目录
- 1 从打车开始说起
- 1.1 需要解决的问题
- 1.1.1 打车排队
- 2 排队人数
- 2.1 需求
- 2.1.1 需求分析
- 2.2 实现方案
- 2.2.1 MySQL
- 2.2.1.1 入队
- 2.2.1.2 获取进度
- 2.2.1.3 遇到问题
- 2.2.3 Redis Zset
- 2.3 排队人数架构介绍
- 2.4 数据结构
- 2.4.2 zset结构
- 2.4.1 雪花算法
- 2.5 功能实现
- 2.5.1 派单
- 2.5.2 获取排队情况
- 2.6 演示
- 2.6.1 派单
- 2.6.2 排队情况查询
1 从打车开始说起


我们把滴滴打车的流程简化下
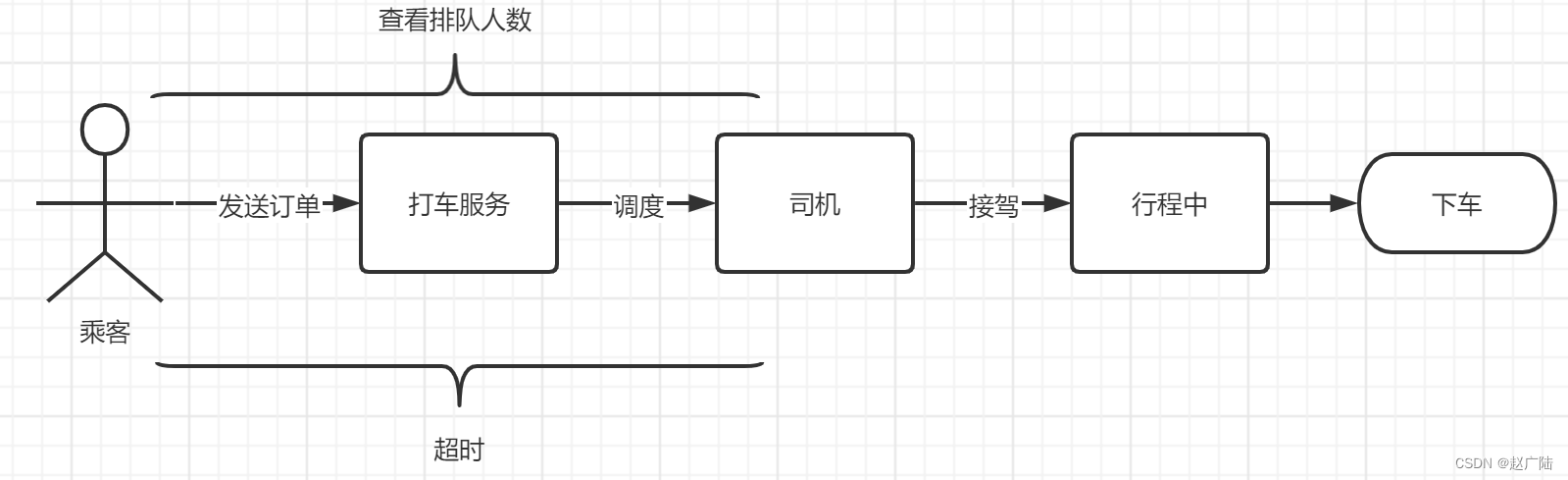
- 登录app后点击打车开始进行打车
- 打车服务开始为司机派单
- 司机接单后开始给来接驾
- 上车乘客后处于行程中
- 行程结束后完成本次打车服务
1.1 需要解决的问题
我们需要实现派单服务,用户发送打车订单后需要进行进行派单,如果在指定时间内没有找到司机就会收到派单超时的通知,并且能够实时查看当前排队的抢单人数
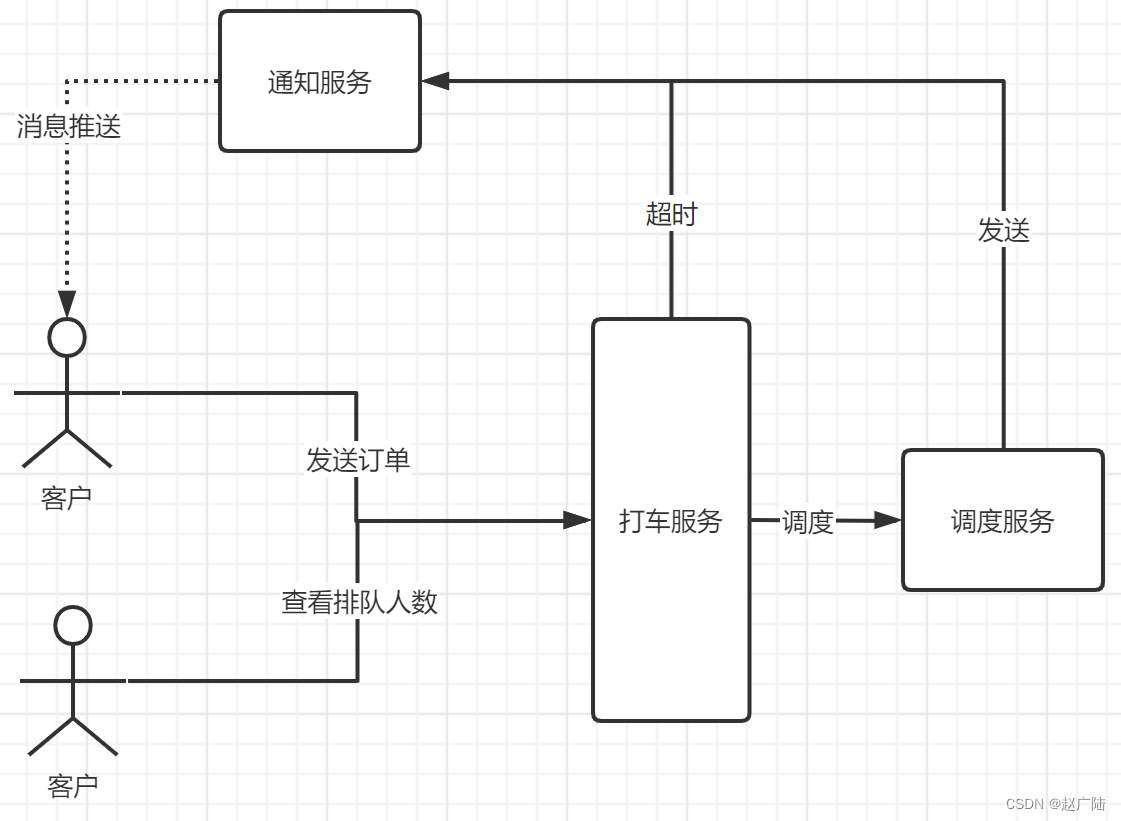
下面我们来介绍下涉打车涉及到的一些问题
1.1.1 打车排队
主要讲解打车服务在超时后的处理,比如打车后等待多长时间没有打到车后会通知等待超时

2 排队人数

2.1 需求
在打车的过程中如果人数较多的情况下会在派单中等待,如果想知道我的前面还有多少人呢,我们就需要一个排队人数的功能
接受用户的派单数据,但因为派单处理需要一定的时间,所以只能在MQ中有序消费数据,对用户进行排队操作,当然这个排队操作,用户是不透明的,某些用户的请求可能被优先处理,但是通过MQ可以实现整体的有序。
