前言
文章目录
- 前言
- 1.集成Nacos实现服务的自动注册与发现
- 2. Feign负载均衡
- 注:OpenFeign和Feign的区别:
- 3.使用Sentinel实现了接口的限流
- 4.Feign整合Sentinel实现容错
- 5.API网关
- 6.Sleuth整合ZipKin实现链路追踪
- 7.消息队列MQ
spring cloud是一个基于springboot实现的微服务架构开发工具,使用springcloud框架进行微服务业务开发是java后端开发必备技能,目前主流的SpringCloud分为SpringCloud Netflix和阿里云开源的SpringCloud Alibaba两个系列,由于博主一直用的是springcloud alibaba,所以本文以此为例总结一下SpringCloud Alibaba都有哪些组件及各自的作用。本文非实战文章,但是参考了冰河老师的《SpringCloud Alibaba实战》一书。
1.集成Nacos实现服务的自动注册与发现
如果系统采用了微服务的架构模式,随着微服务数量的不断增多,服务之间的调用关系会变得纵横交错,需要引入服务治理的功能。服务治理也是在微服务架构模式下的一种最核心和最基本的模块,主要用来实现各个微服务的自动注册与发现。能够实现注册中心功能的组件有:Zookeeper、Eureka、Consul、Etcd、Nacos等。SpringCloud Alibaba框架用的是nacos。
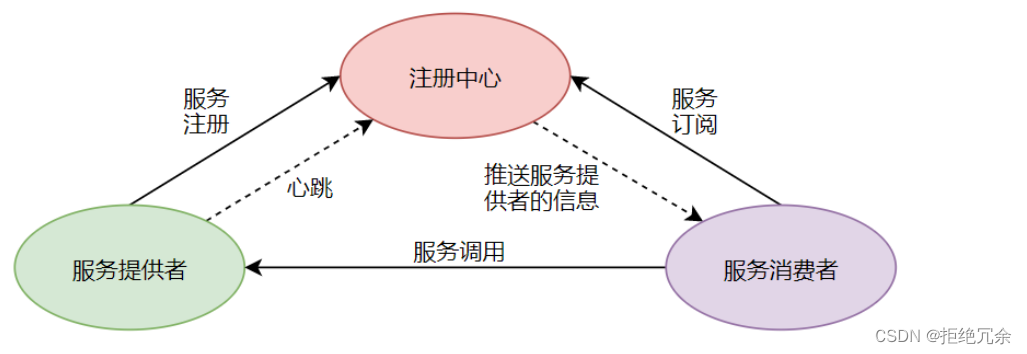
Nacos除了提供服务注册与发现功能外,还有一个重要功能是作为配置中心统一管理各服务的配置数据。集成nacos后只需要在application.yml文件中加入nacos配置即可,其余的配置加到nacos中,可以在线编辑修改发布,不需要重启对应的服务。
2. Feign负载均衡
Ribbon负载均衡是使用RestTemplate加上@loadBalance注解就可以通过服务名加上负载均衡策略去调用远程的服务。
但是这样实现的负载均衡仍然需要在业务代码中调用远程接口,有点low。OpenFeign组件是这种负载均衡实现方式的升级,面向接口编程,也就是说,咱们把注册中心中每一个服务都以一个接口的形式体现。
@FeignClient注解把一个庞大的微服务抽象成了一个接口,@FeignClient(value = “xxxxx”)中的value 属性具体指定是哪个微服务。
那么OpenFeign底层会帮我们通过微服务的服务名去获取到我们最关心的服务IP+Port,然后通过接口中的方法上配的@GetMapping(“/xxx/xxx”)来定位到具体方法。我们服务的消费者只需要调用这个接口中的方法,配合Ribbon使用,那么底层就会自动的调用远方的服务,负载均衡策略默认使用的是Ribbon中的轮询机制。
注:OpenFeign和Feign的区别:
Feign是SpringCloud中的一个轻量级RestFul的Http客户端,内置了Ribbon,用于客户端负载均衡,使用方法是使用Feign的注解去修饰一个接口,客户端调用这个接口那么久是调用远程的微服务了。
OpenFeign在Feign的基础上支持了SpringMVC的注解,如@RequestMapping等。OpenFeign的@FeigenClient注解可以解析SpringMvc的@RequestMapping注解下的接口,通过动态代理的方式产生实现类,实现类中进行负载均衡的微服务远程调用!
