文章目录
- 1. 前言
- 2. 从SQL提交到Fragment计划生成全过程
- 2.1 Statement生成
- 2.2 对结构化的Statement进行分析
- 2.3 生成未优化的逻辑执行计划
- 2.4 基于Visitor模型对逻辑执行计划进行优化
- 2.4.1 Visitor模型介绍
- 2.4.2 Presto中常见的逻辑执行计划优化器
- 常规Optimizer
- IterativeOptimizer
1. 前言
我是Hulu被裁员工,欢迎勾搭。。
跟大多数OLAP/OLTP一样,Presto的SQL从提交到执行,遵循相似的解析、优化和调度逻辑,本文主要介绍Presto执行过程中逻辑执行计划的解析和Fragment的生成,即物理执行计划生成以前的过程,让读者对SQL引擎对逻辑执行计划的生成和优化有基本的了解。不同的执行引擎的具体实现不同,但是基本原理一致。
欢迎交流。。
2. 从SQL提交到Fragment计划生成全过程
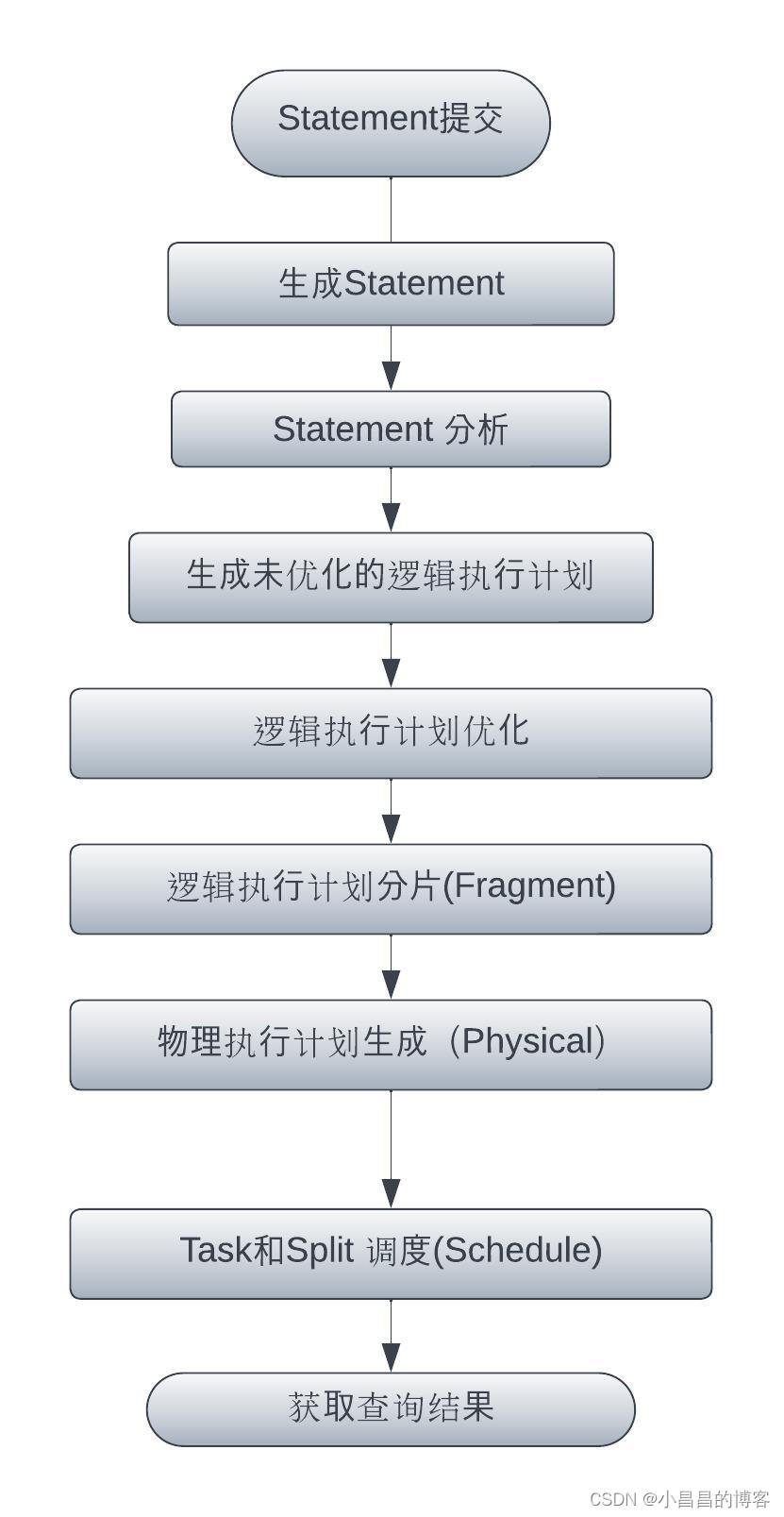
从SqlQueryExecution.java(L329)可以看到从逻辑执行计划、物理执行计划再到调度开始的基本流程:
try (SetThreadName ignored = new SetThreadName("Query-%s", stateMachine.getQueryId())) {
try {
// 构建逻辑执行计划,并对计划进行Fragment处理
PlanRoot plan = planQuery();
planDistribution(plan); // 生成物理执行计划
......
