在Python爬虫中,代理的使用非常常见。代理的主要作用是隐藏客户端的真实IP地址,从而实现更高的网络访问速度和更好的访问隐私保护。下面我们将通过Python爬虫的实例,带你详细了解Python爬虫中代理的使用方法。
目录
## 1. 代理原理和作用
## 2. Python爬虫代理的使用方式
## 3. 代理IP的获取
## 4. 多线程和多进程使用代理
## 5. 请求头的设置
总结
## 1. 代理原理和作用
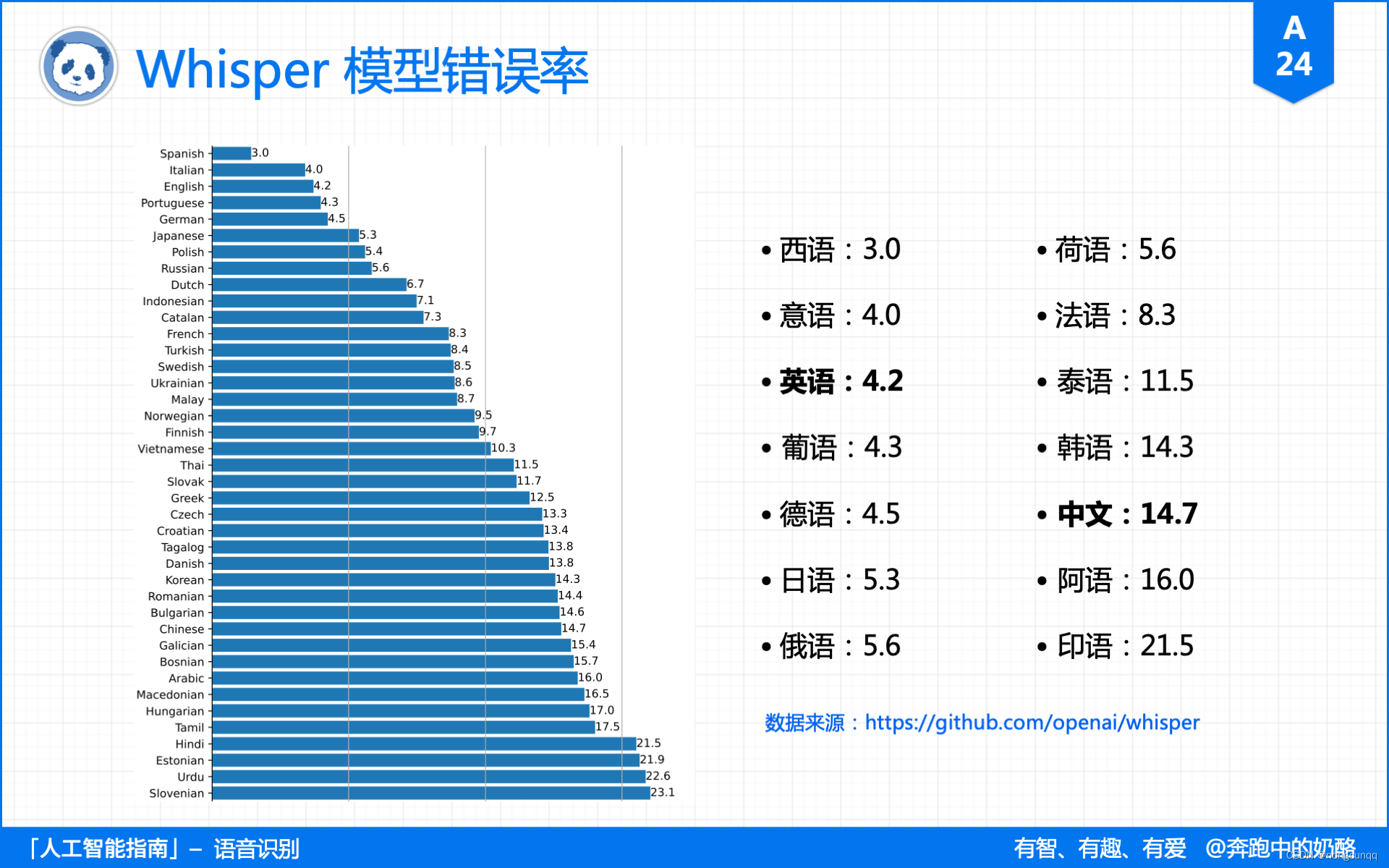
代理是一种中间层服务器,在客户端和目标服务器之间传送请求和响应。代理可以缓存请求结果,从而大大减少网络请求的次数,也可以隐藏客户端真实IP地址,避免被目标服务器识别。
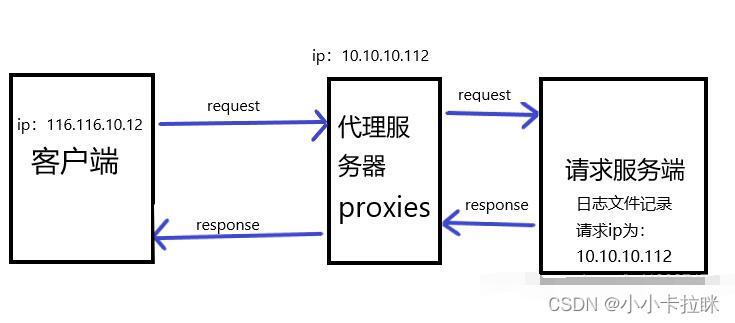
代理主要有以下作用:
- 隐藏客户端的真实IP地址,防止被服务器识别。
- 帮助访问本地系统无法访问的服务器。
- 缓存目标服务器的结果,避免重复请求浪费资源。
- 通过代理负载均衡优化网络请求的响应速度。
## 2. Python爬虫代理的使用方式
Python爬虫代理的使用,可以通过更改HTTP请求头信息或通过某些库辅助实现。例如,urllib和requests库中都已经提供了代理IP相关的设置方法。urllib库的代理IP设置可以通过创建代理处理器(proxy handler)实现:
import urllib.request
proxy_handler = urllib.request.ProxyHandler({'http': 'http://127.0.0.1:8000'})
opener = urllib.request.build_opener(proxy_handler)
urllib.request.install_opener(opener)
response = urllib.request.urlopen('http://httpbin.org/ip')
print(response.read().decode())代码中,即通过proxy_handler设置http代理进行访问。可以将这个代理handler作为参数传入build_opener创建一个opener,再通过urllib.request.install_opener()方法将opener设置为默认opener,最终通过response读取url对应的数据。如果proxy_handler、opener、install_opener方法都不清楚的话,可参阅Python标准库文档。
同样requests库中提供的代理IP设置代码如下:
import requests
proxies = {
"http": "http://127.0.0.1:8000",
"https": "http://127.0.0.1:8000",
}
response = requests.get('http://httpbin.org/ip',proxies=proxies)
print(response.content.decode())其中,在requests库中可以通过proxies参数设置代理IP,实现对目标网站的访问。
## 3. 代理IP的获取
在使用Python爬虫代理的过程中,要获取可用的代理IP非常关键。使用免费代理IP时,需要注意代理IP的质量和失效率,避免使用低质量的代理IP而导致爬虫失败或者被封禁。这里推荐站大爷代理IP供大家参考。

## 4. 多线程和多进程使用代理
在Python中,可以使用多线程和多进程技术,实现同时使用多个代理IP的效果,从而进一步提高爬取效率。其中,多线程技术可以使用threading库,多进程技术可以使用multiprocessing库。为了在爬虫中使用多个代理IP,可以将代理列表在多个线程及进程中共享,并对其进行有效地管理。
