GAITTAKE:通过时间注意和关键点引导嵌入进行步态识别
论文题目:GAITTAKE: GAIT RECOGNITION BY TEMPORAL ATTENTION AND KEYPOINT-GUIDED EMBEDDING
论文是华盛顿大学发表在ICIP 2022的工作
论文地址
ABSTRACT
步态识别是指根据远距离采集的视频数据,根据人的体型和行走方式对人进行识别或识别,广泛应用于犯罪预防、法医鉴定和社会保障等领域。然而,据我们所知,大多数现有方法都使用外观、姿势和时间特征,而没有考虑用于全局和局部信息融合的学习时间注意机制。在本文中,我们提出了一种新颖的步态识别框架,称为时间注意和关键点引导嵌入(GaitTAKE),它有效地融合了基于时间注意的全局和局部外观特征以及时间聚合的人体姿势特征。实验结果表明,我们提出的方法在 CASIA-B 步态数据集上实现了步态识别的新 SOTA,rank-1 准确率为 98.0%(正常)、97.5%(包)和 92.2%(外套); OU-MVLP 步态数据集的准确率为 90.4%。
索引词——步态识别、时间注意力、人体姿势估计
1. INTRODUCTION
步态识别是利用远距离采集的视频数据,根据人的体型和行走方式对人进行识别或识别,广泛应用于犯罪预防、法医鉴定、社会保障等领域。行人重识别(ReID)是其中一种计算机视觉社区中最受欢迎的研究。然而,仅使用外观特征不足以应对一些困难的场景,例如同一身份穿着不同的衣服、低分辨率视频、黑暗照明情况。因此,步态识别可以作为克服这些问题的有效补充或替代方案。
文献中有两种流行的步态识别方法,即基于模型的 [1, 2, 3, 4] 和基于外观的 [5, 6, 7, 8]。基于模型的方法侧重于连接的人类特征,例如链接的大小或关节角度,这些特征可以容忍由于衣服或配饰而导致身份的外观变化。这些方法需要预处理原始 RGB 视频以捕捉姿势结构或轮廓。另一方面,一些研究提出了基于外观的步态识别方法,该方法使用 RGB 图像序列作为输入来直接识别身份。然而,基于模型的方法丢失了身体形状信息,并且需要高精度的人体姿态估计结果来进行步态识别。此外,基于外观的方法对身份的协变量(例如,着装和携带条件)敏感。
在本文中,我们提出了一种新的框架,以称为 GaitTAKE 的原则方式生成时间注意和关键点引导嵌入。 GaitTAKE 的直觉是同时考虑全局和局部外观特征,然后通过时间信息训练轮廓嵌入的学习。因此,我们不仅可以通过时间池来解决缺陷,还可以将时间信息融合到全局和局部特征中。此外,我们将人体姿势信息与上述全局和局部特征相结合,使我们的方法可以在步态识别的穿着外套场景中实现大量改进,这是步态识别中最困难的情况,因为外套将覆盖大部分人类腿部的面积。 GaitTAKE 使用全局和局部卷积神经网络 [9] 以及具有时间注意机制的人体姿势信息在多个帧上形成嵌入。根据我们的实验结果,GaitTAKE 在 CASIA-B [10] 和 OUMVLP [11] 基准测试中实现了最先进的性能。
2. RELATED WORKS
由于深度学习的发展,许多研究人员利用卷积神经网络 (CNN) 来实现步态识别的巨大改进 [8、12、13、14、15、16]。特征表示能力强,例如,仅基于CNN特征和精心设计的损失函数就可以识别跨视角步态序列。
