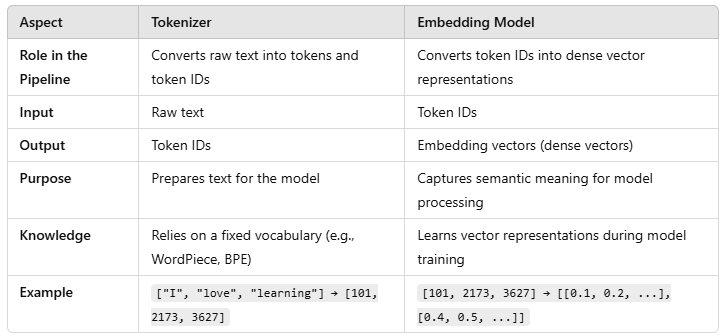
在大模型训练和推理中,显卡(GPU/TPU)的选择与模型参数量紧密相关,需综合考虑显存、计算能力和成本。以下是不同规模模型与硬件的匹配关系及优化策略:
一、参数规模与显卡匹配参考表
| 模型参数量 | 训练阶段推荐显卡 | 推理阶段推荐显卡 | 关键限制因素 |
|---|---|---|---|
| 1B以下 | 1-2×RTX 4090 (24GB) | 1×RTX 3090 (24GB) | 显存容量 |
| 1B-7B | 4-8×A100 40GB | 1×A10G (24GB) | 显存+计算单元 |
| 7B-70B | 16-64×H100 80GB + NVLink | 2-4×A100 80GB | 多卡通信带宽 |
| 70B-1T | 数百张H100 + InfiniBand集群 | 8×H100 + TensorRT-LLM | 分布式训练框架稳定性 |
二、关键硬件指标解析
1. 显存需求计算
模型显存占用 ≈ 参数显存 + 激活值显存 + 优化器状态
- 参数显存:
- FP32参数:每10亿参数 ≈ 4GB
- FP16/BF16:每10亿参数 ≈ 2GB
- 优化器状态(以Adam为例):
- 每参数需存储参数、动量、方差 → 额外12字节/参数
- 70B模型优化器状态 ≈ 70×12 = 840GB
示例:
训练7B模型(FP16)最低显存需求:
7×2GB (参数) + 7×12GB (优化器) + 激活值 ≈ 100GB → 需多卡分布式训练
2. 计算能力需求
- TFLOPS利用率:
- A100 FP16算力:312 TFLOPS
- H100 FP16算力:756 TFLOPS
- 吞吐量估算:
70B模型在8×H100上约生成 50 token/s(使用vLLM优化)
三、训练阶段的硬件策略
1. 单卡小模型(<7B)
- 配置示例:
- 显卡:A6000 (48GB)
- 技术:梯度累积(batch=4时累积8步)
- 框架:PyTorch + FSDP
# FSDP自动分片示例
from torch.distributed.fsdp import FullyShardedDataParallel
model = FullyShardedDataParallel(model)
2. 多卡中大模型(7B-70B)
- 推荐方案:
- 8-32×A100/H100 + NVLink
- 并行策略:
- Tensor并行:拆分权重矩阵(Megatron-LM)
- Pipeline并行:按层分片(GPipe)
- 数据并行:多副本数据分片
# 启动Megatron-LM训练
python -m torch.distributed.launch --nproc_per_node=8 pretrain_gpt.py \
--tensor-model-parallel-size 4 \
--pipeline-model-parallel-size 2
3. 超大规模(>70B)
- 基础设施:
- 超算集群(如Microsoft的NDv5实例:8×A100 80GB/节点)
- 通信优化:InfiniBand + 3D并行(数据+Tensor+Pipeline)
四、推理阶段的硬件优化
1. 量化技术节省显存
| 量化方法 | 显存压缩比 | 精度损失 | 适用场景 |
|---|---|---|---|
| FP16 | 2x | 可忽略 | 通用推理 |
| INT8 | 4x | <1% | 对话机器人 |
| GPTQ-4bit | 8x | 1-3% | 边缘设备部署 |
示例:
70B模型原始显存需求(FP16):140GB → GPTQ-4bit后仅需17.5GB
2. 推理加速框架
- vLLM:PagedAttention实现高吞吐
python -m vllm.entrypoints.api_server --model meta-llama/Llama-3-70b --quantization awq - TensorRT-LLM:NVIDIA官方优化
from tensorrt_llm import builder builder.build_llm_engine(model_dir="llama-70b", dtype="float16")
五、成本对比分析
| 显卡型号 | 单卡价格 | 适合模型规模 | 每10亿参数训练成本* |
|---|---|---|---|
| RTX 4090 | $1,600 | <3B | $0.8/hr |
| A100 40GB | $10,000 | 3B-20B | $3.2/hr |
| H100 80GB | $30,000 | 20B-1T | $8.5/hr |
*基于AWS p4d.24xlarge实例估算
六、选型建议
-
初创团队:
- 7B以下模型:A10G(推理)/ A100 40GB(训练)
- 使用LoRA微调减少显存需求
-
企业级部署:
- 70B模型:H100集群 + vLLM服务化
- 采用Triton推理服务器实现动态批处理
-
学术研究:
- 租用云GPU(Lambda Labs / RunPod)
- 使用Colab Pro+(有限制)
关键结论
- 7B是分水岭:单卡可推理,多卡才能训练
- H100性价比:对于>20B模型,其NVLink带宽(900GB/s)远优于A100(600GB/s)
- 未来趋势:B100/B200发布后将进一步降低大模型硬件门槛
实际部署前,建议使用NVIDIA DGX Cloud进行性能测试。