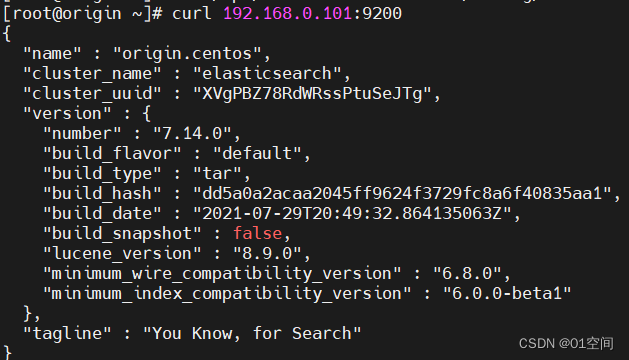
目录
一、生成数据表
1.导入pandas库
2.导入CSV或者xlsx文件
3.用pandas创建数据表
二、数据表信息查看
1.维度查看
2.数据表基本信息(维度、列名称、数据格式、所占空间等)
3.每一列数据的格式
4.某一列格式
5.空值判断
6.查看某一列空值
7.查看某一列的唯一值
8.查看数据表的值
9.查看列名称
10.查看前5行数据、后5行数据
三、数据表清洗
1.用数字0填充空值
2.使用列prince的均值对NA进行填充
3.清除city字段的字符空格
4.大小写转换
5.更改数据格式
6.更改列名称
7.删除后出现的重复值
8.删除先出现的重复值
9、数据替换
四、数据预处理
1.数据表合并
2.设置索引列
3.按照特定列的值排序
4.按照索引列排序
5.如果prince列的值>3000,group列显示high,否则显示low.
6.对复合多个条件的数据进行分组标记
7.对category字段的值依次进行分列,并创建数据表,索引值为df_inner的索引列,列名称为category和size
8.将完成分裂后的数据表和原df_inner数据表进行匹配
五、数据提取
六、数据筛选
七、数据汇总
八、数据统计
九、数据输出
一、生成数据表
1.导入pandas库
import pandas as pd2.导入CSV或者xlsx文件
df = pd.DataFrame(pd.read_csv('filename.csv'))
df = pd.DataFrame(pd.read_excel('filename.xlsx'))3.用pandas创建数据表
import numpy as np
df = pd.DataFrame({"id":[1001,1002,1003,1004,1005,1006],
"date":pd.date_range('20130102', periods=6),
"city":['Beijing ', 'SH', ' guangzhou ', 'Shenzhen', 'shanghai', 'BEIJING '],
"age":[23,44,54,32,34,32],
"category":['100-A','100-B','110-A','110-C','210-A','130-F'],
"price":[1200,np.nan,2133,5433,np.nan,4432]},
columns =['id','date','city','category','age','price'])
二、数据表信息查看
1.维度查看
df.shape
df.shape
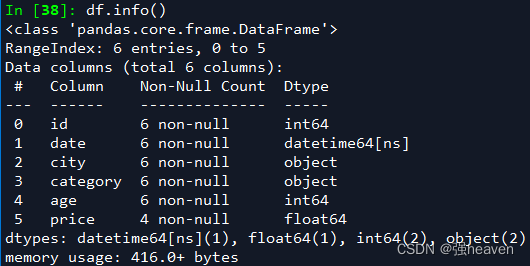
Out[36]: (6, 6)2.数据表基本信息(维度、列名称、数据格式、所占空间等)
df.info()
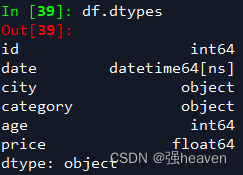
3.每一列数据的格式
df.dtypes
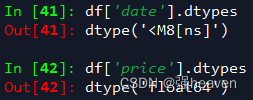
4.某一列格式
df['date'].dtype
df['price'].dtype
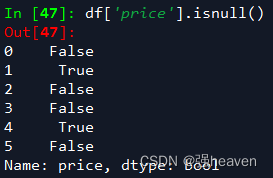
5.空值判断
df.isnull()