在利用时间信息方面,有两种深度学习方法:循环神经网络 (RNN) 和 3D CNN。在 RNN 中,特征是通过一系列连续帧 [16、17、18] 学习的。对于 3D CNN,可以通过 3D 张量 [15、19、9] 提取时空信息。尽管如此,使用 3D CNN 进行步态识别存在局限性,即可变长度序列缺乏灵活性。
3. PROPOSED METHOD
3.1. TA-based Global and Local Feature Fusion
如图 1 所示,所提出的特征提取网络架构旨在同时从剪影图像中提取全局和局部特征信息以及时间信息。首先,应用 3D 卷积从剪影图像中提取更具代表性的特征,因为 3D 卷积网络被证明是步态识别的有效特征提取器 [9,15,19]。之后,通过将图像水平划分为几个身体分区来提取局部信息,并通过整个剪影图像提取全局信息。为了将时间信息聚合到局部和全局特征图中,两个 3D 卷积分别应用于局部特征图和全局特征图。局部特征图(即身体分区特征)共享相同的 3D 卷积权重。根据 [9],生成的全局和局部特征可以添加到一个特征图中,以集成全局和局部信息。然后,使用相同的网络配置和不同的卷积核重复这种全局和局部特征融合操作 n n n 次,以生成更稳健的全局和局部融合特征。
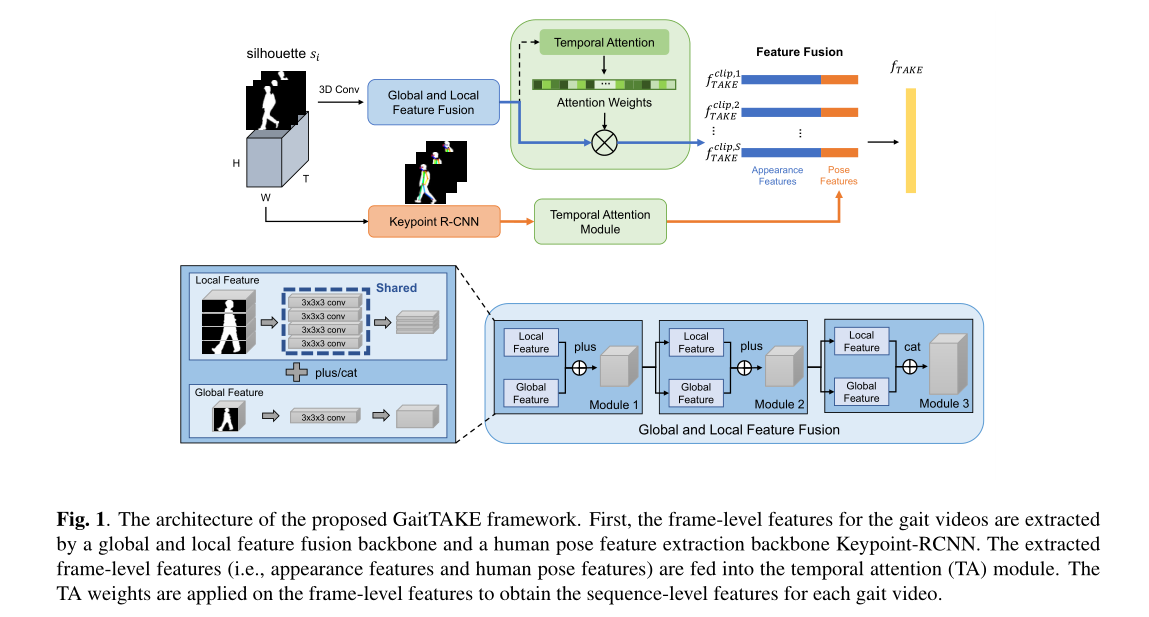
生成基于 TA 的全局和局部特征融合的第一步是首先分别生成全局和局部特征。我们用
X
∈
R
c
1
×
T
×
h
×
w
X \in \mathbb{R}^{c_1 \times T \times h \times w}
X∈Rc1×T×h×w表示一个长度为
T
T
T的剪影序列(图像大小为
h
×
w
h \times w
h×w),
{
X
local
i
∣
i
=
1
,
⋯
,
m
}
\left\{X_{\text {local }}^i \mid i=1, \cdots, m\right\}
{Xlocal i∣i=1,⋯,m}表示第
m
m
m个局部步态分区特征。
c
c
c是特征图的通道大小。因此,我们可以将全局步态特征
f
global
f_{\text {global }}
fglobal 表示为
f
global
(
X
)
=
ϕ
global
3
×
3
×
3
(
X
)
∈
R
c
2
×
T
×
h
×
w
,
f_{\text {global }}(X)=\phi_{\text {global }}^{3 \times 3 \times 3}(X) \in \mathbb{R}^{c_2 \times T \times h \times w},
fglobal (X)=ϕglobal 3×3×3(X)∈Rc2×T×h×w,
其中
ϕ
global
3
×
3
×
3
\phi_{\text {global }}^{3 \times 3 \times 3}
ϕglobal 3×3×3表示内核大小为
3
×
3
×
3
3 \times 3 \times 3
3×3×3的 3D 卷积运算。对于局部步态特征
f
local
f_{\text {local }}
flocal ,类似的机制适用于共享 3D 卷积核,
f
local
(
X
)
=
f
local
(
{
X
local
i
∣
i
=
1
,
⋯
,
m
