欢迎来到爱书不爱输的程序猿的博客, 本博客致力于知识分享,与更多的人进行学习交流
本文收录于SQL应知应会专栏,本专栏主要用于记录对于数据库的一些学习,有基础也有进阶,有MySQL也有Oracle

分析函数的点点滴滴
- 1.什么是分析函数:
- 1.1统计分析函数略解
- 1.2.排序分析函数
- 1.2.1 ==ROW_NUMBER==
- MySQL/Oracle的通用方法
- MySQL方法1:使用分析函数
- MySQL方法1.1:
- Oracle方法1:
- 1.2.2 DENSE_RANK
- 1.2.3rank 跳跃排序
- 1.2.4 FIRST和LAST
- 1.2.5 FIRST_VALUE 和 LAST_VALUE
1.什么是分析函数:
分析函数用于计算基于组的某种聚合值,它和聚合函数的不同之处是对于每个组返回多行,而聚合函数对于每个组只返回一行。
- 聚合函数会把行数变少,分析函数不会把行数变少
oracle分析函数的语法:
function_name(arg1,arg2,...)
over
(<partition-clause> <order-by-clause ><windowing clause>)
partition-clause 数据记录集分组
order-by-clause 数据记录集排序
windowing clause 功能非常强大、比较复杂,定义分析函数在操作行的集合。有三种开窗方式: range、row、specifying。
1.1统计分析函数略解
- COUNT
功能描述:该函数计算组中表达式的个数。 - SUM
功能描述:该函数计算组中表达式的累积和。 - MIN
功能描述:在一个组中的数据窗口中查找表达式的最小值。 - MAX
功能描述:在一个组中的数据窗口中查找表达式的最大值。 - AVG
功能描述:用于计算一个组和数据窗口内表达式的平均值
1.2.排序分析函数
1.2.1 ROW_NUMBER
功能描述:返回有序组中一行的偏移量,从而可用于按特定标准排序的行号。
- 自行扩展:oracle中rownum与row_number的区别
-- 下例返回每个员工再在每个部门中按员工号排序后的顺序号
SELECT
department_id,
first_name||' '||last_name employee_name, -- 拼接了一个雇员的姓名
employee_id,
ROW_NUMBER() OVER (PARTITION BY department_id ORDER BY employee_id) AS emp_id -- 根据OVER()里面的内容使用row_number()进行排序
FROM employees
-- 查找部门内最高薪水的员工信息
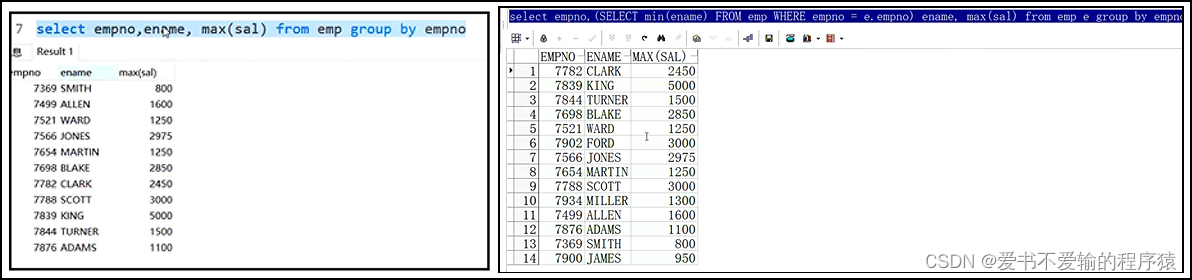
mysql:select empno,ename,max(sal) from emp group by empno -- select中的粒度比group by的粒度细,这在 MySQL中可以,但是我这里不行,可能是版本问题
oracle:select empno,(select min(ename) from emp where empno = e.empno) ename,max(sal) from emp e group by empno; -- 括号中的min是当一个empno对应多个ename的时候,如果对应一个ename的时候,可以不写min -- 括号里面使用别名是为了区分里面的emp和外面的emp,如果不加别名,默认就是里面的emp
MySQL/Oracle的通用方法
select e0.*
from emp e0,
(select deptno,max(sal) sal_max from emp group by deptno) e1,
where e0.deptno = e1.deptno
and e0.sal = e1.sal_max; -- 因为求得是部门最高薪水的员工信息,如果没有这个关联,那只是求出了最高薪水
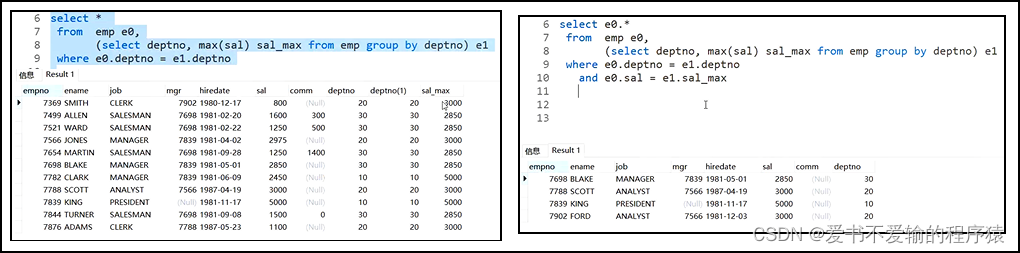
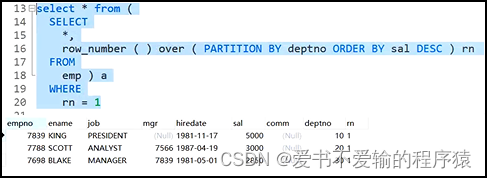
MySQL方法1:使用分析函数
select * from(
select *,row_number() over (partition by deptno order by sal desc) rn from emp
) a where rn = 1; -- 如果没有外层嵌套的select * from 的话,是不可使用where rn = 1的,要时刻注意执行顺序,rn在select子句中,where的执行顺序比select早
# 而且MySQL还得加一个别名(上面的a),不加报错,Oracle不加不报错
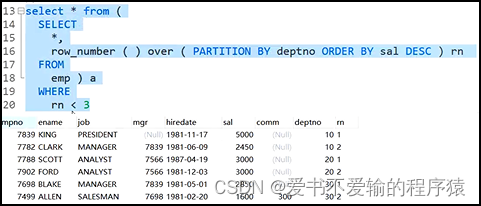
MySQL方法1.1:
# 如果要求是排名前2的
select * from(
select * ,
row_number() over ( partition by deptno order by sal desc) rn
from emp
) a where rn < 3; -- 因为是降序排序的,也可以是 rn <= 2 或者between 1 and 2
# ★ not rn > 2 如果使用not进行反选的话,效率是很低的,而且not有时候会让索引失效,部分失效
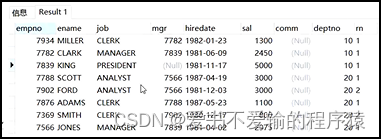
# 查看每个部门每个岗位的薪水
select * ,
row_number() over ( partition by deptno,job order by sal desc) rn
from emp
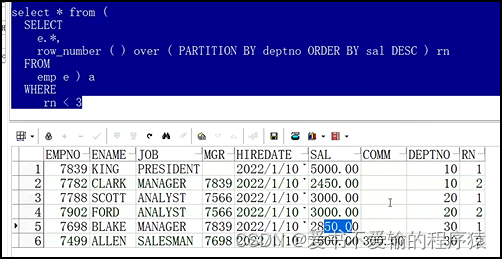
Oracle方法1:
select * from (
select e.*, -- Oracle中如果直接使用*的话,会发生错误,原因未知,所以使用别名
row_number() over (partition by deptno order by sal desc) rn
from emp e
) a where rn < 3;
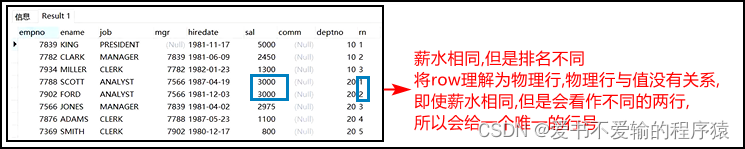
-- 把row理解成物理行,上面根据薪水进行排序,但是物理行的行号与薪水的值是没有关系的,会认为sal相同的数据只是不同的行,所以会给一个唯一的行号
- 扩展
select *,
row_number () over (partition by deptno order by sal desc) rn
from emp;
1.2.2 DENSE_RANK
select * from(
select *,
dense_rank() over (pritition by deptno order by sal desc)rn
from emp)a
where
rn < 2;
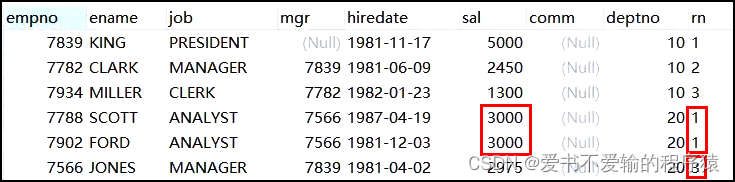
- dense_rank 密集的,稠密的,不间断地
- 下图中很明显,相同的数据不进行排名(可以用同为100分的两个同学并列第一来理解,99分的同学排名第二)