6.查看某一列空值
7.查看某一列的唯一值
![]()
8.查看数据表的值
df.values
9.查看列名称
df.columns
10.查看前5行数据、后5行数据
df.head() #默认前5行数据
df.tail() #默认后5行数据三、数据表清洗
1.用数字0填充空值
df.fillna(value=0)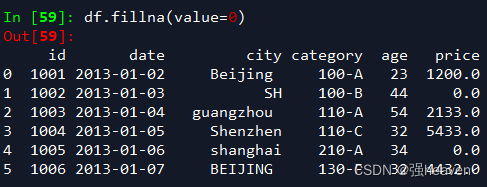
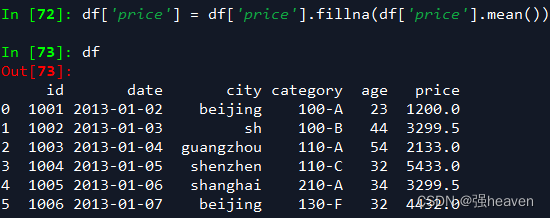
2.使用列price的均值对NA进行填充
df['price'].fillna(df['price'].mean())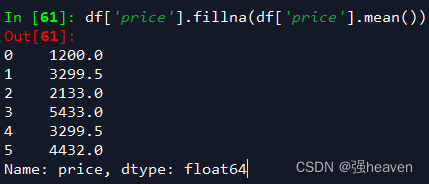
3.清除city字段的字符空格
df['city']=df['city'].map(str.strip)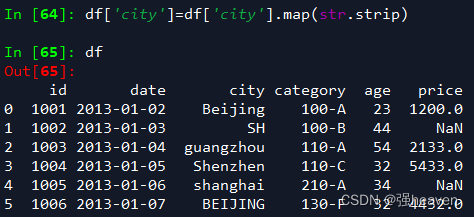
4.大小写转换
df['city']=df['city'].str.lower()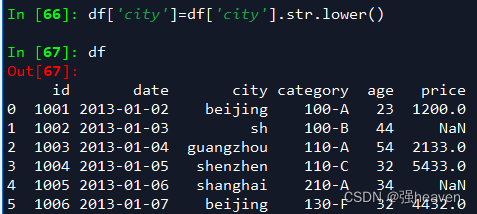
5.更改数据格式
df['price'].astype('int')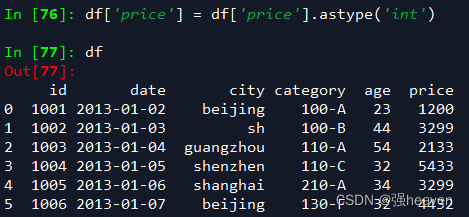
6.更改列名称
df.rename(columns={'category': 'category-size'}) 
7.删除后出现的重复值
df['city'].drop_duplicates()8.删除先出现的重复值
df['city'].drop_duplicates(keep='last')9、数据替换
df['city'].replace('sh', 'shanghai')四、数据预处理
df1=pd.DataFrame({"id":[1001,1002,1003,1004,1005,1006,1007,1008],
"gender":['male','female','male','female','male','female','male','female'],
"pay":['Y','N','Y','Y','N','Y','N','Y',],
"m-point":[10,12,20,40,40,40,30,20]})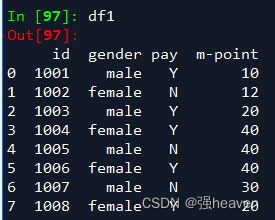
1.数据表合并
(1)merge
df_inner=pd.merge(df,df1,how='inner') # 匹配合并,交集
df_left=pd.merge(df,df1,how='left')
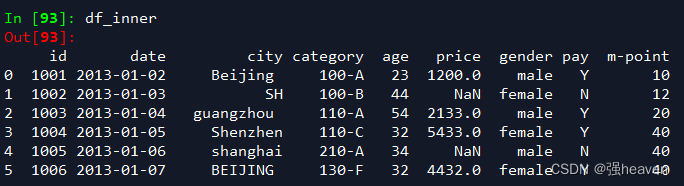
df_right=pd.merge(df,df1,how='right')
df_outer=pd.merge(df,df1,how='outer') #并集

(2)append
result = df1.append(df2)

df_result = df3.append(df4)
df3 = pd.DataFrame({'A':['A0','A1','A2','A3'],
'B':['B0','B1','B2','B3'],
'C':['C0','C1','C2','C3']})
df4 = pd.DataFrame({'A':['A4','A5','A6','A7'],
'B':['B4','B5','B6','B7'],
'C':['C4','C5','C6','C7']})
df_result = df3.append(df4)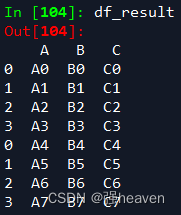
(3)join
result = left.join(right, on='key')