用户很关心自己派单目前的处理进度,即和我一样打车的前面还有多少人,打车APP上显示“你前面还有多少人在排队”,所以后台要能告知用户目前他的派单进度。
2.1.1 需求分析
- 入队:可以理解为写操作,需要后端存储数据。
- 获取进度:可以理解为读操作,而且可以预见这个读操作应该比写操作频繁,如果用户很关注她的订单进展,说不定会一直刷新查看他的订单排队情况。
2.2 实现方案
2.2.1 MySQL
用户的订单数据肯定得持久化存储,MySQL是一个不错的选择,既然需求这么简单,无非一个订单数据嘛,暂且用一张表“订单表(T_Order)”来保存正在排队的订单,已经处理完毕的订单则从T_Order表迁移至“(历史订单表T_History_Order)”,这样的好处避免订单表数据量太大,提高读写性能。
2.2.1.1 入队
完成订单的入库,显然就是一个insert语句了
insert into T_Order(...) values(...);
2.2.1.2 获取进度
需查询自己订单的排队情况,那肯定看比自己订单时间还早的用户有多少人了,这些比自己下单时间还早的人,就是排在自己前面的人了,假设一个用户同时只能有一个订单在排队
#先查出自己订单时间, 假设是1429389316
select orderTime from T_Order where uid=8888;
#再查有多少人的订单时间比自己的早
select count(orderTime) from T_Order where orderTime <= 1429389316;
2.2.1.3 遇到问题
互联网的精髓就是“小步快跑,快速迭代”,用MySQL快速完成需求,面向用户服务后