- 下图中很明显,相同的数据不进行排名(可以用同为100分的两个同学并列第一来理解,99分的同学排名第二)
1.2.3rank 跳跃排序
select * from(
select *,
rank() over (pritition by deptno order by sal desc)rn
from emp)a
where
rn < 2;
- 同为100分的两个同学并列第一来理解,99分的同学排名第三
1.2.4 FIRST和LAST
- FIRST
功能描述:从DENSE_RANK返回的集合中取出排在最前面的一个值的行(可能多行,因为值可能相等),因此完整的语法需要在开始处加上一个集合函数以从中取出记录
- LAST
功能描述:从DENSE_RANK返回的集合中取出排在最后面的一个值的行(可能多行,因为值可能相等),因此完整的语法需要在开始处加上一个集合函数以从中取出记录
select e.*,
rank() over (partition by deptno order by sal) rn,
MIN(sal) KEEP (dense_rank last order by sal) over (pritition by deptno),
MAX(sal) KEEP (dense_rank first order by sal) over (partition by deptno)
from emp e
- order by 默认是升序,所以使用last取得是最大值,如果最大值有多个,通过前面的
MIN(sal) KEEP来得到一个值
1.2.5 FIRST_VALUE 和 LAST_VALUE
FIRST_VALUE:返回组中数据窗口的第一个值。
LAST_VALUE:返回组中数据窗口的最后一个值
# oracle:
select e.*,
LAST_VALUE(empno) over (partition by deptno order by sal) rn
from emp e
# mysql:
create table tmp2
select * from emp order by deptno,sal
select e.*,
LAST_VALUE (empno) over (partition by deptno) rn
from tmp2 e
结论:
mysql想取到组中按照某个字段排序得最大值或最小值对应得其他信息,得提前将表按照字段排序并物化成临时表,然后再利用分析函last_value和first_value从临时表中进行查询,才能得出正确结果
oracle可以直接对源表进行order by,然后用分析函数ast_value和first_value直接查询。 (待验证逻辑: order by 执行顺序最后的,但是这个例子说明orderby在前,分析函数执行在后)



![[论文笔记]End-to-end Sequence Labeling via Bi-directional LSTM-CNNs-CRF](https://img-blog.csdnimg.cn/img_convert/e342026648a402b975033f821694f6e5.png)