文章目录
- A Brief History of Topic Models
- Latent Dirichlet Allocation (LDA)潜在狄利克雷分布
- 核心思想
- LDA input
- LDA output
- LDA 如何学习
- Sampling-based mothods 基于采样的方法
- Variational methods 变分方法
- Evaluation




主题建模(Topic Modeling)是一种统计模型,用于在一组文档中发现抽象的"主题"。主题可以看作是一种潜在的变量,能够捕获文档中的主要讨论点。
比如,你有一堆新闻文章,通过主题建模,可能可以发现一些主题,如"国际政治",“经济”,“体育”,“娱乐"等。每个主题都由一组与之相关的关键词定义。例如,“体育”主题可能包括"篮球”,“足球”,"奥运会"等词语。
最常见的主题建模方法是潜在Dirichlet分配(LDA),它假设每个文档都是从多个主题的混合体中生成的,而每个主题则是从一组特定的词语分布中生成的。
主题建模在文本挖掘、自然语言处理和信息检索等领域有广泛的应用,可以用来探索大规模文本集合的隐藏结构,帮助我们更好地理解和解释文本数据。
A Brief History of Topic Models
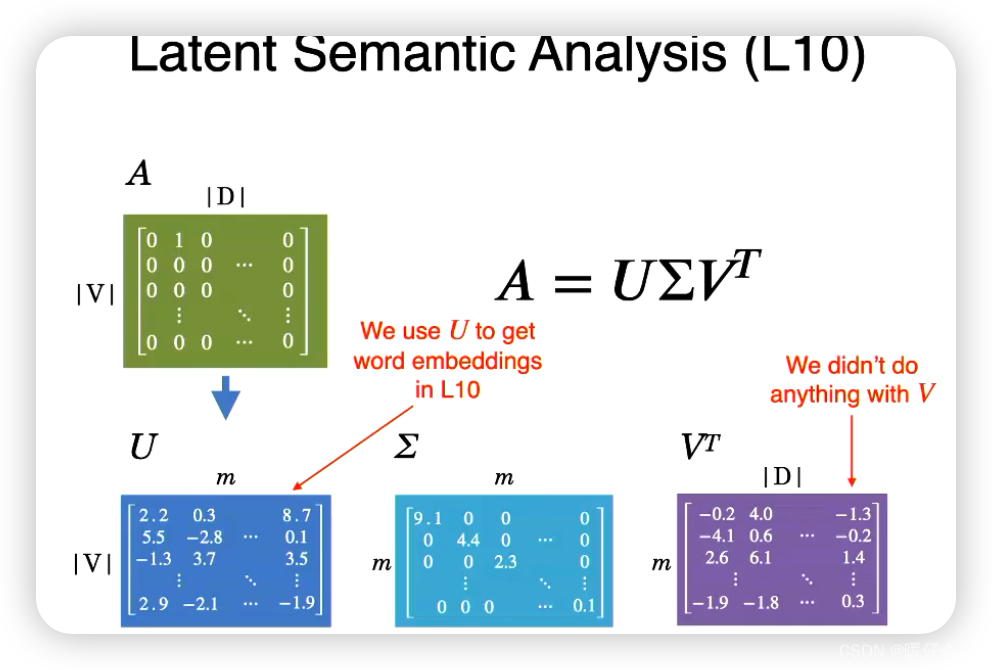
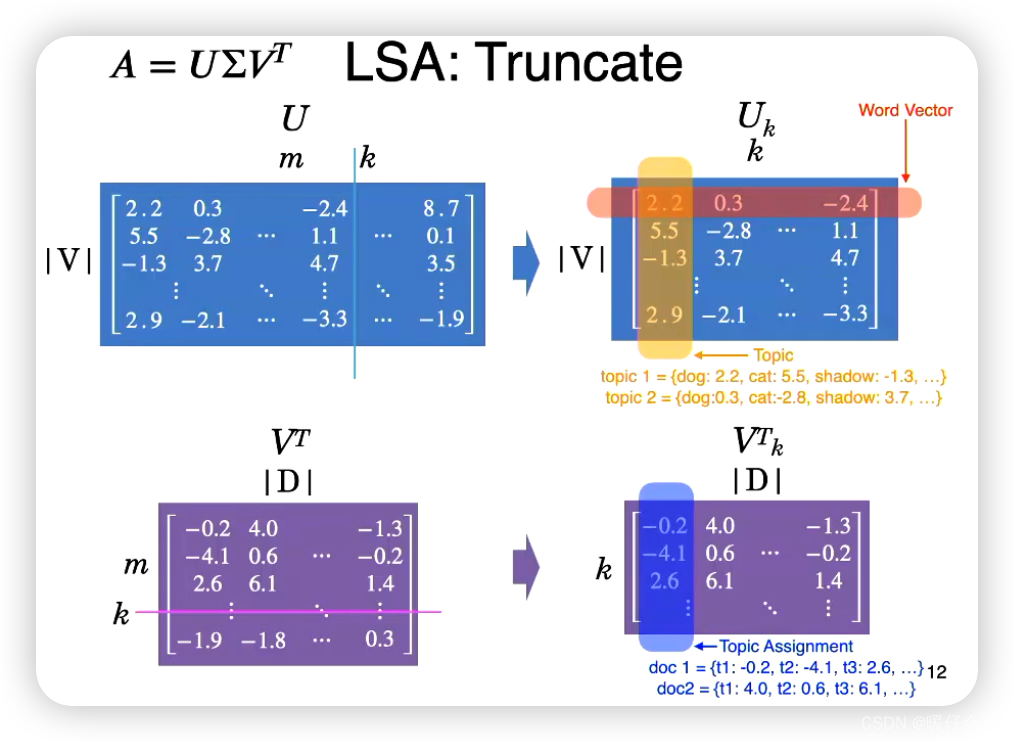