(4)concat
df5 = pd.DataFrame({'A':['A4','A5','A6','A7'],
'B':['B4','B5','B6','B7'],
'C':['C4','C5','C6','C7']})
result = pd.concat([df3,df4,df5])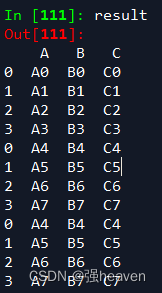
2.设置索引列
result.set_index('A')

3.按照特定列的值排序
df_inner.sort_values(by=['age'])
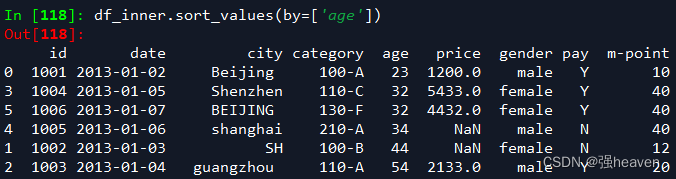
4.按照索引列排序
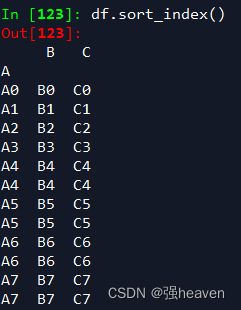
df=result.set_index('A')

df.sort_index()
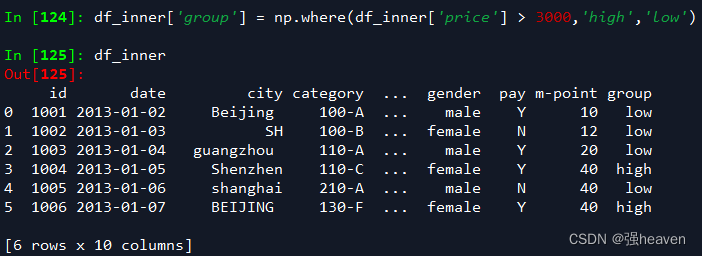
5.如果prince列的值>3000,group列显示high,否则显示low.
df_inner['group'] = np.where(df_inner['price'] > 3000,'high','low')
6.对复合多个条件的数据进行分组标记
df.loc[(df['city'] == 'beijing') & (df['price'] >= 4000), 'sign']=1

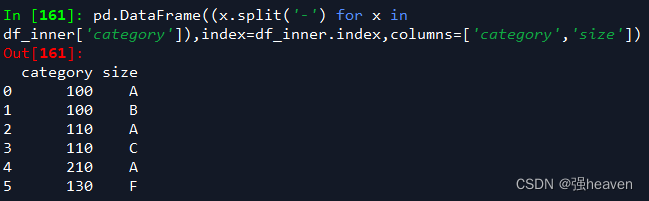
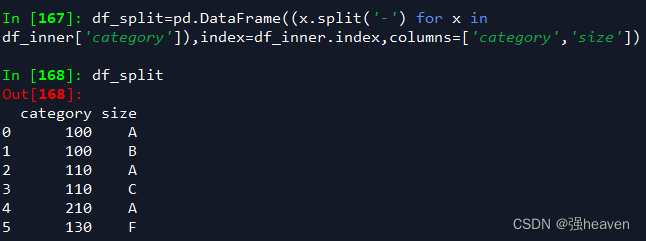
7.对category字段的值依次进行分列,并创建数据表,索引值为df_inner的索引列,列名称为category和size

pd.DataFrame((x.split('-') for x in df_inner['category']),index=df_inner.index,columns=['category','size'])
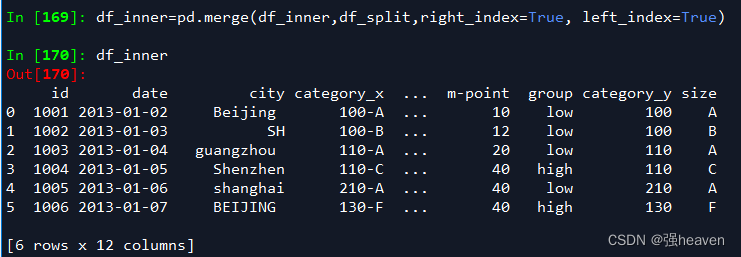
8.将完成分裂后的数据表和原df_inner数据表进行匹配
df_inner=pd.merge(df_inner,df_split,right_index=True, left_index=True)
五、数据提取
六、数据筛选
七、数据汇总
八、数据统计
九、数据输出
————————————————
参考链接:https://blog.csdn.net/yiyele/article/details/80605909