}
)
=
ϕ
local
3
×
3
×
3
(
X
local
1
)
⊕
⋯
⊕
ϕ
local
3
×
3
×
3
(
X
local
m
)
∈
R
c
2
×
T
×
h
×
w
\begin{aligned} f_{\text {local }}(X) & =f_{\text {local }}\left(\left\{X_{\text {local }}^i \mid i=1, \cdots, m\right\}\right) \\ & =\phi_{\text {local }}^{3 \times 3 \times 3}\left(X_{\text {local }}^1\right) \oplus \cdots \oplus \phi_{\text {local }}^{3 \times 3 \times 3}\left(X_{\text {local }}^m\right) \\ & \in \mathbb{R}^{c_2 \times T \times h \times w} \end{aligned}
flocal (X)=flocal ({Xlocal i∣i=1,⋯,m})=ϕlocal 3×3×3(Xlocal 1)⊕⋯⊕ϕlocal 3×3×3(Xlocal m)∈Rc2×T×h×w
其中
ϕ
local
3
×
3
×
3
\phi_{\text {local }}^{3 \times 3 \times 3}
ϕlocal 3×3×3是内核大小为
3
×
3
×
3
3 \times 3 \times 3
3×3×3的共享 3D 卷积层;
⊕
\oplus
⊕表示连接操作。
TA 融合模块由两种不同结构的全局和局部卷积 (GLConv) 层组成,即 GLConvA 和 GLConvB。图 1 显示该模块中有
n
n
n个 GLConv 层,用于生成全局和局部信息融合特征
f
G
L
(
n
=
3
)
f_{G L}(n=3)
fGL(n=3)。最后一个 GLConv 层是 GLConvB,其余 GLConv 层是 GLConvA,
G
L
C
o
n
v
A
(
X
)
=
f
global
(
X
)
+
f
local
(
X
)
∈
R
c
2
×
T
×
h
×
w
.
G
L
C
o
n
v
B
(
X
)
=
f
global
(
X
)
⊕
f
local
(
X
)
∈
R
c
2
×
T
×
2
h
×
w
.
\begin{aligned} G L C o n v A(X) & =f_{\text {global }}(X)+f_{\text {local }}(X) \\ & \in \mathbb{R}^{c_2 \times T \times h \times w} . \\ G L C o n v B(X) & =f_{\text {global }}(X) \oplus f_{\text {local }}(X) \\ & \in \mathbb{R}^{c_2 \times T \times 2 h \times w} . \end{aligned}
GLConvA(X)GLConvB(X)=fglobal (X)+flocal (X)∈Rc2×T×h×w.=fglobal (X)⊕flocal (X)∈Rc2×T×2h×w.