Latent Dirichlet Allocation (LDA)潜在狄利克雷分布
- 一种用于主题模型的生成概率模型,通过对文档中的词汇进行概率分布分析,从而发现文档中的潜在主题。

核心思想

Latent Dirichlet Allocation(LDA)是一种主题模型,它允许观察到的一组文档可以被解释为潜在主题的集合。 这是一种无监督的生成模型,使我们能够确定由哪些主题生成了一篇特定的文档,并能确定每个主题的词分布。
LDA的基本思想是:
-
每一篇文档都可以被看作是一系列主题的混合,而每一个主题又可以被看作是一系列词的混合。 例如,如果我们有一个关于体育的文档,那么可能的主题包括"篮球"、“足球”、“棒球"等,每个主题都有各自的词汇,如"投篮”、“射门”、"跑垒"等。
-
LDA算法通过反复迭代来学习
主题-词分布和文档-主题分布,最终可以为每个文档提供一个主题分布(告诉我们这篇文档关于哪些主题),并为每个主题提供一个词分布(告诉我们每个主题包含哪些关键词)。
LDA广泛用于自然语言处理、信息检索和机器学习等领域,用于文档分类、情感分析、推荐系统等任务。
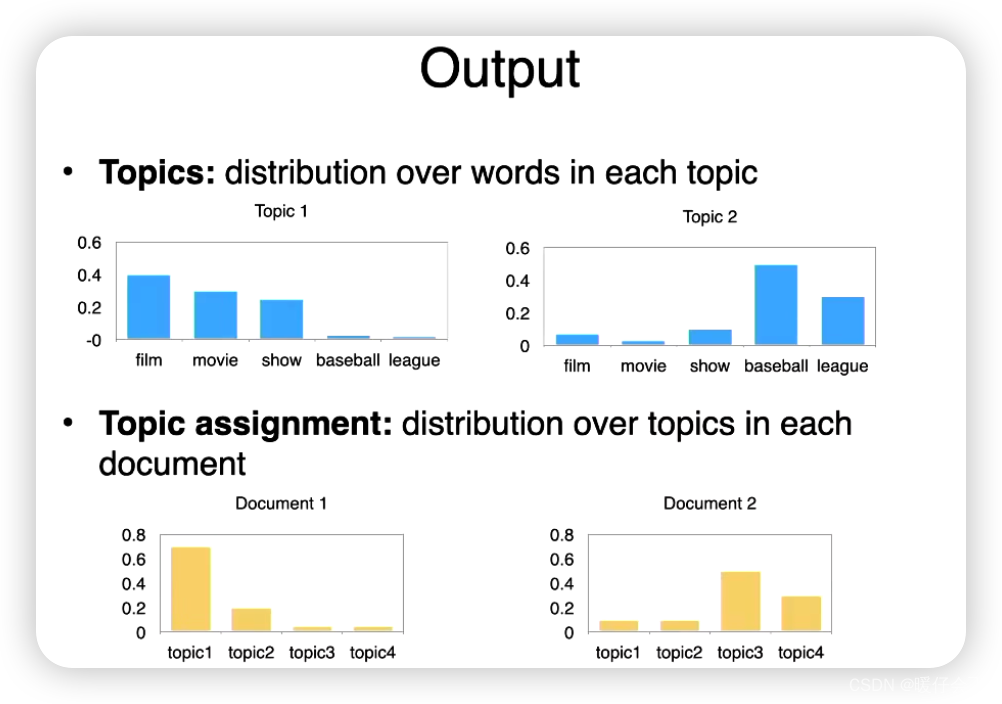
LDA input

