0、前言
在了解倒排索引之前先理解下索引的作用:
查询数据的时候,最耗时的操作并不是CPU计算,也不是内存聚合,而是去磁盘将文档查到并拉取回来的过程。我们都知道在磁盘IO的过程中,顺序读写效率高于随机读写,磁盘的查找次数也决定最终的响应时间。在使用索引的过程中,我们将数据按照指定方式顺序存放好,然后利用各种数据结构(b树、b+树、倒排索引)等来减少我们查询数据的次数,提高定位和获取数据的效率,这就是索引的作用。
1、什么是倒排索引
简单点说普通索引是key找value,那倒排索引就是value找key。
比如mysql的结构是这样的
| id | name | sex |
| 1 | 李三 | 男 |
在es倒排索引里是这样的:其中term称为词项,是经过分词器处理后的结果;docId是文档id,根据文档id来获取当前文档的内容。
| Term | docId |
| 李三 | 1 |
| 男 | 1 |
在ES中将所有的词项通过字典顺序排列好后存储起来,这个数据结构叫词项字典(Term Directory)。实际业务中每一个词项并不只存在一个文档中,而是关联一个文档id的列表,ES中称为Posting List(关联文档ID的列表)。并且ES将词项的前缀(Term Index)拿出,构建了一个FST(相当于Term Directory的index)

因为查索引是磁盘随机IO,而将词项字典抽出来一个词项索引树,放在内存中从而大大增加IO效率。并且词项字典是分区存放,利用公共前缀进行压缩,可以做到更节省空间。
2.联合索引查询
mysql中使用索引查询时,只会使用单一索引进行查询,而es中使用倒排索引查询则是取每个词项中对应的文档list做交集处理。
而es对交集的处理有两种方式:跳表、bitset
什么是跳表
将一个有序链表level0,挑出其中几个元素到level1及level2,每个level越往上,选出来的指针元素越少,查找时依次从高level往低查找。这种链表加多级索引的结构,就叫做跳表。

跳表方式
以下取出两个索引的文档id集合,取其交集,如果tab1的跳表如上图所示有一个level1索引,那么取交集过程就为(短找长)
>tab2:2,tab1没有跳过;tab2:24,tab1通过1-18检索没有跳过
->tab2:25, tab1通过1-18-25检索有,id=25存入结果集
->tab2:27, tab1跳过,重复,直到找到37,id=37写入结果集。
如果没有跳表找30这样的元素需要1-3-5-8-18-25-30,而有跳表则只需要1-18-25-30。
Tab1:
| 1 | 3 | 5 | 8 | 18 | 25 | 30 | 33 | 37 |
Tab2:
| 2 | 24 | 25 | 27 | 29 | 31 | 33 |
bitset方式
一个list为[1,3,5,6],另一个为[1,4,6,7]
那么两个list对应的bitset
| bit位 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| List1 | 1 | 0 | 1 | 0 | 1 | 1 | 0 |
| List2 | 1 | 0 | 0 | 1 | 0 | 1 | 1 |
| List1&List2结果 | 1 | 0 | 0 | 0 | 0 | 1 | 0 |
通过&两个list的bit位可以得到1和6的文档id符合要求,最终返回1、6的文档数据
3.倒排索引结构压缩
倒排索引结构压缩中结构压缩的方式有两种:Frame Of Reference 和 Roaring Bitmap 。
Frame Of Reference
该压缩方式是进行做差压缩存储bit位,来节省存储空间。
例:这样一个PostingList:[1,3,13,101,105,108,255,256,257]
将这个做差后,按bit存:[1,2,10,88,4,3,147,1,1]
然后分到不同的block里面(跳表方式):[1,2,10],[88,4,3],[147,1,1]
在分到不同的block的同时计算每一个block中数据所占用的最大位数,如第一个block中10是当前block中最大的数据,以最大的数据为基准,算出占用的bit大小,2*3<10<2*4,取4bit。
而这个block中有3个元素,则是3*占用最大的bit=3*4=12bit,/8转换为字节Byte,一个Byte放不下,需要2Byte。
计算出多个block中所占用的总Byte=2+3+3=8Byte,共节省了36-8=28Byte

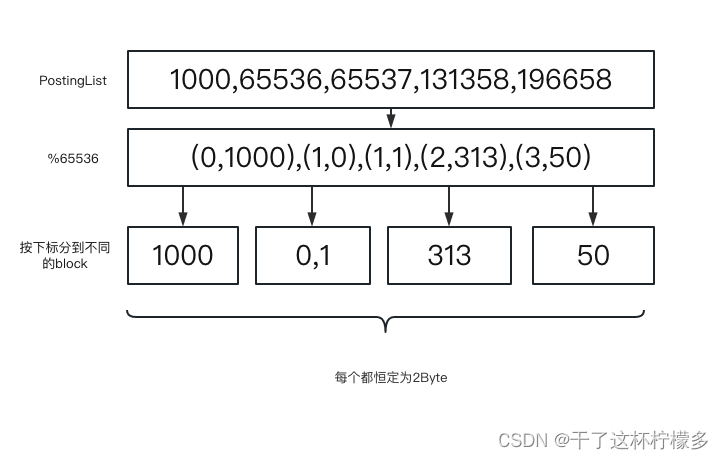
Roaring Bitmap
根据高16位(2*16=65536)把PostingList切分成不同的block,这时每个block中的每个值最大为65535(2*16-1),16bit占两个Byte。