流批一体的内涵
流批一体中的“流批”是指流处理与批处理,是两种不同的数据处理方式,而不是对数据种类的划分。具体来说,数据可以按产生的时间划分为历史数据与实时数据,亦可按数据的明细程度分为流水数据与切片数据;数据处理方式按窗口大小可分为流式处理与批式处理,亦可按处理时延分为实时处理与离线处理。
流批一体包括两方面内涵: 1、计算一体:同一套计算逻辑可以同时应用于流处理与批处理两种模式,且在最终结果上一致。 2、存储一体:流处理与批处理过程中全程数据存储在同一介质,即不管采用何种处理模式,数据的流转及存储都在同一介质中完成。
流批一体式数仓
本小节将揭示流批一体的必要性,引出流批一体数仓概念以及实现流批一体化的手段。 先从经典Lambda架构谈起,Lambda架构同时支持实时流计算与离线批处理,该架构有两条数据通道,一条是实时的,通常采用消息系统结合实时流处理系统实现指标的实时计算,比如采用kafka&Flink的开源组合,kafka负责存储流水数据及处理过程中产生的中间结果,Flink消费数据实时计算指标;另一条通道是非实时的,数据定时同步到仓库,再通过批处理方式计算数仓分层数据模型。Lambda架构既支持流式数仓又能满足离线数仓的计算要求,但存在以下缺点:
1、同一数据两份存储。一份用于实时流计算,一份用于离线批处理,不仅耗费资源,还难以保证数据一致性;
2、同一计算逻辑两套代码。面对指标的实时计算,Lambda架构需要分别以流处理与批处理方式各实现一次,其中流式逻辑满足实时性要求,而最终则以批处理结果为准。
3、需要集成多种组件支持不同类型的应用。比如集成elasticsearch支持即席查询,postgresql支持复杂统计分析等,导致整体架构与技术栈更加复杂,学习及维护成本高。
Lambda架构的出现是由于受到了存储系统与计算框架的限制,一方面没有一个存储系统既能支持数据实时读写又能有效进行高吞吐、低延时的批处理,这就导致数据需要写入实时存储系统以支持流处理系统实时计算,进而适应大屏展示等应用,同时还要持久化到类似HIVE、postgresql等支持即席查询、统计分析的存储系统中;另一方面,计算框架存在处理数据时无法保证exactly-once、乱序等问题,计算结果会有偏差,仍需要用批处理结果校正。
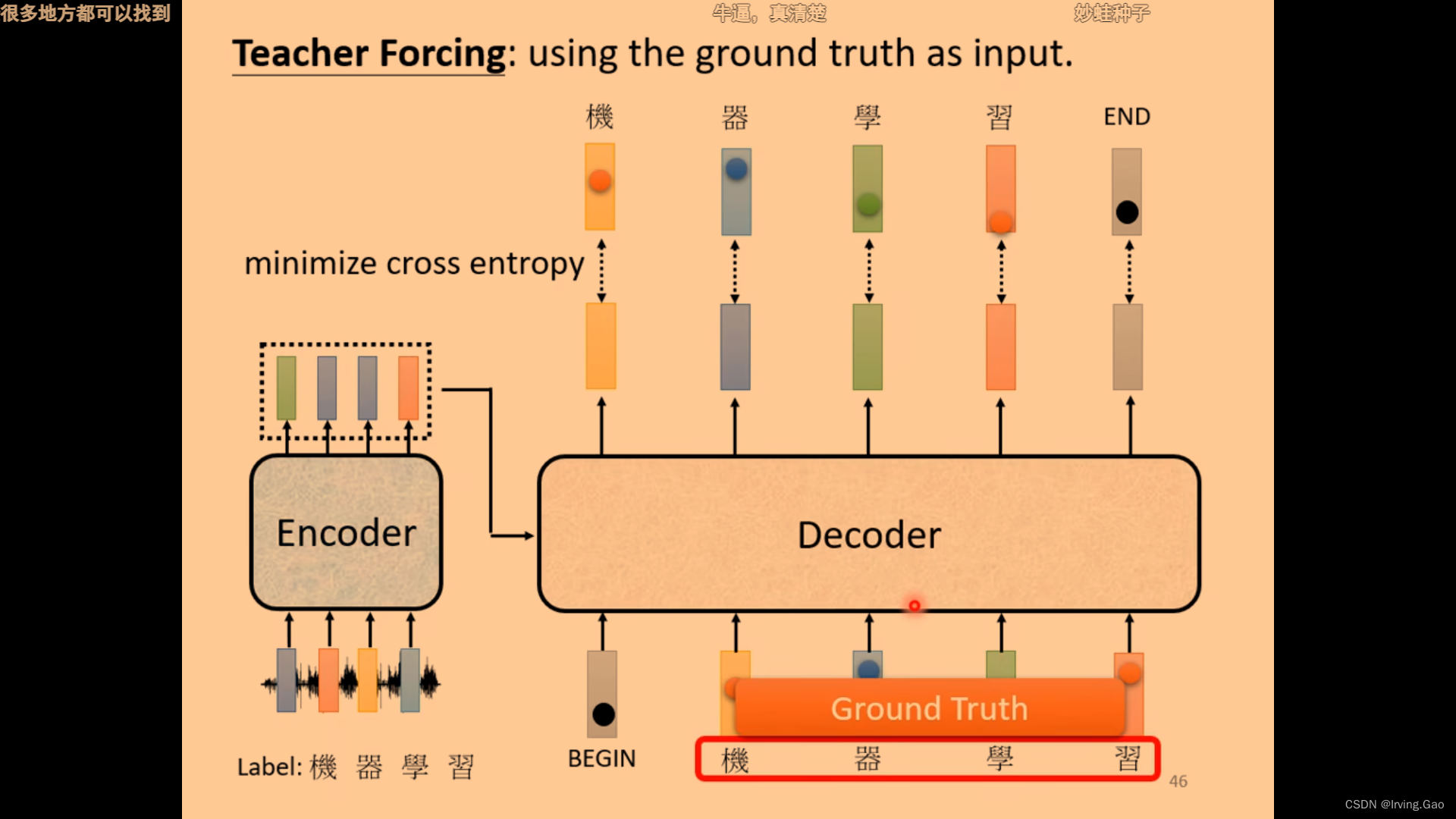
图1 Lambda与Lambda plus