LDA output
LDA 如何学习

Sampling-based mothods 基于采样的方法

- 蓝色的表格用于统计
topic-word共同出现的情况 - 绿色的表格用于统计
document-topic共同出现的情况 - 蓝色的表格中的数据一开始都被初始化为
0.01,绿色的则都是0.1 - 这些初始化的数据被称为
prior先验 - 之所以以这样的方式初始化,是因为我们为了
smooth结果,避免在计算的过程中出现0 - 看蓝色表格左上角的
mouse-t1为1.01其实1.01 = 1 + 0.01,除了初始值之外,因为在橙色的表格中,mouse和t1共同出现了1次,所以这里得到了1.01 - 同样的
moust-t3=2.01 - 其他的表格单元也都如法炮制
- 填完了蓝色和绿色的表格之后,进行下一步
- 那就是遍历所有的
word token然后 sample 一个新的 topic,这个步骤是根据这两个表格来决定的:

- 其中 P ( t i ∣ w ) P(t_i|w) P(ti∣w) 是从蓝色表格计算出来的, P ( t i ∣ d ) P(t_i|d) P(ti∣d) 是根据绿色表格计算出来的
- 需要注意的是:需要在采样前取消当前主题分配并更新共现矩阵
在Gibbs采样中,为什么在采样前要取消当前的主题分配并更新共现矩阵呢?这是因为我们正在尝试从一个条件分布中抽取样本,即在给定其他所有单词的主题分配情况下,当前单词的主题分配。
- 当我们尝试更新一个特定单词的主题时,我们先要**“去除”或取消这个单词当前的主题分配**,这样才能确保这个单词的新主题分配不会被它自己当前的分配影响。只有在这个单词“看不见”自己当前的主题分配的情况下,我们才能得到一个公正的抽样。
- 同时,取消当前的主题分配也意味着我们需要更新主题-词(topic-word)和文档-主题(document-topic)的共现矩阵,因为这个单词的主题分配已经改变,所以之前基于旧的主题分配得到的共现矩阵已经不再准确。一旦我们有了更新后的共现矩阵,我们就可以基于当前其他所有单词的主题分配,从该单词的主题的条件分布中抽取新的主题标签。
- 总的来说,这个过程确保了我们在给定其他所有变量的情况下,公正地从一个变量的条件分布中抽取样本,这是Gibbs采样的基本要求。

