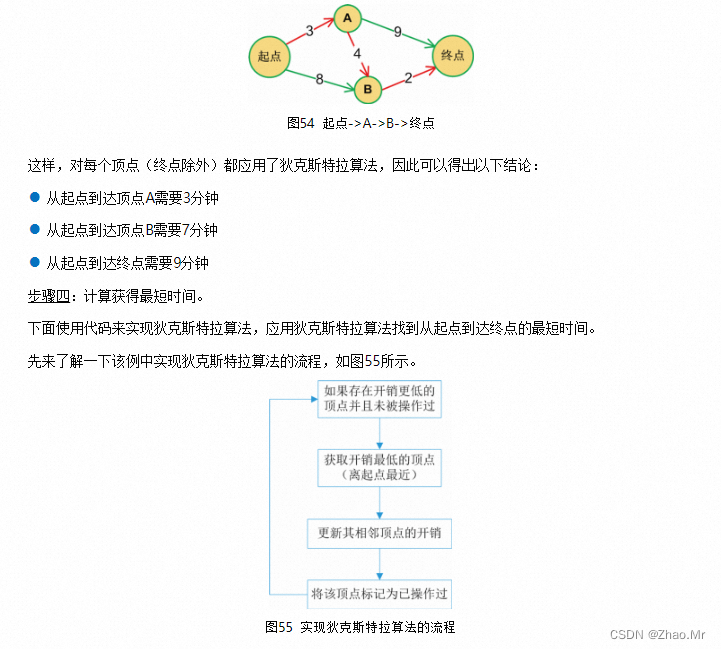

通过Floyd算法获取图中所有顶点间的最短路径。
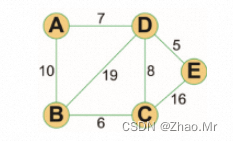
import math
vertexes = ['A', 'B', 'C', 'D', 'E'] # 顶点列表
# 初始化路径矩阵
dis = [[0, 10, math.inf, 7, math.inf],
[10, 0, 6, 19, math.inf],
[math.inf, 6, 0, 8, 16],
[7, 19, 8, 0, 5],
[math.inf, math.inf, 16, 5, 0]]
vertex_num = len(vertexes) # 顶点个数
for i in range(vertex_num):
for j in range(vertex_num):
for k in range(vertex_num):
# dis[i][j]表示i到j的最短距离
# dis[i][k]表示i到k的最短距离
# dis[k][j]表示k到j的最短距离
# 找到两顶点间的最短距离并更新
dis[i][j] = min(dis[i][j], dis[i][k] + dis[k][j])
print('最短路径矩阵如下:')
print('====================================')
print(' A B C D E') # 打印横向各顶点
for i in range(vertex_num):
print(vertexes[i], end=' ') # 打印纵向各顶点
for j in range(vertex_num):
print('%5d ' %dis[i][j], end='')
print()





![[论文笔记]End-to-end Sequence Labeling via Bi-directional LSTM-CNNs-CRF](https://img-blog.csdnimg.cn/img_convert/e342026648a402b975033f821694f6e5.png)