3.使用Sentinel实现了接口的限流
Sentinel 从流量控制、熔断降级、系统负载保护等多个维度保护服务的稳定性,它分为两个部分:
- 核心库(Java 客户端)不依赖任何框架/库,同时对 Dubbo / Spring Cloud 等框架也有较好的支持,整合时在项目的pom.xml文件中引入Sentinel的依赖即可。
- 控制台(Dashboard)基于 Spring Boot 开发,从官网下载的是后台打好的jar包,可以直接运行,不需要额外的 Tomcat 等应 用容器。
集成sentinel的服务中接口被调用后,可以从sentinel控制台看到它自动拦截到了每个接口,点击该接口就可以进行各种限流配置,如设置QPS阈值、并发流程数等。
注意:因为Sentinel是懒加载机制,所以需要访问一下接口,再去访问Sentinel 才有数据,并不是直接启动Sentinel就有的。

4.Feign整合Sentinel实现容错
系统中微服务数量较多时可能发生某些服务中断或者访问异常的情况,导致其他调用此服务的微服务也出现异常,从而系统可能出现不可用的情况,所以有必要添加服务容错机制。具体实现方式是在微服务中添加sentinel依赖并在Feign中增加如下配置:
feign:
sentinel:
enabled: true
容错类需要实现一个被容错的接口,并实现这个接口的方法,比如要为userService中的方法容错就要先建一个容错类userServiceFallBack类实现UserService接口,接口方法具体实现是userService服务中断或异常后的处理逻辑,比如返回各默认的对象等。接下来,在被远程调用的微服务的UserService 接口上的@FeignClient注解上指定容错类,如下所示。
@FeignClient(value = “server-user”, fallback = UserServiceFallBack.class)
这样在调用加了FeignClient注解的类接口时就会触发此微服务的容错逻辑。
5.API网关
API网关,其实就是整个系统的统一入口。网关会封装微服务的内部结构,为客户端提供统一的入口服务,同时,一些与具体业务逻辑无关的通用逻辑可以在网关中实现,比如认证、授权、路由转发、限流、监控等。目前,比较主流的API网关有:Nginx+Lua、Kong网关、Zuul网关(Netflix开源的网关)、Apache Shenyu网关、SpringCloud Gateway网关。SpringCloud Alibaba技术栈中,并没有单独实现网关的组件,一般使用SpringCloud Gateway实现网关功能。
客户端请求到 Gateway 网关,会先经过 Gateway Handler Mapping 进行请求和路由匹配。匹配成功后再发送到 Gateway Web Handler 处理,然后会经过特定的过滤器链,经过所有前置过滤后,会发送代理请求。请求结果返回后,最后会执行所有的后置过滤器。
在实际应用中,我们可以增加一个网关微服务,然后集成nacos服务,这样就能通过网关端口来统一访问注册到nacos中的其他微服务,也可以集成Sentinel在网关服务中实现限流。
6.Sleuth整合ZipKin实现链路追踪
为什么要实现链路跟踪?单体架构中可以使用AOP在调用具体的业务逻辑前后分别打印一下时间即可计算出整体的调用时间,使用 AOP捕获异常也可知道是哪里的调用导致的异常。但是在分布式微服务场景下,使用AOP技术是无法追踪到各个微服务的调用情况的,也就无法知道系统中处理一次请求的整体调用链路。
每个微服务只需要添加Sleuth的依赖,就可以在命令行查看链路追踪情况。
- Sleuth支持抽样采集数据。尤其是在高并发场景下,如果采集所有的数据,那么采集的数据量就太大了,非常耗费系统的性能,通常的做法是可以减少一部分数据量,配置如下:
sleuth:
enabled: true
sampler.percentage: 1.0 #request采样率
- Sleuth支持对异步任务的链路追踪,在项目中使用@Async注解开启一个异步任务后,Sleuth会为异步任务重新生成一个Span。
在实际项目中通过查看日志的情况来了解系统调用的链路情况效率太差了,一般会将Sleuth和ZipKin进行整合,利用ZipKin将日志进行聚合,将链路日志进行可视化展示,并支持全文检索。Zipkin总体上分为服务端和客户端,我们需要下载并启动ZipKin服务端的Jar包(默认监听的端口号为9411),在各微服务中集成ZipKin的客户端(添加ZipKin依赖)。
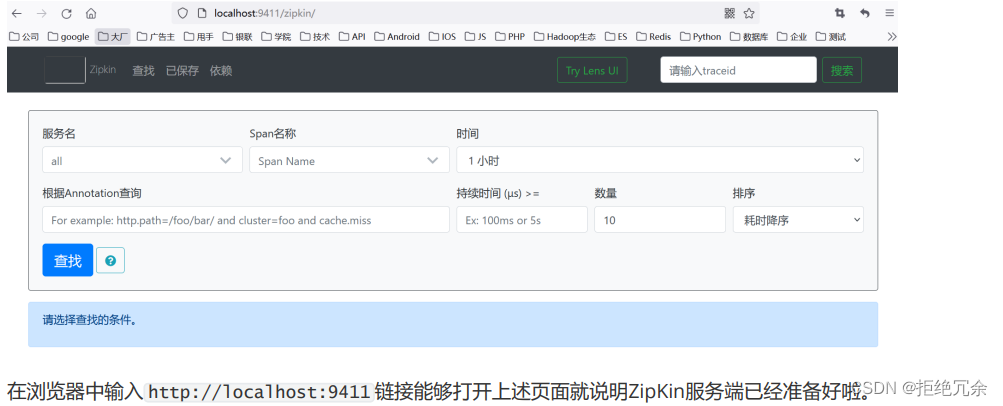
通过ZipKin能够查看服务的调用链路,并且能够查看分析具体微服务的调用情况,找出系统的瓶颈点,进而进行针对性的优化。另外,ZipKin中也支持下载系统调用链路的Json数据,可以将数据保存到ElasticSearch、Cassandra或者MySQL中。
7.消息队列MQ
通过消息队列,我们可以实现多个进程之间的通信,例如,可以实现多个微服务之间的消息通信。MQ的最简模型就是生产者生产消息,将消息发送到MQ,消息消费者订阅MQ,消费消息。使用的比较多的MQ包含RabbitMQ、Kafka和RocketMQ。
引入MQ最大的优点就是异步解耦和流量削峰,但是引入MQ后也有很多需要注意的事项和问题,主要包括:系统的整体可用性降低、系统的复杂度变高、引入了消息一致性的问题。
博主的项目规模较小,应甲方要求集成了kafka,应用场景比较单一:当某个业务流程启动、审批或者结束时将审批信息推送给移动端开发团队/接收上级单位组织或人员变动消息。具体可参考以前文章:Windows环境单节点部署kafka最新版本3.2.1实战(超简单)