- 根据上面的条件,我们现在对
mouse单词重新分配主题的时候,需要将原本属于的主题进行de-allocate所以在mouse-t1这个单元中要-1,同样的,在t1-doc的矩阵中的对应位置也需要把这个值-1(就相当于橙色的表格中这个mouse的topic=?所以不能将mouse所在的t1再作为绿色表格的有效数据统计进去了)

- 接下来就是将
P
(
t
i
∣
w
)
P
(
t
i
∣
d
)
P(t_i|w)P(t_i|d)
P(ti∣w)P(ti∣d) 计算出来即可,例如
P
(
t
1
∣
m
o
u
s
e
,
d
1
)
=
P
(
t
1
∣
m
o
u
s
e
)
P
(
t
1
∣
d
1
)
P(t_1|mouse, d_1) = P(t_1|mouse)P(t_1|d_1)
P(t1∣mouse,d1)=P(t1∣mouse)P(t1∣d1),我们根据这个公式可以计算出来 mouse 与
t
1
,
t
2
,
t
3
t_1,t_2, t_3
t1,t2,t3 哪种 topic 更加契合,然后将
mouse分配给这种topic - 重复上面的步骤,不断更新表格直到收敛
- 再举个例子:计算
P
(
t
3
∣
m
o
u
s
e
,
d
1
)
P(t_3|mouse, d_1)
P(t3∣mouse,d1)
P ( t 3 ∣ m o u s e , d 1 ) = P ( t 3 ∣ m o u s e ) P ( t 3 ∣ d 1 ) P(t_3|mouse, d_1)=P(t_3|mouse)P(t_3|d_1) P(t3∣mouse,d1)=P(t3∣mouse)P(t3∣d1) - 原本以为应该按照下面的方式将这个
t3-mouse也减去 1,但是事实上这样是不对的

- 因为我们现在正在对
t1-mouse进行 reassign,所以我们只需要在t1-mouse相关的蓝色和 绿色格子中减去即可,至于t3-mouse我们正常计算即可,所以计算如下:
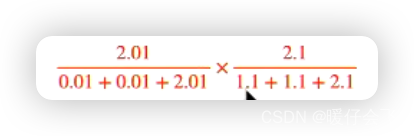

Infer Topics For New Documents
- 在推理阶段,我们固定蓝色表格,只是更新绿色表格

超参数



Variational methods 变分方法
Evaluation
主题模型(例如LDA)的评估是一项重要的任务,主要有两种评估方法:内在评价(Intrinsic Evaluation)和外在评价(Extrinsic Evaluation)。
内在评价:内在评价主要通过计算模型的困惑度(Perplexity)、主题一致性(Topic Coherence)等指标来评价模型的性能。
-
困惑度 Perplexity:困惑度是评估主题模型质量的一种常见指标。困惑度越低,模型的性能越好。困惑度基本上度量了模型对未见过的新数据的预测能力,即模型的泛化能力。
-
主题一致性 Topic Coherence:主题一致性是另一种常用的评价指标,它度量的是一个主题内部的词语是否在语义上相互关联。主题一致性越高,说明主题模型捕捉到的主题越有意义。
外在评价:外在评价主要是看主题模型在一些下游任务上的性能,例如文档分类、文档聚类、信息检索等。 比如,我们可以使用主题模型对文档进行特征提取,然后在这些特征上训练一个分类器或者聚类算法,通过观察分类器或者聚类算法的性能来评估主题模型的质量。







![栈的运用——中缀表达式[Java实现]](https://img-blog.csdnimg.cn/c10f2957019340e49a611ecf965364c9.png)




![[PyTorch][chapter 40][CIFAR-10 数据集]](https://img-blog.csdnimg.cn/da55e8aaee3b4fdb8bb36d450ba704ba.png)