以下是使用多线程同时使用多个代理IP的示例代码:
import requests
import threading
proxies = ["http://127.0.0.1:8000", "http://127.0.0.1:8001", "http://127.0.0.1:8002", "http://127.0.0.1:8003"]
lock = threading.Lock()
def request_data(url, proxy):
with requests.session() as s:
s.proxies = {'http': proxy}
response = s.get(url=url)
print(response.text)
def main():
url = "http://httpbin.org/ip"
threads = []
for proxy in proxies:
thread = threading.Thread(target=request_data, args=(url, proxy))
thread.start()
threads.append(thread)
for thread in threads:
thread.join()
if __name__ == '__main__':
main()上述代码中,首先定义了一个代理列表`proxies`,然后定义了一个`request_data`函数用于进行爬取数据。利用每个线程使用不同的代理对目标网站进行访问,最终将多个线程的结果显示出来。其中,通过使用`threading.Lock()` 来进行线程锁,防止线程之间的代理混乱。
## 5. 请求头的设置
在Python爬虫的实际应用中,有许多网站通过检查HTTP请求头的信息来判断是否为爬虫程序。针对这种情况,我们需要设置一些自定义的HTTP请求头信息,以掩盖采集的真实性质。
可以通过requests库中的headers参数,以及urllib库中的Request对象来进行设置请求头信息。否则,操作系统或库默认的请求头信息会尝试插入到请求头中。
以下是通过requests库的headers参数来设置请求头的示例代码:
import requests
headers = {
"Host": "httpbin.org",
"Connection": "keep-alive",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"User-Agent": "Mozilla/5.0 (Windows NT x.y; rv:10.0) Gecko/20100101 Firefox/10.0",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "en-us,en;q=0.5",
"DNT": "1"}
proxies = {"http": "http://127.0.0.1:8000"}
response = requests.get(url, headers=headers, proxies=proxies)上面代码中,通过headers参数设置了一个自定义的HTTP请求头信息,其中包括了用户代理、连接类型、通信协议等信息。这些信息可以根据具体的目标网站情况适当进行更改。同时,同样通过proxies设置代理IP,实现对目标网站的优质访问。
总结
Python爬虫中代理的使用需要注意代理IP的质量和失效率,动态切换代理IP,多线程和多进程共享代理IP,以及设置HTTP请求头信息等方面。通过这些方法有效地优化爬虫,可以实现高效地爬取目标页面数据的目的。