SqlQueryScheduler scheduler = queryScheduler.get();
if (!stateMachine.isDone()) {
scheduler.start(); // 开始进行调度
}
}
catch (Throwable e) {
fail(e);
throwIfInstanceOf(e, Error.class);
}
}
基本流程如下图:
我们创建表zipcodes_orc_flat, 并基于下面Query,查看逻辑执行计划从SQL 到 LogicPlan生成的整个过程:
CREATE TABLE `default.zipcodes_orc_flat`(
`recordnumber` int,
`country` string,
`city` string,
`zipcode` int)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.orc.OrcSerde'
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.orc.OrcInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat'
LOCATION
'hdfs://localhost:9000/user/hive/warehouse/zipcodes_orc_flat'
select country, count(1)
from hive.default.zipcodes_orc_flat
group by country
order by country asc limit 2;
2.1 Statement生成
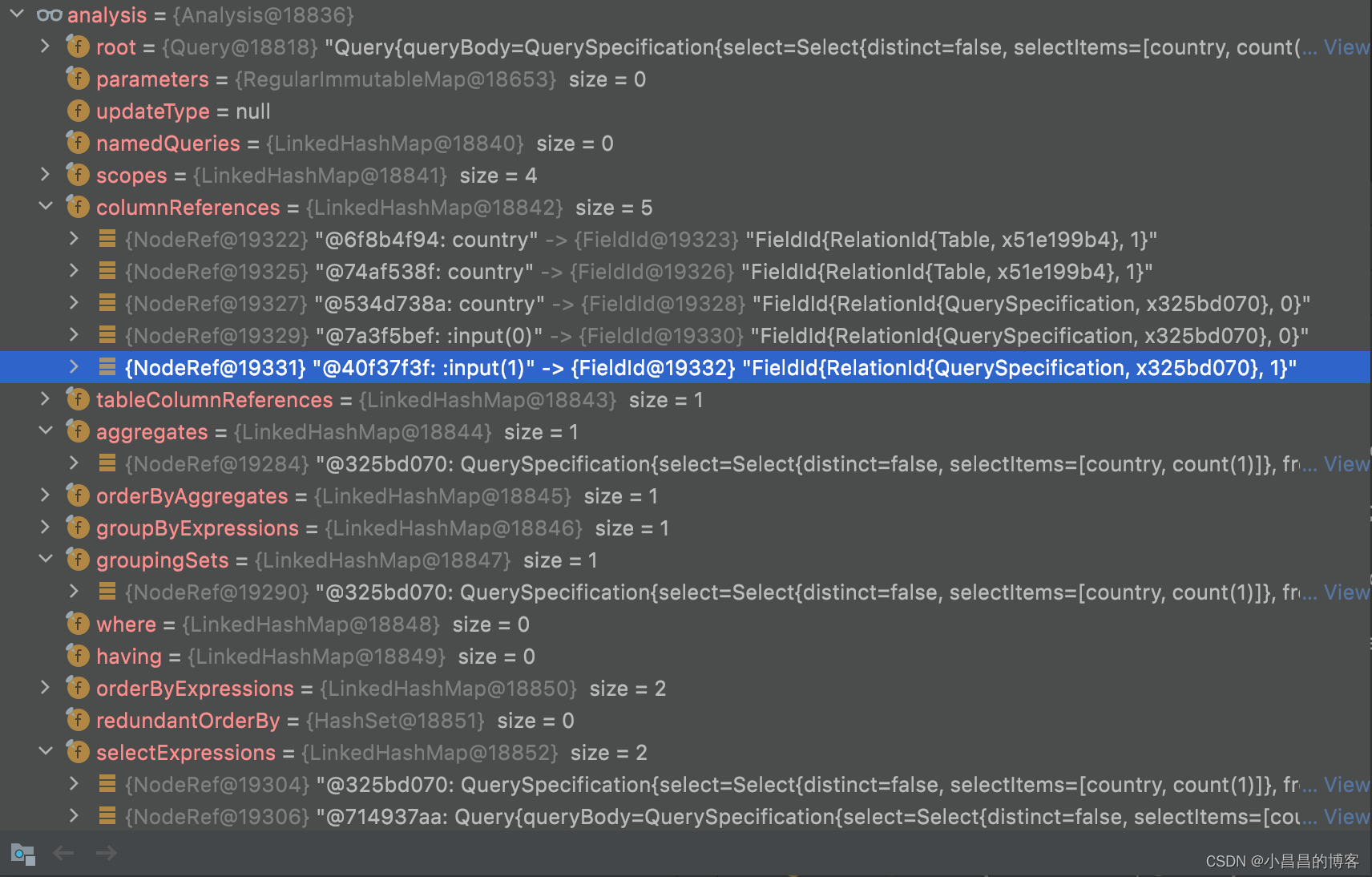
基于Antlr对SQL进行语法分析,生成SQL对应的Statement, statement中含有对SQL基本的结构化解析结果:

整个的Query会的body会对应QuerySpecification对象,而where关键字会解析成一个Where对象,limit关键字解析成Limit对象。这个解析过程是Antlr 来做的,感兴趣的同学可以自行阅读Antlr相关的代码,本文不做赘述。
public class QuerySpecification
extends QueryBody
{
private final Select select;
private final Optional<Relation> from;
private final Optional<Expression> where;
private final Optional<GroupBy> groupBy;
private final Optional<Expression> having;
private final Optional<OrderBy> orderBy;
private final Optional<Offset> offset;
private final Optional<Node> limit;
public class GroupBy
extends Node
{
private final boolean isDistinct;
private final List<GroupingElement> groupingElements;
public class Select
extends Node
{
private final boolean distinct;
private final List<SelectItem> selectItems;
就这样,我们完成了第一步,对SQL的最基本的结构化处理。
2.2 对结构化的Statement进行分析
生成了结构化的表达以后,就可以基于Visitor模式,进行进一步的语法和语义分析。和下文即将提到的逻辑执行计划的优化以及执行计划的分段一样,这里的分析也是基于Visitor访问者模式进行的。被访问者Element是基于关键词解析出来的对象,访问者Visitor是StatementAnalyzer(Abstract Syntax Tree)。 这一层的解析可以做很多非常琐碎的检查工作,比如:
- 权限检查
– 查询语句,用户是否有对应表的查询权限?
– DML语句,用户是否有对应的DML权限? - 语法检查
–Where中的expression是否是一个布尔表达式?