因此,我们可以应用展平操作
ξ
(
⋅
)
\xi(\cdot)
ξ(⋅)来得到全局和局部信息融合的特征
f
G
L
f_{G L}
fGL,
f
G
L
=
ξ
(
G
L
C
o
n
v
B
(
G
L
C
o
n
v
A
(
G
L
C
o
n
v
A
(
X
)
)
)
)
∈
R
T
×
D
G
L
,
\begin{aligned} f_{G L} & =\xi(G L C o n v B(G L C o n v A(G L C o n v A(X)))) \\ & \in \mathbb{R}^{T \times D_{G L}}, \end{aligned}
fGL=ξ(GLConvB(GLConvA(GLConvA(X))))∈RT×DGL,
其中
D
G
L
D_{G L}
DGL是
f
G
L
f_{G L}
fGL的维度。
在获得全局和局部信息融合特征
f
G
L
f_{G L}
fGL后,我们可以开始应用 TA 机制生成最终的嵌入
f
T
G
L
f_{T G L}
fTGL。首先,每个主题的序列被分成几个片段。假设剪辑大小为
L
L
L,
S
=
⌊
T
L
⌋
S=\left\lfloor\frac{T}{L}\right\rfloor
S=⌊LT⌋是剪辑的数量,
D
D
D表示剪辑级特征的维度。
f
G
L
c
l
i
p
=
{
f
G
L
c
l
i
p
,
1
,
⋯
,
f
G
L
c
l
i
p
,
S
}
∈
R
S
×
L
×
D
f_{G L}^{c l i p}=\left\{f_{G L}^{c l i p, 1}, \cdots, f_{G L}^{c l i p, S}\right\} \in \mathbb{R}^{S \times L \times D}
fGLclip={fGLclip,1,⋯,fGLclip,S}∈RS×L×D
然后,有两个卷积层用于 TA 模块
T
G
L
(
⋅
)
\mathcal{T}_{G L}(\cdot)
TGL(⋅)中的每个剪辑以产生特征向量。我们随后将 softmax 层应用于该特征向量以生成
1
×
L
1 \times L
1×L-dim 注意力向量
A
G
L
\mathcal{A}_{G L}
AGL,用于对帧级特征进行加权,以便可以创建剪辑级特征
f
T
G
L
c
l
i
p
,
i
∈
R
1
×
D
f_{T G L}^{c l i p, i} \in \mathbb{R}^{1 \times D}
fTGLclip,i∈R1×D。
f
T
G
L
c
l
i
p
,
i
=
T
G
L
(
f
G
L
c
l
i
p
,
i
)
=
A
G
L
⋅
f
G
L
c
l
i
p
,
i
∈
R
1
×
D
.
A
G
L
=
σ
G
L
(
δ
G
L
,
2
(
δ
G
L
,
1
(
f
G
L
c
l
i
p
,
i
)
)
)
∈
R
1
×
L
.
\begin{gathered} f_{T G L}^{c l i p, i}=\mathcal{T}_{G L}\left(f_{G L}^{c l i p, i}\right)=\mathcal{A}_{G L} \cdot f_{G L}^{c l i p, i} \in \mathbb{R}^{1 \times D} . \\ \mathcal{A}_{G L}=\sigma_{G L}\left(\delta_{G L, 2}\left(\delta_{G L, 1}\left(f_{G L}^{c l i p, i}\right)\right)\right) \in \mathbb{R}^{1 \times L} . \end{gathered}
fTGLclip,i=TGL(fGLclip,i)=AGL⋅fGLclip,i∈R1×D.AGL=σGL(δGL,2(δGL,1(fGLclip,i)))∈R1×L.
