Java性能权威指南-总结14
- 堆内存最佳实践
- 对象生命周期管理
- 对象重用
堆内存最佳实践
对象生命周期管理
在很大程度上,Java会尽量减轻开发者投入到对象生命周期管理上的精力:开发者在需要的时候创建对象,当不再需要这些对象时,它们会走出作用域,并由垃圾收集器释放。
有些情况下,正常的生命周期并不是最优的。有些对象创建的成本很高,而管理这些对象的生命周期可以改进应用的效率,即便以让垃圾收集器多做些工作为代价。
对象重用
对象重用通常有两种实现方式:对象池和线程局部变量。这两种技术都会影响GC的效率,特别是对象池。
对象池技术存在的问题显而易见:被重用的对象会在堆中停留很长时间。如果有大量对象存在于堆中,那用来创建新对象的空间就少了,因为GC操作会更为频繁。
**对象创建时是分配在Eden区的。在最终提升到老年代之前,会在Survivor区反复经历一些Young GC周期。**每当处理到最近创建或者新创建的池化对象时,GC算法必须执行一些工作,去复制这个对象,并调整指向它的引用,直到该对象最终进入老年代。
一旦对象被提升到老年代,可能引发的性能问题甚至会更多。执行一次Full GC所花的时间与老年代中仍然存活的对象数量成正比。 存活对象的数量甚至比堆的大小更重要;处理一个3GB大小但存活对象很少的老年代,与处理一个1GB大小但存活对象占75%的老年代相比,速度要快一些。
使用某个并发收集器避免Full GC并不能使情况有所好转,这是因为,并发收集器的标记堆内存最佳实践阶段所花的时间也依赖于仍存活数据的数量。特别是对CMS而言,池中的对象很可能会在不同的时间被提升,这会增大因碎片而导致的并发故障的机会。总的来说,对象在堆中存留的时间越长,GC的效率越差。因此,大部分情况对象重用并不好。
JDK提供了一些常见的对象池:线程池和软引用。 软引用本质上是一大池可重用对象。同时Java EE依赖对象池来连接数据库和其他资源,而且EJB(Enterprise Java Beans)的整个生命周期都是围绕对象池的概念构建的。
线程局部变量的情况类似;JDK中到处是使用线程局部变量的类,以避免重新分配特定种类的对象。之所以要重用对象,原因是很多对象初始化的成本很高,与增加的GC时间这一点相权衡,重用更为高效。对于像JDBC连接池这样的东西,肯定如此:创建网络连接,以及可能还要进行的登录和建立数据库会话,成本非常高。这种情况下,对象池有很大的性能优势。线程也可以池化,以节省创建线程的时间;随机数生成器是作为线程局部变量提供的,以节省生成随机数的时间;诸如此类。
这些例子有一个共同的特性,即初始化对象需要的时间较长。 在Java中,对象分配非常快,成本也不高。对象初始化的性能取决于对象本身。应该只考虑重用初始化成本非常高的对象,而且是只有当初始化这些对象的代价在程序中是主导性操作之一时。
这些例子还有一个共性,那就是所共享对象的数目往往很小,以便最小化对GC的影响:即它们的数量较小,还不足以降低GC周期。 池中有少量对象,对GC效率不会影响太大;如果堆中满是池化对象,就会严重影响GC了。
下面是JDK和Java EE中重用对象的一些例子,以及重用的原因:
线程池
线程初始化的成本很高。
JDBC池
数据库连接初始化的成本很高。
EJB池
EJB初始化的成本很高。
大数组
Java要求,一个数组在分配的时候,其中的每个元素都必须初始化为某个默认值(null、0或者false,根据具体情况而定)。对于很大的数组,这是非常耗时的。
原生NIO缓冲区
不管缓冲区多大,分配一个直接的java.nio.Buffer(即调用allocateDirect()方法返回的缓冲区),这个操作都非常昂贵。最好是创建一个很大的缓冲区,然后通过按需切割的方式来管理,以便将其重用于以后的操作。
安全相关类
MessageDigest、Signature以及其他安全算法的实例,初始化的成本都很高。基于Apache的XML代码就是使用线程局部变量保存这些实例的。
字符串编解码器对象
JDK中的很多类都会创建和重用这些对象。在大多数情况下,这些还是软引用。
StringBuilder协助者
BigDecimal类在计算中间结果时会重用一个StringBuilder对象。
随机数生成器
Random类和(特别是)SecureRandom类,生成它们的实例的代价是很高的。
从DNS查询到的名字
网络查询代价很高。
ZIP编解码器
有一种有趣的变化,初始化的开销不是特别高,但是释放的成本很高,因为这些对象要依赖对象终结操作(finalization)来确保释放掉所用的原生内存。
此处讨论的对象池和线程局部变量两种方式,在性能上有些差别。下面详细看一下。
- 对象池
对象池不受人喜欢,原因有多个方面,只有部分原因和性能有关。线程池的大小可能很难正确地设置,它们将对象管理的负担又抛给程序员了:程序员不能简单地将对象丢出作用域,而必须记得将其返还到对象池中。不过这里的焦点是对象池的性能,它受如下几个因素的影响:
GC影响
保存大量对象会降低GC的效率(有时非常显著)。同步对象池必然是同步的,如果对象要频繁地移除和替换,对象池上可能会存在大量竞争。其结果是,访问对象池可能比初始化新对象还慢。
限流(Throttling)
对象池对性能也有正面的影响:对于对稀缺资源的访问,线程池可以起到限流作用。如果想增加的负载超出系统的处理能力,性能将下降。这是线程池之所以很重要的一个原因。如果有太多线程同时运行,CPU将不堪重负,而且性能会下降。
这一原则也适用于远程系统的访问,而且在JDBC连接中会经常见到。如果JDBC连接数超出数据库的处理能力,数据库的性能就会下降。在这些情况下,通过确定池的上限来限制资源数(如JDBC连接数)更好,即便这意味着应用中的线程必须等待一个空闲资源。
- 线程局部变量
在通过将对象保存为线程局部变量这种技术实现对象重用时,有不同的性能权衡,如下所列:
生命周期管理
线程局部变量要比在池中管理对象更容易,成本更低。这两种技术都邀请开发者去获取初始对象:或者是从对象池中检出,或者是在线程局部对象上调用get()方法。但是对象池还要求开发者在使用完毕后归还对象(否则其他人就不能使用了);线程局部对象在线程内总是可用的,不需要显式地归还。
基数性(Cardinality)
线程局部变量通常会伴生线程数与保存的可重用对象数之间的一一对应关系。不过并非严格如此。线程的变量副本,直到该线程第一次访问它时,才会创建,因此保存的对象数有可能小于线程数。但是保存的对象数不可能会超过线程数,大部分时间两者是相同的。
另一方面,对象池的大小则有些随意。如果一个Servlet有时需要一个JDBC连接,有时需要两个,则JDBC池的大小可以相应设定(比如说,对于8个线程,设定12个连接)。线程局部变量做不到这一点,也不能减少对资源的访问(除非线程数本身可以减少)。
同步
线程局部变量不需要同步,因为它们只能用于一个线程之内;而且线程局部的get()方法相当快。(情况并非一直如此,在早期的Java版本中,获得一个线程局部变量的开销很大。如果过去因为差劲的性能而远离了线程局部变量,在当前的Java版本中,可以重新考虑一下。)
同步还带来了一个有趣的问题,因为线程局部对象的性能优势通常会用节省了同步的代价来表达(而不说这是重用对象的好处)。比如,Java 7引入了一个ThreadLocalRandom类;这个类(而不是一个Random实例)也用到了示例股票应用中。此外,本书中的很多例子在Random对象的next()方法上都会遇到一个同步瓶颈。使用线程局部对象是避免同步瓶颈的好方法,因为只有一个线程能使用这个对象。
然而,只要让这个例子每次需要时,就简单地创建一个新的Random实例,同步问题也能轻松解决。不过,这样解决同步问题对整体性能没什么帮助:初始化一个Random对象的开销非常大,而且持续创建这个类的实例,与在多个线程间共享一个类实例的同步瓶颈相比,性能可能更差。
使用ThreadLocalRandom类性能会更好,如下表所示。这个例子使用了batching stock应用,对于每支股票,有创建新的Random实例和重用ThreadLocalRandom两种方案。
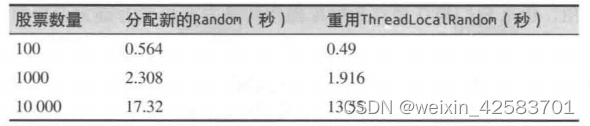
对于一般的对象重用,这里的经验是,在初始化对象需要很长时间时,不用畏惧探索用对象池或线程局部变量技术来重用那些创建开销高昂的对象。不过还是要找到一个平衡点:对于一般的类,较大的对象池所带来的性能问题很可能比解决的问题还要多。所以应该将这些技术应用于初始化成本高昂,以及重用对象的数目比较小时。
快速小结
- 对象重用通常是一种通用操作,并不鼓励使用它。但是这种技术可能适合初始化成本高昂,而且数量比较少的一组对象。
- 在使用对象池还是使用线程局部变量这两种技术之间,应该有所取舍。一般而言,建设线程和可重用对象直接存在一一对应关系,则线程局部变量更容易使用。


![[论文笔记]End-to-end Sequence Labeling via Bi-directional LSTM-CNNs-CRF](https://img-blog.csdnimg.cn/img_convert/e342026648a402b975033f821694f6e5.png)


![[元带你学: eMMC协议详解 17] eMMC 安全方案 之 RPMB(Replay Protected Memory Block 重放保护内存块)](https://img-blog.csdnimg.cn/img_convert/262abfa94e2b5642120b21810384ce4b.png)


![使用 Sa-Token 实现 [记住我] 模式登录、七天免登录](https://img-blog.csdnimg.cn/img_convert/bb003babb43320635e7de7e6300ad907.gif)