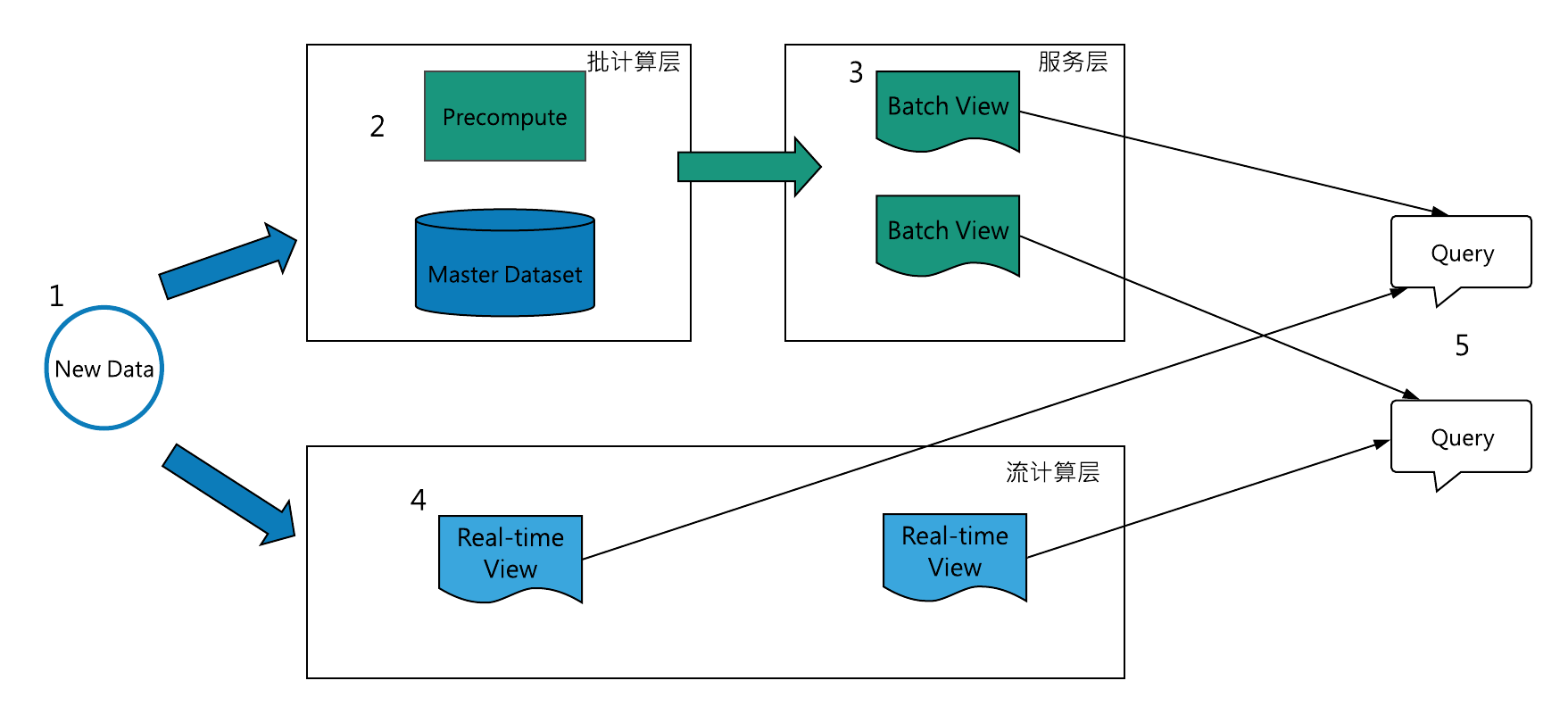
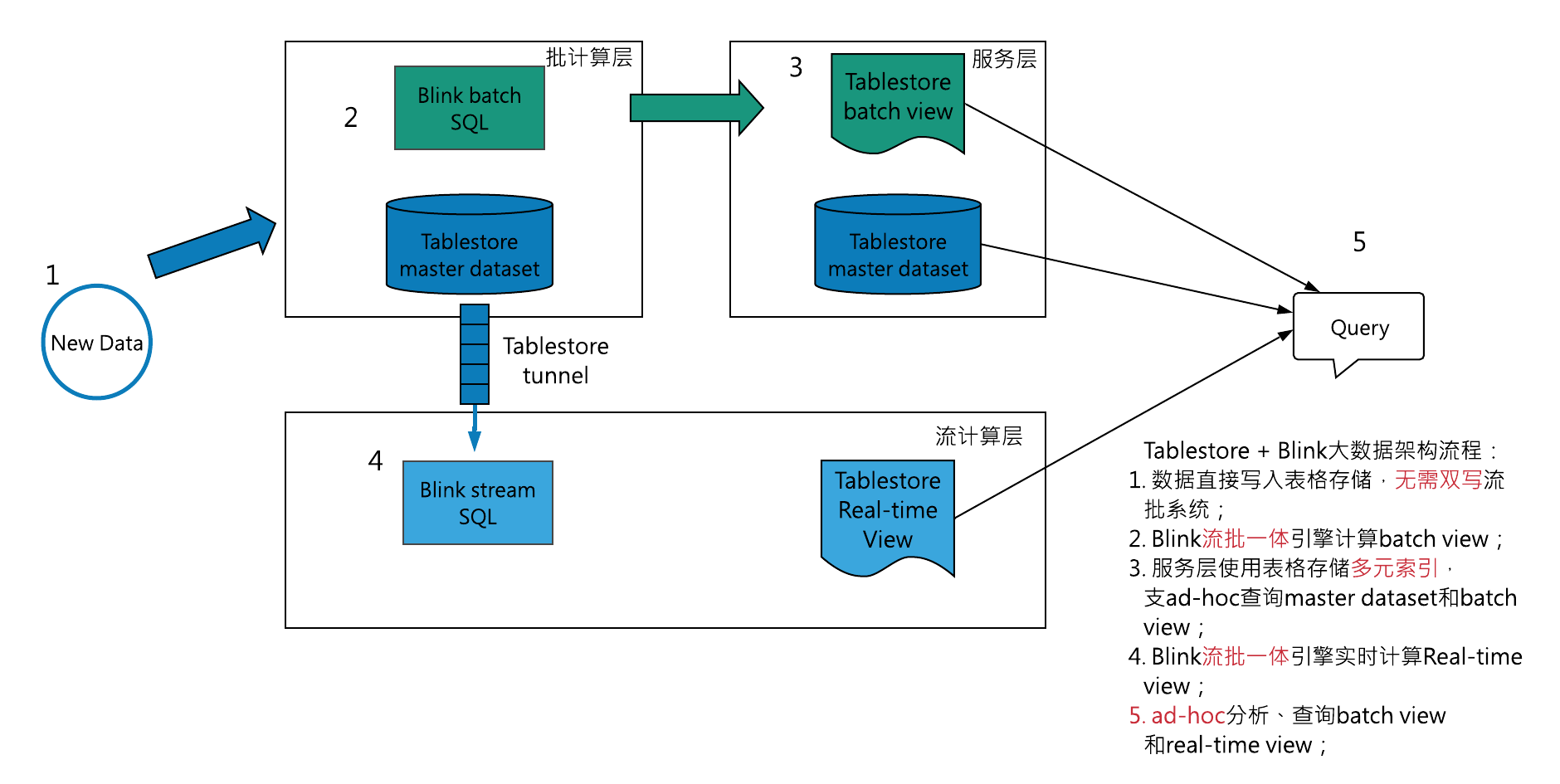
随着Flink引擎日趋完善[8],尤其在2020年发布Flink-1.12.0之后,逐渐出现了能切实解决上述问题的流批一体架构(Lambda plus,图1下半部分),采用该架构的数仓可称流批一体式数仓,即把Lambda架构的两条数据通道合并为一条,数据统一存储到一种介质中,且同一数据只需要存储一遍。流批一体式数仓主要体现在两方面:
1、数据累积(处理与存储)过程是流式的。 随着流水数据的持续处理,比如成交明细不断到来,数据经过处理后进入数仓的第一层,这层的变动实时传导至下一层,导致下层数据根据处理逻辑随之变化,这种变动逐层传递下去,形成各层数据的实时更新,就像山顶的 水源顺着搭建的管道不断向下流淌,并在流淌过程进行处理。 2、数据累积后,支持以批处理方式进行即席查询、统计分析等传统数据仓库支持的OLAP操作。
从实现上看,Lambda plus架构利用Flink流表的相互转化[6]实现了同一计算逻辑只需一套代码即可在流处理与批处理两种模式下得到一致结果,而且通过Flink cdc、状态计算等特性实现了历史数据+增量流水的连续处理[7],比如系统启动时利用Flink cdc先装载历史数据,再通过监听binlog将数据变动流水接入Flink;或者利用Flink state&checkpoint特性从指定checkpoint恢复,以便在流水上接续计算,这样即可实现基于历史数据增量计算的目的。
总结
1、目前基于Flink的流批一体架构主要还是体现在计算引擎上的一体化,即流处理与批处理共用一套开发范式,一套代码[1],而在存储的一体化上推出的Table store[5],虽已经可以小规模使用,但功能仍需健全,距离大规模企业级生产环境尚需一些时日。
2、具有分布式计算、窗口计算、状态计算、流批一体计算等特性的Flink正逐渐成为实时流计算应用的主要引擎。
3、流批一体式数仓是未来大数据架构发展趋势之一,但并不会完全替代Lambda架构。




![[附源码]计算机毕业设计汽车美容店管理系统Springboot程序](https://img-blog.csdnimg.cn/17922fbb298c4c608bb59f9d4b2f87cd.png)