–Group by [expression index]中index是否超过了expression的数量?比如:SELECT count(*), nationkey FROM customer GROUP BY 3;会抛出GROUP BY position 3 is not in select list异常
–Limit n或者FETCH FIRST n ROWS WITH TIES关键字的n是否是一个正整数?
–FETCH FIRST WITH TIES必须和ORDER BY搭配使用,否则抛出FETCH FIRST WITH TIES clause requires ORDER BY异常
–Order by关键字的值是否真的是可以被排序的类型?比如,Presto中的color类型、lambda表达式类型就不可以被排序
–Order by表达式是否存在于sub query中?如果存在,将被忽略并warning,因为子query中的order by是无效的,但是不至于让query失败 - 其它必要的结构重写
等等
2.3 生成未优化的逻辑执行计划
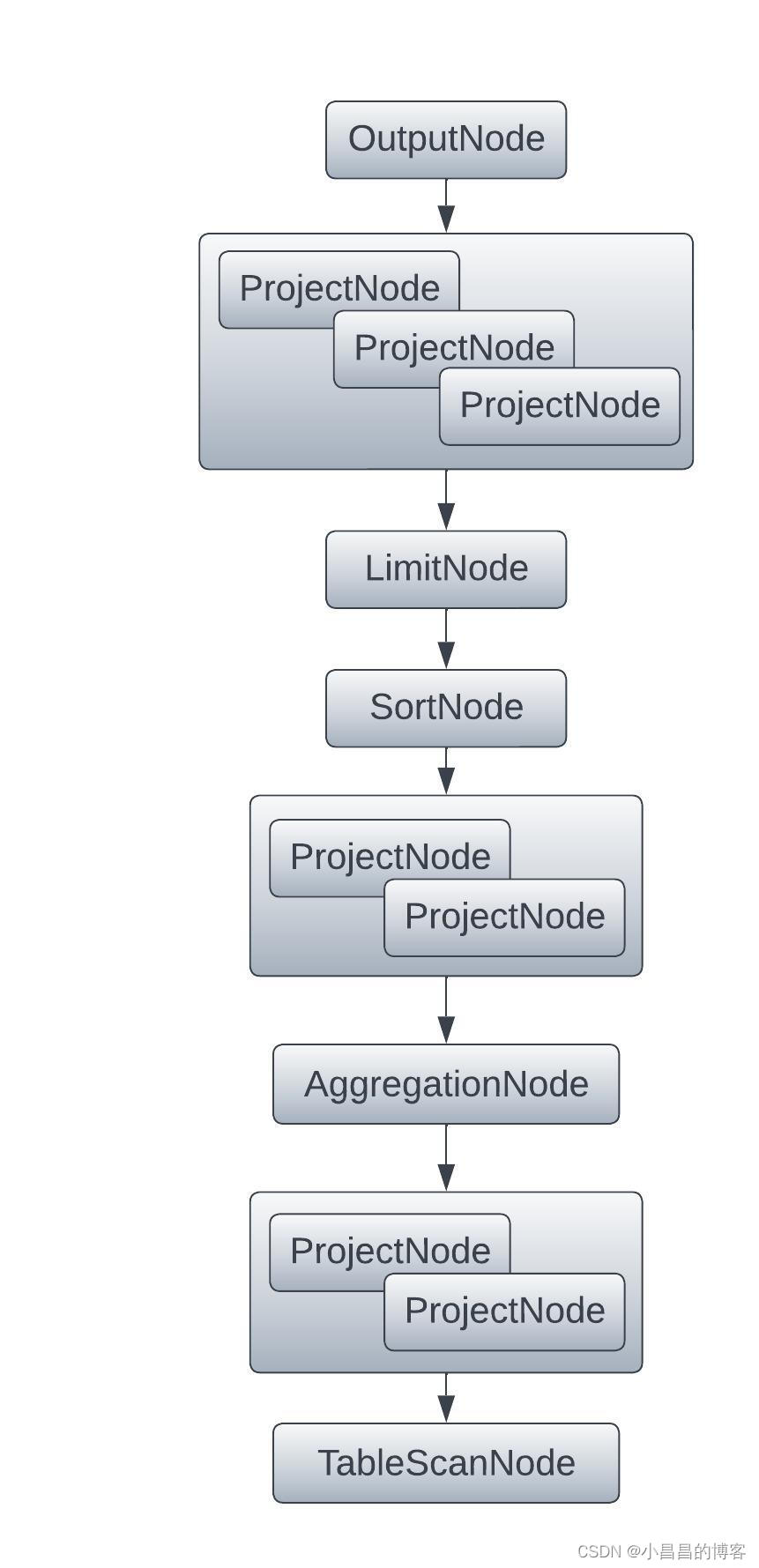
根据上文产生的Statement, 生成无任何优化的逻辑执行计划树,树的每一个节点都是一个PlanNode接口的实现。
public Plan plan(Analysis analysis, Stage stage, boolean collectPlanStatistics)
{ // 无任何优化的逻辑执行计划
PlanNode root = planStatement(analysis, analysis.getStatement());
planSanityChecker.validateIntermediatePlan(root, session, metadata, typeAnalyzer, symbolAllocator.getTypes(), warningCollector);
// 针对root节点(往往是OutputNode, 遍历所有的Optimizer,进行优化)
if (stage.ordinal() >= OPTIMIZED.ordinal()) {
for (PlanOptimizer optimizer : planOptimizers) {
root = optimizer.optimize(root, session, symbolAllocator.getTypes(), symbolAllocator, idAllocator, warningCollector);
requireNonNull(root, format("%s returned a null plan", optimizer.getClass().getName()));
}
}
.......