初期阶段,一切ok,但是当这个业务运营得好,用户量大的时候,就会发现用户经常投诉“我查询自己的订单排队进度,经常报错”,甚至处理订单的同事,也经常抱怨从订单系统里面查看订单,非常缓慢,select count 操作基本都是全表扫描操作,看来MySQL面对这么大规模的全表查询操作,还是有点吃力。
2.2.3 Redis Zset
NoSQL在互联网领域的江湖地位已经很牢靠了,看来得请他老人家出来救场了
没错,使用Redis的有序集合(sorted sets)数据结构,就可以完美的解决这个问题,因为有序集合底层的实现是跳表这种数据结构,时间复杂度是logN,即使有序集合里面的订单有100万之多,耗时也基本都是纳秒级别(基本不到1毫秒)
- 用户提交一个订单,我们写入redis的zset中。
- 用户要查询自己的订单排队情况,这时候我们只要查询redis的有序集合就可以了,命令为rank
- 当这个订单被处理完成后,直接一个zrem命令将订单从有序集合中删除即可
因为Redis基本都是内存操作,而且有序集合的底层实现是跳表这种效率媲美平衡树,但是实现又简单的数据结构,从而完美的释放了MySQL的读压力。
2.3 排队人数架构介绍
打车如果出现排队我们需要能够对当前排队的人数进行预估,能够知道当前我们前面有多少人在排队,我们采用redis的zset来实现排队,整体架构如下。
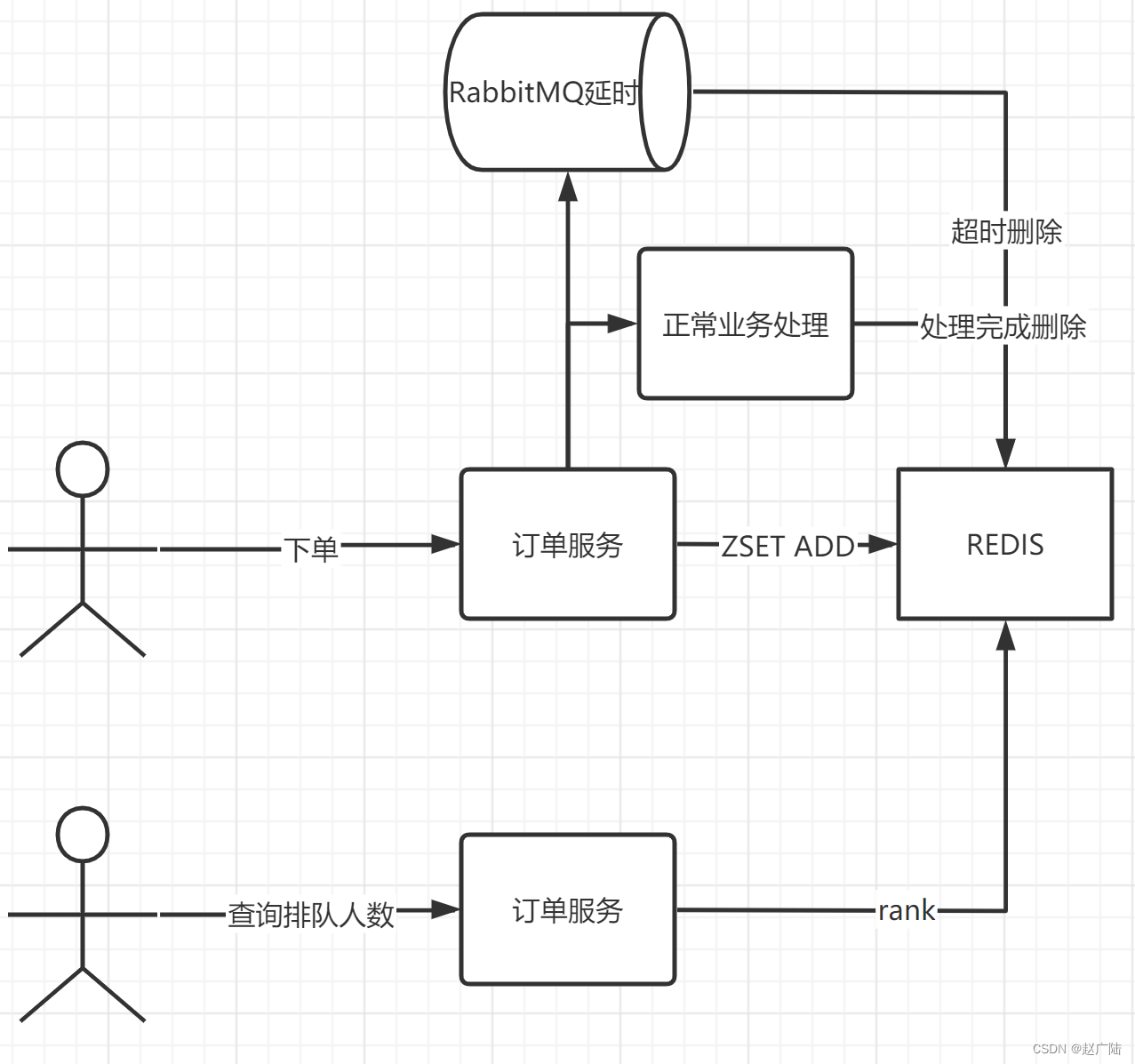
- 用户打车通过zset加入到redis的有序集合
- 异步将数据推送到RabbitMQ延迟以及进行正常业务处理
- 处理完成后在zset中删除元素
- 用户查询人数通过Rank命令进行查询
2.4 数据结构
2.4.2 zset结构
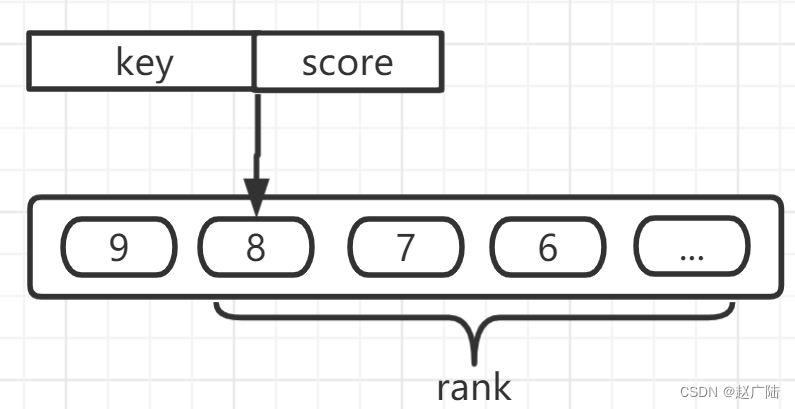
Redis 有序集合和集合一样也是 string 类型元素的集合,且不允许重复的成员。