其中
σ
G
L
(
⋅
)
\sigma_{G L}(\cdot)
σGL(⋅)是softmax操作;
δ
G
L
,
1
\delta_{G L, 1}
δGL,1和
δ
G
L
,
2
\delta_{G L, 2}
δGL,2分别表示第一和第二卷积层。
最后,将一个平均池化层
ψ
G
L
(
⋅
)
\psi_{G L}(\cdot)
ψGL(⋅)应用于这些剪辑级嵌入
f
T
G
L
clip
f_{T G L}^{\text {clip }}
fTGLclip 以生成最终嵌入
f
T
G
L
f_{T G L}
fTGL。
f
T
G
L
=
ψ
G
L
(
f
T
G
L
c
l
i
p
)
∈
R
1
×
D
f_{T G L}=\psi_{G L}\left(f_{T G L}^{c l i p}\right) \in \mathbb{R}^{1 \times D}
fTGL=ψGL(fTGLclip)∈R1×D
3.2. Temporal Aggregated Human Pose Feature
在我们的框架中,我们不仅考虑了外观嵌入特征,还考虑了人体姿势特征,因为步态识别与相应的人体姿势显着相关。我们使用关键点 R-CNN [20] 来获取人体姿势信息。由于并非所有步态识别数据集都包含人体姿势信息,因此我们使用在 COCO 数据集上训练的预训练模型,根据可用的 RGB 图像作为ground-truth人体姿势标签来推断人体姿势信息。然后,我们使用人体姿势标签来训练基于剪影图像的关键点 R-CNN,以便我们可以使用训练好的关键点 R-CNN 模型来推断剪影图像上的人体姿势信息。
估计人体姿势后,我们使用生成的 2D 关键点(身体关节)作为步态识别的额外特征。每帧人体姿势特征 K \mathcal{K} K的维度为17×3,其中17为关节数,3表示2D关节坐标 ( x , y ) (x, y) (x,y)和对应的置信度得分 c c c。与外观特征类似,我们也将时间注意力技术应用于人体姿势特征,将帧级特征聚合为基于剪辑的人体姿势特征,然后将时间聚合的人体姿势特征与 f T G L f_{T G L} fTGL连接起来作为最终表示 f T A K E c l i p f_{T A K E}^{c l i p} fTAKEclip用于步态识别。
因此,我们使用广义均值池化 (GeM) [9] 将空间信息整合到特征图中。GeM 可以有效地从空间信息中生成更稳健的表示,传统上,研究人员通过加权和融合平均池和最大池结果的特征,另一方面,GeM 可以直接融合这两种不同的操作以形成特征图,
p
=
1
p=1
p=1等于平均池化,
p
=
∞
p=\infty
p=∞等于最大池化,
f
G
e
M
=
(
ψ
G
e
M
(
(
f
T
A
K
E
)
p
)
)
1
p
f_{G e M}=\left(\psi_{G e M}\left(\left(f_{T A K E}\right)^p\right)\right)^{\frac{1}{p}}
fGeM=(ψGeM((fTAKE)p))p1
其中
ψ
G
e
M
(
⋅
)
\psi_{G e M(\cdot)}
ψGeM(⋅)是平均池化操作。
3.3. Loss Function
特征提取的最后一步是将 C C C个不同的全连接层应用于同一个 f G e M f_{G e M} fGeM,生成 C C C个一维嵌入f。因此,每个主题可以由 C C C个不同的嵌入表示,并且主题的所有 f f f用于独立计算损失。我们架构的损失函数是三元组损失,它被广泛使用并被证明在 ReID 任务中具有优越的性能。
三元组损失函数的定义如下:
l
triplet
(
a
)
=
[
m
+
∑
p
∈
P
(
a
)
w
p
D
a
p
−
∑
n
∈
N
(
a
)
w
n
D
a
n
]
+
,
l_{\text {triplet }}(a)=\left[m+\sum_{p \in P(a)} w_p D_{a p}-\sum_{n \in N(a)} w_n D_{a n}\right]_{+},
ltriplet (a)=
m+p∈P(a)∑wpDap−n∈N(a)∑wnDan
+,
其中
m
m
m是margin,
D
a
p
D_{a p}
Dap和
D
a
n
D_{a n}
Dan分别表示anchor样本
a
a
a形成正例和负例的距离。此外,
w
p
w_p
wp和
w
n
w_n
wn表示正例和负例的权重。