无任何优化的逻辑执行计划如下图,我们对比上文的SQL,很容易梳理清楚SQL和下图的逻辑执行计划的对应关系:
2.4 基于Visitor模型对逻辑执行计划进行优化
这一步的主要工作,遍历当前加载的所有PlanOptimizer实现,依次对生成的未优化的逻辑执行计划树进行迭代优化
2.4.1 Visitor模型介绍
在Presto的逻辑执行计划生成过程中,Visitor模式用来对生成的基本逻辑执行计划进行重写。很多文章都对设计模式中的visitor模式有很多的介绍,我们不再赘述。这里我们主要从Presto的代码上看一看Visitor模式和逻辑执行计划生成。
在Presto基于Visitor模式的逻辑执行计划生成过程中,当前基于语义分析生成的逻辑执行计划为受访者(Element)角色,而为逻辑执行计划的修改和优化提供的各种优化器Optimizer(其实是每一个优化器的内部实现类Rewriter)是访问者(Visitor)角色。
逻辑执行计划的节点都是PlanNode的实现类:
public abstract class PlanNode
{
private final PlanNodeId id;
......
public abstract List<PlanNode> getSources();
public abstract List<Symbol> getOutputSymbols();
public abstract PlanNode replaceChildren(List<PlanNode> newChildren);
public <R, C> R accept(PlanVisitor<R, C> visitor, C context)
{
return visitor.visitPlan(this, context);
}
}
最核心的accept()方法,代表这个被访问者接受对应Visitor的访问,接受的方式,就是调用Visitor的visitPlan()方法:
public Plan plan(Analysis analysis, Stage stage, boolean collectPlanStatistics)
{
// 根据用户的SQL Query生成的初始逻辑执行计划
PlanNode root = planStatement(analysis, analysis.getStatement());
planSanityChecker.validateIntermediatePlan(root, session, metadata, typeAnalyzer, symbolAllocator.getTypes(), warningCollector);
// 针对root节点(往往是OutputNode, 遍历所有的Optimizer,进行优化)
if (stage.ordinal() >= OPTIMIZED.ordinal()) {
for (PlanOptimizer optimizer : planOptimizers) {
root = optimizer.optimize(root, session, symbolAllocator.getTypes(), symbolAllocator, idAllocator, warningCollector);
requireNonNull(root, format("%s returned a null plan", optimizer.getClass().getName()));
}
}
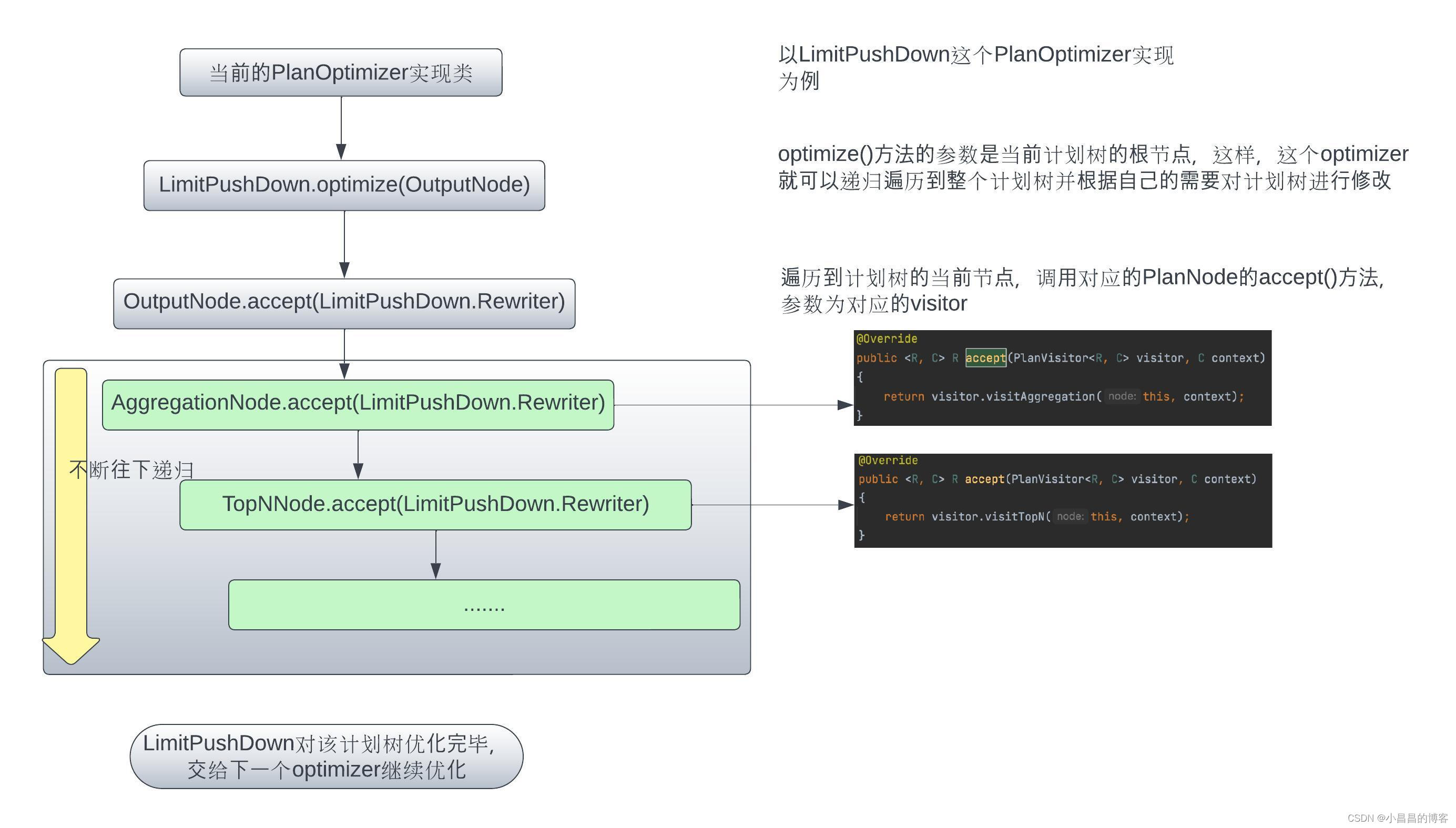
通过plan()方法,可以看到,Presto基于生成的初始执行计划(没有进行任何优化,仅仅是对用户的SQL生成了结构化的plan), 遍历所有的planOptimizers, 调用对应的optimize()方法。 具体的Optimizer都会实现optimize()方法,在optimize()方法中从Root PlanNode(比如对于普通的Select query, 逻辑执行计划树的root节点是OutputNode,即结果输出的节点 )。
我们可以查看PlanOptimizers.java看到Presto所加载的所有planOptimizers.