不同的是每个元素都会关联一个 double 类型的分数,redis 正是通过分数来为集合中的成员进行从小到大的排序。
我们只需要使用rank命令统计从0-当前key对应的分数的key的数量就可以得到当前的排名了
因为Redis基本都是内存操作,而且有序集合的底层实现是跳表这种效率媲美平衡树,但是实现又简单的数据结构,从而完美的释放了MySQL的读压力。
我们如何来保证分数不重复,并且是有序递增的呢,这里就要祭出来我们的雪花算法
2.4.1 雪花算法
SnowFlake算法生成id的结果是一个64bit大小的整数,它的结构如下图:


4095个数字,来表示同一机器同一时间截(毫秒)内产生的4095个ID序号。
由于在Java中64bit的整数是long类型,所以在Java中SnowFlake算法生成的id就是long来存储的。
SnowFlake可以保证
- 所有生成的id按时间趋势递增
- 整个分布式系统内不会产生重复id(因为有datacenterId和workerId来做区分)
2.5 功能实现
2.5.1 派单
使用redisTemplate操作zset将username以及workid压入zset中
redisTemplate.opsForZSet().add(TaxiConstant.TAXT_LINE_UP_KEY, taxiBO.getUsername(), taxiBO.getId());
2.5.2 获取排队情况
使用redisTemplate操作zset获取username对应的排名
redisTemplate.opsForZSet().rank(TaxiConstant.TAXT_LINE_UP_KEY, username);
2.6 演示
2.6.1 派单

2.6.2 排队情况查询