对于每一个PlanOptimizer实现,它调用的过程如下图所示:
2.4.2 Presto中常见的逻辑执行计划优化器
逻辑执行计划的优化过程就是不断apply各种PlanOptimizer实现的过程,如下图:
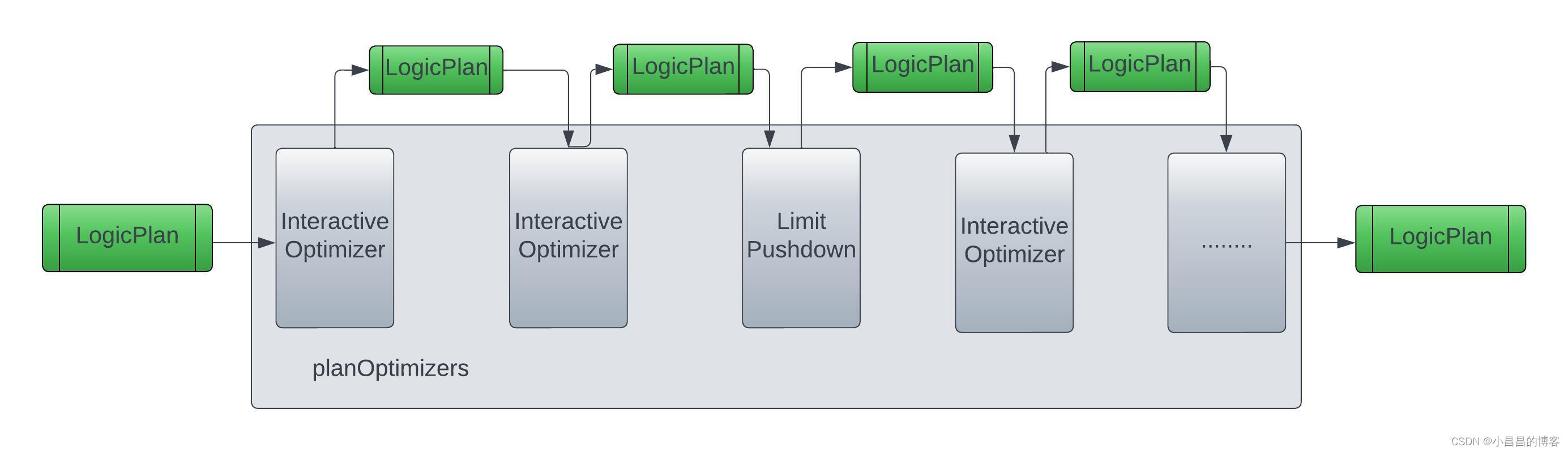
在Presto中,有两种PlanOptimizer的实现方式,
- 一种是常规定义的
Optimizer, 这个Optimizer需要定义自己作为访问者的各种优化方式 - 另外一种叫
IterativeOptimzer, 它和常规Optimizer相比,角色是一模一样的,只是易用性和设计的通用性和扩展性更好,用户只需要专注于自己的优化步骤,定义好对应的Rule,根据Rule去构建IterativeOptmizer,不需要关心所谓的访问者模式等等细节。
常规Optimizer
我们以LimitPushdown这个很常规的Optimizer来讲解优化过程中的调用逻辑。
所有的Optimizer(包括下文的IterativeOptimizer)都是PlanOptimzer的实现类,需要实现方法optimize():
public class LimitPushDown
implements PlanOptimizer
{
@Override
public PlanNode optimize(PlanNode plan, Session session, TypeProvider types, SymbolAllocator symbolAllocator, PlanNodeIdAllocator idAllocator, WarningCollector warningCollector)
{
....
return SimplePlanRewriter.rewriteWith(new Rewriter(idAllocator), plan, null);
}
真正的Visitor角色定义为LimitPushDown中的内部类LimitPushDown.Rewriter, 所有的Visitor都是PlanVisitor的实现类,需要按需重载对应的visit*()方法:
public abstract class PlanVisitor<R, C>
{
protected abstract R visitPlan(PlanNode node, C context);
public R visitRemoteSource(RemoteSourceNode node, C context)
{
return visitPlan(node, context);
}
public R visitAggregation(AggregationNode node, C context)
{
return visitPlan(node, context);
}
....
public R visitTopN(TopNNode node, C context)
{
return visitPlan(node, context);
}
public R visitOutput(OutputNode node, C context)
{
return visitPlan(node, context);
}
可以看到, PlanVisitor中定义了各种visit*()方法,参数为不同的PlanNode类型,比如对OutputNode的visitOutput(), 对TopNNode(Limit Order By) Node的visitTopN()方法等等。
对于任何一种优化器实现,其实只需要根据自己的需要去修改自己所关心的节点类型的visit*()方法即可,比如,对于LimitPushDown的Visitor LimitPushdown.Rewrite, 只实现了visitAggregation(), visitTopNNode(), visitUnion(), visitSemiJoin(), visitLimit()方法,其它visit*()方法都没有进行重写。
IterativeOptimizer
和其它传统的PlanOptimizer接口的实现类相比,IterativeOptimizer也是PlanOptimizer接口的实现类:
public interface Rule<T>
{
/**
* Returns a pattern to which plan nodes this rule applies.
*/
Pattern<T> getPattern();
// 对于一个session,当前的rule是否需要enable
default boolean isEnabled(Session session)
{
return true;
}
/**
Result apply(T node, Captures captures, Context context);
普通的PlanOptimizer实现,比如LimitPushDown, 用户在实现的时候需要自己定义和实现整个Visitor的角色,其实并不很直观。但是,其实这个过程可以抽象为两个步骤:
- 模式匹配: 即,选择自己需要处理的
PlanNode类型,即,我这个优化是针对什么情况发生的。当然,这种匹配可能不仅仅是选择当前的PlanNode类型,有些优化发生的条件更多,比如,只有当前的PlanNode为某种类型、子PlanNode为另外的类型、某些参数满足什么要求,我才能应用这个优化 - 优化:即优化的具体步骤,这个优化的输入是当前自己需要处理的
PlanNode(包括它的子树),输出是优化完毕以后的新的子树。上层调用者会把这个优化完成的新生成的子树挂在到它的父节点上去,从而完成执行计划树的更新
所以,IterativeOptimizer就定义了一系列的Rule, 每个Rule其实就是定义了两件事:
- 我现在要不要运行优化(是否满足条件)
- 运行的步骤(输入执行计划树,输出新的执行计划树)
public interface Rule<T>
{
/**
* Returns a pattern to which plan nodes this rule applies.
*/
Pattern<T> getPattern();
/**
* 对于当前session,这个rule是否需要enable。有一部分rule是可以通过setup Presto的session property来enable或者disable的
* @param session
* @return
*/
default boolean isEnabled(Session session)
{
return true;
}
/**
* 应用这个rule规则
* @param node
* @param captures
* @param context
* @return
*/
Result apply(T node, Captures captures, Context context);
一部分rule是可以通过session property来让用户选择是否需要enable这样的optimizer规则, 比如EliminateCrossJoins, 这个Rule在PlanOptimizers中被封装成一个IterativeOptimizer:
new IterativeOptimizer(
ruleStats,
statsCalculator,
estimatedExchangesCostCalculator,
ImmutableSet.of(new EliminateCrossJoins(metadata))),
public class EliminateCrossJoins
implements Rule<JoinNode>
{ // EliminateCrossJoins只有在满足join()定义的条件时才运行
private static final Pattern<JoinNode> PATTERN = join();
.....
@Override
public boolean isEnabled(Session session)
{
// we run this for cost-based reordering also for cases when some of the tables do not have statistics
JoinReorderingStrategy joinReorderingStrategy = getJoinReorderingStrategy(session);
return joinReorderingStrategy == ELIMINATE_CROSS_JOINS || joinReorderingStrategy == AUTOMATIC;
......
}
public static Pattern<JoinNode> join()
{
return typeOf(JoinNode.class);
}
大多数情况下,一个IterativeOptimizer封装了一个或者多个Rule.
IterativeOptimizer在构造的时候,会构造一个叫做memo的内存结构, memo中有一系列的Group,每一个Group对应了一个PlanNode.
PlanNode之间的依赖关系的反向关系(从child到parent)通过不同Group之间的incomingReference 来体现。
由于PlanNode与 Group一一对应,因此, 定义了一个GroupReference,作为每一个PlanNode的source,维系PlanNode之间的依赖关系的正向关系。
memo的内存结构如下图所示:
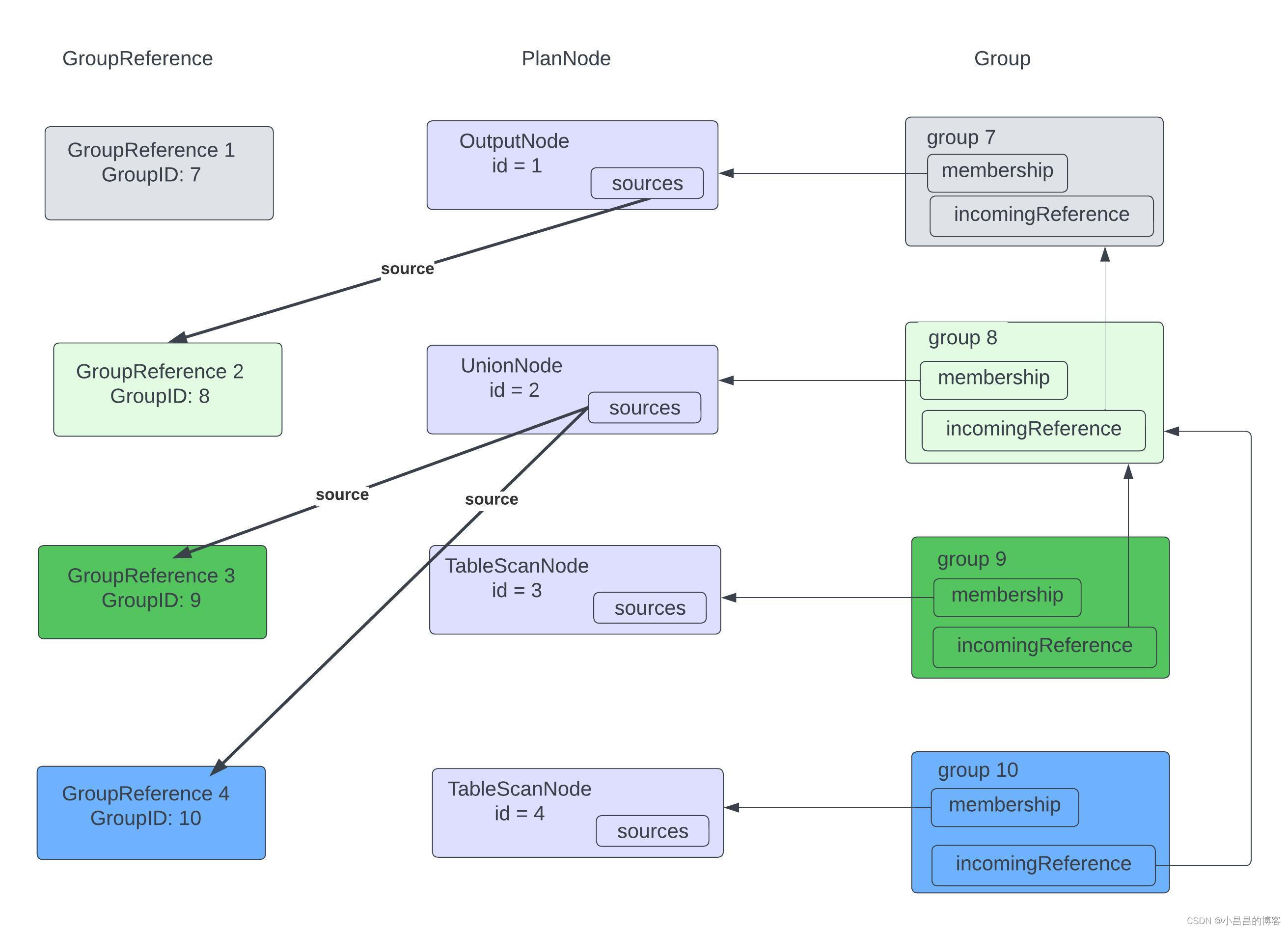
在优化过程中,会从rootGroup开始递归遍历,对于任何一个PlanNode, 遍历该IterativeOptimizer的所有Rule, 根据该Rule的pattern是否match当前的PlanNode以及其它上下文,如果match, 就应用该rule,获取一个优化以后的子树,然后更新Group中的PlanNode为新的PlanNode。
在apply过程中,一些旧的PlanNode被替换和删除,Group中维护的反向依赖关系incomingReference会被同步更新,直到有些Group到incomingReference被清空,说明该Group已经被完全清除。
当整个执行计划树执行完毕,即该IterativeOptimizer执行完毕,就会重新从 rootGroup开始, dump出来优化完成的整个执行计划树。
SELECT country
FROM hive.default.zipcodes_orc_flat
UNION ALL
SELECT country
FROM hive.default.zipcodes_orc_partitioned;
private boolean exploreNode(int group, Context context)
{
PlanNode node = context.memo.getNode(group);
boolean done = false;
boolean progress = false;
while (!done) {
done = true;
// 根据构建对rule index信息,获取当前node需要check的rules
Iterator<Rule<?>> possiblyMatchingRules = ruleIndex.getCandidates(node).iterator();
while (possiblyMatchingRules.hasNext()) {
Rule<?> rule = possiblyMatchingRules.next();
if (!rule.isEnabled(context.session)) {
continue;
}
Rule.Result result = transform(node, rule, context);
if (result.getTransformedPlan().isPresent()) { // 如果存在TransformedPlan, 那么就根据TransformedPlan重新构建
node = context.memo.replace(group, result.getTransformedPlan().get(), rule.getClass().getName());
done = false;
progress = true; // progress 为true,说明有变化,那么,也许这个group的children需要重新来一次
}
}
}
return progress;
}
优化后的逻辑执行计划如下图:

public enum Scope
{
LOCAL,
REMOTE
}
......
对于`ExhangeNode.Type`:
* **GATHER**
* 即数据exchange时的target 节点是唯一一个节点,比如:
* 分布式计算结果输出到最终的`Coordinator`, 这属于`Gather Exchange`
* 其它的一些计算结果需要全部在一台机器上汇集的情况
* **REPARTITION**
* 根据一些partition规则来确定任何一个split需要exchange的target node。比如,`select count(*) from tb group by key`这样的聚合操作,需要根据key的hash值来确定target node,这过过程就是repartition的过程。或者,join操作,也需要根据join key的hash值来确定target node。
* **REPLICATE**
* 即通过REPLICATE的方式将当前数据完整拷贝到其它所有节点,特别类似Spark 的`map side join`. 在Presto运行过程中,大表和小表的join,如果小表特别小,完全可以塞进一台机器上,那么,这时候使用`REPLICATE join`会特别高效。
对于`ExhangeNode.Scope`:
* **LOCAL**
* Task执行阶段会遇到了`LOCAL ExchangeNode`, 那么会对`Remote Exchange`发送过来的数据来进行一些预聚合计算,并合理设置并发。
* **REMOTE**
* 代表这是一次跨越节点的exchange。后续的执行计划分段就是根据`Remote Exchange`来作为切分点,将优化以后的逻辑执行计划进行分段 。
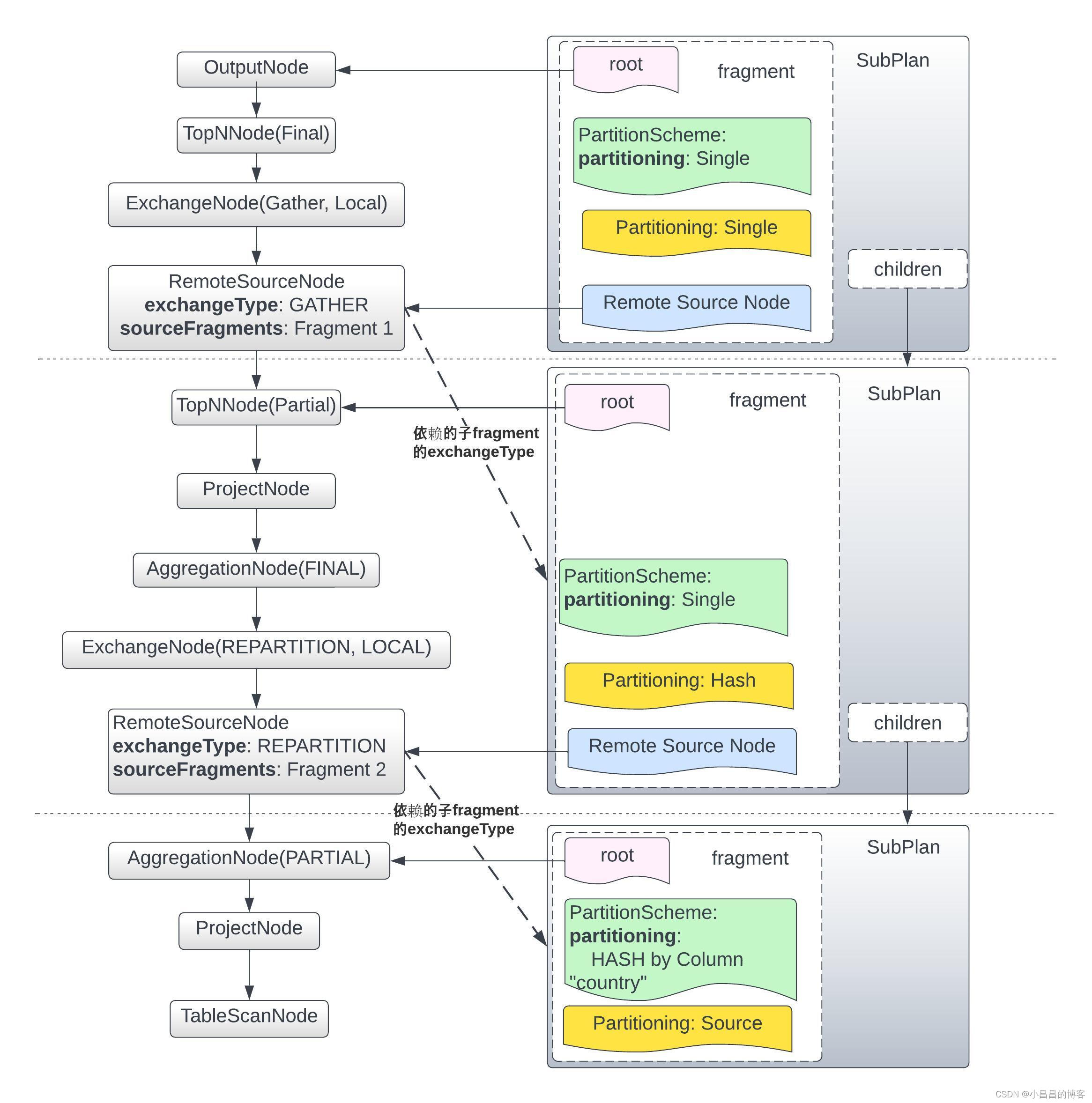
## 2.5 逻辑执行计划分段
逻辑执行计划分段就是根据上面已经生成的`ExchangeNode`, 以`Scope=Remote`的`ExchangeNode`作为切分点分`fragment`。在后续的物理执行计划生成过程中,**每一个Fragment和物理执行计划的Stage是严格一一对应的关系**。
其实,对执行计划分段跟前面提到的`PlanOptimizer`一样,都是对执行计划树的修改过程,因此,对逻辑执行计划分段也是基于`Visitor`模式,这里的`Visitor`是`PlanFragmenter.Fragmenter`:
```java
private static class Fragmenter
extends SimplePlanRewriter<FragmentProperties>
{
private static final int ROOT_FRAGMENT_ID = 0;
private final Session session;
private final Metadata metadata;
......
分段的核心步骤是找到 Scope为Remote的ExchangeNode,以该节点为切割点进行分段。我们可以看Fragmenter.visitExchange()方法的实现:
@Override
public PlanNode visitExchange(ExchangeNode exchange, RewriteContext<FragmentProperties> context)
{
if (exchange.getScope() != REMOTE) { // Local Exchange是不会做特殊处理,不分stage
return context.defaultRewrite(exchange, context.get());
}
PartitioningScheme partitioningScheme = exchange.getPartitioningScheme();
if (exchange.getType() == ExchangeNode.Type.GATHER) {
context.get().setSingleNodeDistribution();
}
else if (exchange.getType() == ExchangeNode.Type.REPARTITION) {
context.get().setDistribution(partitioningScheme.getPartitioning().getHandle(), metadata, session);
}
// 可以看到,当发现逻辑之行计划里面有ExchangeNode的时候,就会为这个ExchangeNode的每一个source构建一个subPlan
ImmutableList.Builder<SubPlan> builder = ImmutableList.builder();
for (int sourceIndex = 0; sourceIndex < exchange.getSources().size(); sourceIndex++) {
FragmentProperties childProperties = new FragmentProperties(partitioningScheme.translateOutputLayout(exchange.getInputs().get(sourceIndex)));
builder.add(buildSubPlan(exchange.getSources().get(sourceIndex), childProperties, context));
}
List<SubPlan> children = builder.build();
context.get().addChildren(children);
List<PlanFragmentId> childrenIds = children.stream()
.map(SubPlan::getFragment)
.map(PlanFragment::getId)
.collect(toImmutableList());
// 将ExchangeNode变成RemoteSourceNode
return new RemoteSourceNode(exchange.getId(), childrenIds, exchange.getOutputSymbols(), exchange.getOrderingScheme(), exchange.getType());
}
从上面的代码可以看到:
- 从整个执行计划树的root节点(通常为
OutputNode节点)开始遍历,直到遇到了以Scope=Remote的ExchangeNode, 以该节点作为切割点,切分fragment,将这个Scope=Remote的ExchangeNode转换成一个RemoteSourceNode, 作为这个Fragment的最底层节点,即接收上游Fragment传过来的exchange 数据。 - 对于
Scope=Remote的ExchangeNode的一个或者多个source节点,递归对每一个source创建对应的子Fragment - 一个
fragment用一个PlanFragment的实例来表示 - 一个
SubPlan对象封装了一个fragment,同时通过children维护了父子fragment之间的关系
对上文中的SQL执行完fragment以后的执行计划如下图所示: