接上次博客:https://mp.csdn.net/mp_blog/creation/editor/130934670
目录
1、锯齿形层序遍历
2、二叉搜索子树的最大键值和
3、验证二叉树
4、剑指 Offer II 047. 二叉树剪枝
最近临近期末,忙得焦头烂额的……
天天都是高数、微观经济学、线性代数与解析几何等等,还有好多大作业和线上考试啥的,抽时间做一些二叉树的 OJ 题,当成练习了。
等我考完期末考再继续更博客了。
1、锯齿形层序遍历
给你二叉树的根节点 root ,返回其节点值的锯齿形层序遍历 。(即先从左往右,再从右往左进行下一层遍历,以此类推,层与层之间交替进行)。
力扣链接:力扣
import java.util.*;
class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode() {}
TreeNode(int val) { this.val = val; }
TreeNode(int val, TreeNode left, TreeNode right) {
this.val = val;
this.left = left;
this.right = right;
}
}
public class Solution {
/*给你二叉树的根节点 root ,返回其节点值的 锯齿形层序遍历 。
(即先从左往右,再从右往左进行下一层遍历,以此类推,层与层之间交替进行)。*/
public List<List<Integer>> zigzagLevelOrder(TreeNode root) {
List<List<Integer>> result = new ArrayList<>();
if(root==null) return result;
//链表实现队列
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(root);
boolean reverse = false; // 控制是否需要反转
while (!queue.isEmpty()) {
int size = queue.size();
List<Integer> level = new ArrayList<>();
for (int i = 0; i < size; i++) {
TreeNode node = queue.poll();
level.add(node.val);
if (node.left != null) {
queue.offer(node.left);
}
if (node.right != null) {
queue.offer(node.right);
}
}
if (reverse) {
Collections.reverse(level);
}
result.add(level);
reverse = !reverse;
}
return result;
}
}力扣的官方题解就要更加复杂,他利用了「双端队列」的数据结构来维护当前层节点值输出的顺序,在广度优先搜索遍历当前层节点拓展下一层节点的时候,仍然从左往右按顺序拓展,但是对当前层节点的存储,维护一个变量,来记录是从左至右还是从右至左的:如果从左至右,我们每次将被遍历到的元素插入至双端队列的末尾。如果从右至左,我们每次将被遍历到的元素插入至双端队列的头部。
如下是力扣官方题解:
class Solution {
public List<List<Integer>> zigzagLevelOrder(TreeNode root) {
List<List<Integer>> ans = new LinkedList<List<Integer>>();
if (root == null) {
return ans;
}
Queue<TreeNode> nodeQueue = new ArrayDeque<TreeNode>();
nodeQueue.offer(root);
boolean isOrderLeft = true;
while (!nodeQueue.isEmpty()) {
Deque<Integer> levelList = new LinkedList<Integer>();
int size = nodeQueue.size();
for (int i = 0; i < size; ++i) {
TreeNode curNode = nodeQueue.poll();
if (isOrderLeft) {
levelList.offerLast(curNode.val);
} else {
levelList.offerFirst(curNode.val);
}
if (curNode.left != null) {
nodeQueue.offer(curNode.left);
}
if (curNode.right != null) {
nodeQueue.offer(curNode.right);
}
}
ans.add(new LinkedList<Integer>(levelList));
isOrderLeft = !isOrderLeft;
}
return ans;
}
}
2、二叉搜索子树的最大键值和
给你一棵以 root 为根的 二叉树 ,请你返回 任意 二叉搜索子树的最大键值和。
二叉搜索树的定义如下:
- 任意节点的左子树中的键值都 小于 此节点的键值。
- 任意节点的右子树中的键值都 大于 此节点的键值。
- 任意节点的左子树和右子树都是二叉搜索树。
比如: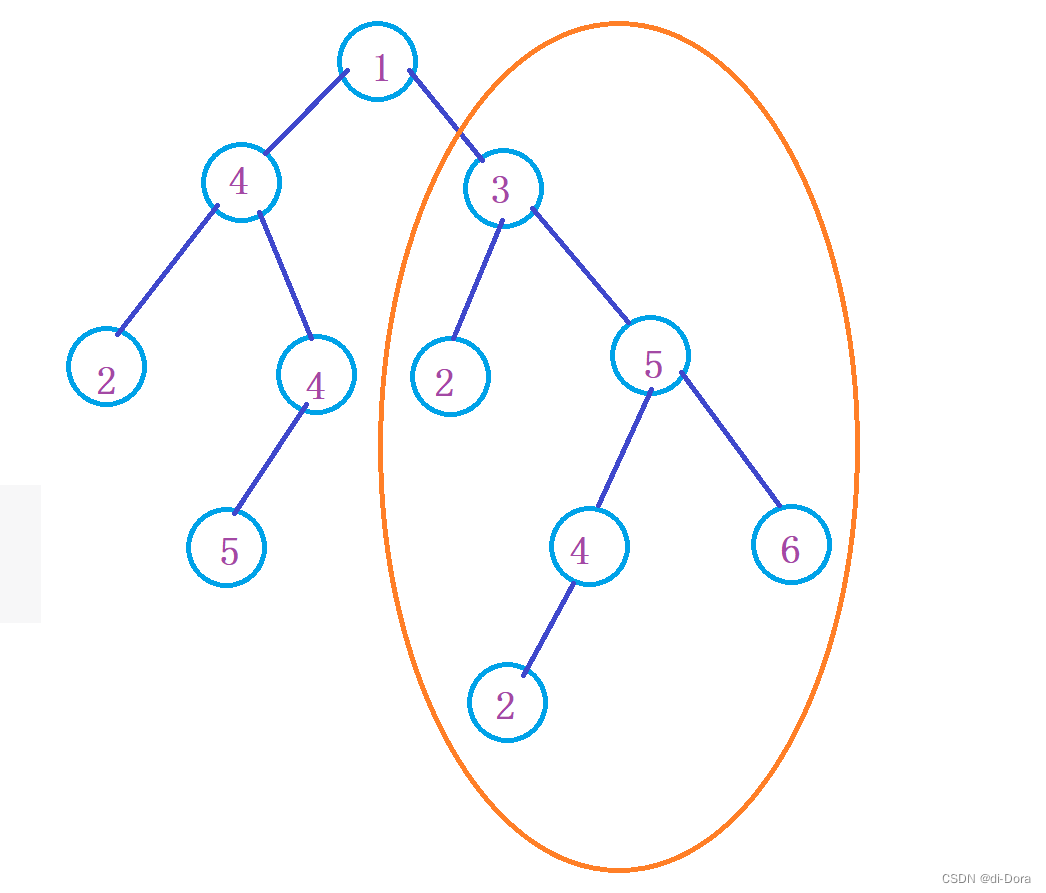
力扣链接:力扣
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
private class Result {
boolean isBST;
int minVal;
int maxVal;
int sum;
Result(boolean isBST, int minVal, int maxVal, int sum) {
this.isBST = isBST;
this.minVal = minVal;
this.maxVal = maxVal;
this.sum = sum;
}
}
private int maxSum;
public int maxSumBST(TreeNode root) {
maxSum = 0;
isBST(root);
return maxSum;
}
private Result isBST(TreeNode node) {
if (node == null) {
// 空节点视为有效的 BST
return new Result(true, Integer.MAX_VALUE, Integer.MIN_VALUE, 0);
}
Result left = isBST(node.left);
Result right = isBST(node.right);
// 判断当前节点是否满足 BST 的条件
boolean isBST = left.isBST && right.isBST && node.val > left.maxVal && node.val < right.minVal;
// 计算当前节点对应的 BST 的最小值和最大值
int minVal = Math.min(node.val, left.minVal);
int maxVal = Math.max(node.val, right.maxVal);
// 计算当前节点对应的 BST 的键值和
int sum = left.sum + right.sum + node.val;
if (isBST) {
maxSum = Math.max(maxSum, sum);
}
return new Result(isBST, minVal, maxVal, sum);
}
}在这个解决方案中,我们使用了递归来判断每个节点是否构成二叉搜索树,并计算其对应的键值和。对于每个节点,我们定义了一个 `Result` 类来存储判断结果和相关信息,包括当前节点是否构成二叉搜索树 (isBST)、当前节点对应的最小值和最大值 ( minVal 和 maxVal ),以及当前节点对应的键值和 (sum)。
在递归的过程中,我们先递归处理左子树和右子树,得到它们对应的 Result 对象。然后,我们根据当前节点的值和左右子树的最小值和最大值,判断当前节点是否构成二叉搜索树。如果满足条件,我们更新最大键值和 maxSum 。最后,返回当前节点对应的 Result 对象。
最终,我们返回 maxSum ,即任意二叉搜索子树的最大键值和。
注意,做题的时候,我们需要把所有节点都遍历一次,因为每个子树都有成为二叉搜索树的可能。即便我们可以根据某个节点的左子树不是二叉搜索树就可以确定该子树不是二叉搜索树,也需要去遍历该结点的右子树。因为其右子树及其子树仍有成为二叉搜索树的可能。
3、验证二叉树
二叉树上有 n 个节点,按从0到 n - 1 编号,其中节点i的两个子节点分别是 leftChild[i] 和 rightChild[i]。
只有所有节点能够形成且只形成一颗有效的二叉树时,返回 true;否则返回 false。
如果节点i没有左子节点,那么 leftChild[i] 就等于-1。右子节点也符合该规则。
注意:节点没有值,本问题中仅仅使用节点编号。
例如;输入:n = 4, leftChild = [1,-1,3,-1], rightChild = [2,-1,-1,-1]
输出:true
力扣链接:力扣
import java.util.*;
public class Main {
/*
* 二叉树上有 n 个节点,按从0到 n - 1 编号,其中节点i的两个子节点分别是 leftChild[i] 和 rightChild[i]。
只有所有节点能够形成且只形成一颗有效的二叉树时,返回 true;否则返回 false。
如果节点i没有左子节点,那么 leftChild[i] 就等于-1。右子节点也符合该规则。
注意:节点没有值,本问题中仅仅使用节点编号。
例如;输入:n = 4, leftChild = [1,-1,3,-1], rightChild = [2,-1,-1,-1]
输出:true
* */
public static void main(String[] args) {
System.out.println("Hello world!");
}
}
class Solution {
public boolean validateBinaryTreeNodes(int n, int[] leftChild, int[] rightChild) {
// 创建一个Set用于存储已经访问过的节点
Set<Integer> visited = new HashSet<>();
// 遍历所有节点
for (int i = 0; i < n; i++) {
// 检查当前节点是否已经被访问过,如果访问过则说明形成了环,返回false
if (visited.contains(i))
return false;
// 访问当前节点
visited.add(i);
// 获取当前节点的左子节点和右子节点
int left = leftChild[i];
int right = rightChild[i];
// 检查左子节点
if (left != -1) {
// 检查左子节点是否已经被访问过,如果访问过则说明存在重复访问,返回false
if (visited.contains(left))
return false;
// 访问左子节点
visited.add(left);
}
// 检查右子节点
if (right != -1) {
// 检查右子节点是否已经被访问过,如果访问过则说明存在重复访问,返回false
if (visited.contains(right))
return false;
// 访问右子节点
visited.add(right);
}
}
// 最后检查是否有孤立的节点,即节点未被访问过,返回false
return visited.size() == n;
}
}
/*这个解决方案使用了一个Set数据结构来存储已经访问过的节点。首先遍历所有节点,对于每个节点
,检查其是否已经被访问过,如果已经访问过,说明存在环,返回false。然后访问当前节点,并检查其左子节点和右子节点,
如果子节点已经被访问过,说明存在重复访问,返回false。最后检查是否有孤立的节点,即节点未被访问过,如果存在孤立节点,
返回false。如果所有节点都满足条件,返回true。*/
/*
*
* 解答错误
24 / 43 个通过的测试用例
输入
n =
4
leftChild =
[1,-1,3,-1]
rightChild =
[2,-1,-1,-1]
添加到测试用例
输出
false
预期结果
true
* */
/*
* 我检查了一下代码,发现我没有考虑到根节点的情况。
* 根节点应该是没有父节点的,但是在原来的实现中没有对根节点进行判断。下面是修复后的代码:
* */
class Solution2 {
public boolean validateBinaryTreeNodes(int n, int[] leftChild, int[] rightChild) {
// 创建一个Set用于存储已经访问过的节点
Set<Integer> visited = new HashSet<>();
// 记录节点的父节点
int[] parent = new int[n];
Arrays.fill(parent, -1);
// 遍历所有节点
for (int i = 0; i < n; i++) {
// 检查当前节点是否已经被访问过,如果访问过则说明形成了环,返回false
if (visited.contains(i))
return false;
// 访问当前节点
visited.add(i);
// 获取当前节点的左子节点和右子节点
int left = leftChild[i];
int right = rightChild[i];
// 检查左子节点
if (left != -1) {
// 检查左子节点是否已经被访问过,如果访问过则说明存在重复访问,返回false
if (visited.contains(left))
return false;
// 检查左子节点是否已经有父节点,如果有,则返回false
if (parent[left] != -1)
return false;
// 记录左子节点的父节点
parent[left] = i;
// 访问左子节点
visited.add(left);
}
// 检查右子节点
if (right != -1) {
// 检查右子节点是否已经被访问过,如果访问过则说明存在重复访问,返回false
if (visited.contains(right))
return false;
// 检查右子节点是否已经有父节点,如果有,则返回false
if (parent[right] != -1)
return false;
// 记录右子节点的父节点
parent[right] = i;
// 访问右子节点
visited.add(right);
}
}
// 最后检查是否有孤立的节点,即节点未被访问过,返回false
return visited.size() == n;
}
}
/*
*
* 解答错误
24 / 43 个通过的测试用例
输入
n =
4
leftChild =
[1,-1,3,-1]
rightChild =
[2,-1,-1,-1]
添加到测试用例
输出
false
预期结果
true
* */
/*
* 经过仔细检查,我发现在判断孤立节点的部分出现了问题。
* 孤立节点是指没有父节点的节点,但是在原来的实现中没有正确地进行判断。下面是修复后的代码:
* */
class Solution3 {
public boolean validateBinaryTreeNodes(int n, int[] leftChild, int[] rightChild) {
// 记录节点的入度
int[] inDegree = new int[n];
// 遍历所有节点
for (int i = 0; i < n; i++) {
int left = leftChild[i];
int right = rightChild[i];
// 检查左子节点
if (left != -1) {
// 左子节点的入度加1
inDegree[left]++;
// 如果左子节点的入度大于1,说明存在多个父节点,返回false
if (inDegree[left] > 1)
return false;
}
// 检查右子节点
if (right != -1) {
// 右子节点的入度加1
inDegree[right]++;
// 如果右子节点的入度大于1,说明存在多个父节点,返回false
if (inDegree[right] > 1)
return false;
}
}
// 统计入度为0的节点个数
int rootCount = 0;
for (int i = 0; i < n; i++) {
if (inDegree[i] == 0)
rootCount++;
// 如果有多个入度为0的节点,说明存在多个根节点,返回false
if (rootCount > 1)
return false;
}
// 如果没有入度为0的节点,说明存在环或有孤立节点,返回false
if (rootCount == 0)
return false;
// 如果所有节点都满足条件,返回true
return true;
}
}
/*
* 这次的修复主要针对孤立节点和根节点进行了判断。通过记录每个节点的入度,然后统计入度为0的节点个数,如果入度为0的节点个数不为1,
* 说明存在多个根节点,返回false;如果入度为0的节点个数为0,说明存在环或有孤立节点,返回false。如果所有节点都满足条件,返回true。
* */
/*
* 解答错误
39 / 43 个通过的测试用例
输入
n =
4
leftChild =
[1,0,3,-1]
rightChild =
[-1,-1,-1,-1]
添加到测试用例
输出
true
预期结果
false
* */
/*
在修复过程中,我没有考虑到二叉树的根节点应该有且只有一个,
但是在原来的实现中没有对根节点个数进行判断。下面是修复后的代码:
* */
class Solution4 {
public boolean validateBinaryTreeNodes(int n, int[] leftChild, int[] rightChild) {
// 记录节点的入度
int[] inDegree = new int[n];
// 遍历所有节点
for (int i = 0; i < n; i++) {
int left = leftChild[i];
int right = rightChild[i];
// 检查左子节点
if (left != -1) {
// 左子节点的入度加1
inDegree[left]++;
// 如果左子节点的入度大于1,说明存在多个父节点,返回false
if (inDegree[left] > 1)
return false;
}
// 检查右子节点
if (right != -1) {
// 右子节点的入度加1
inDegree[right]++;
// 如果右子节点的入度大于1,说明存在多个父节点,返回false
if (inDegree[right] > 1)
return false;
}
}
// 统计入度为0的节点个数和根节点
int rootCount = 0;
int rootNode = -1;
for (int i = 0; i < n; i++) {
if (inDegree[i] == 0) {
rootCount++;
rootNode = i;
}
// 如果有多个入度为0的节点,说明存在多个根节点,返回false
if (rootCount > 1)
return false;
}
// 如果没有入度为0的节点,说明存在环或有孤立节点,返回false
if (rootCount == 0)
return false;
// 检查是否能够遍历到所有节点
Set<Integer> visited = new HashSet<>();
if (!dfs(rootNode, leftChild, rightChild, visited))
return false;
// 如果所有节点都满足条件,返回true
return visited.size() == n;
}
private boolean dfs(int node, int[] leftChild, int[] rightChild, Set<Integer> visited) {
if (node == -1)
return true;
// 检查当前节点是否已经被访问过,如果访问过则说明形成了环,返回false
if (visited.contains(node))
return false;
// 访问当前节点
visited.add(node);
// 递归遍历左子节点和右子节点
return dfs(leftChild[node], leftChild, rightChild, visited) && dfs(rightChild[node], leftChild, rightChild, visited);
}
}
/*
* 修复后的代码在判断根节点个数时引入了一个变量rootNode,用于记录入度为0的节点的编号。然后在检查是否能够遍历到所有节点时,
* 使用DFS遍历二叉树,检查节点是否已经访问过,如果已经访问过,说明存在环,返回false。如果所有节点都满足条件,返回true。
* */
4、剑指 Offer II 047. 二叉树剪枝
给定一个二叉树 根节点 root ,树的每个节点的值要么是 0,要么是 1。请剪除该二叉树中所有节点的值为 0 的子树。
节点 node 的子树为 node 本身,以及所有 node 的后代。
力扣链接:力扣
class Solution5 {
public TreeNode pruneTree(TreeNode root) {
if (root == null) {
return null;
}
// 递归剪枝左子树和右子树
root.left = pruneTree(root.left);
root.right = pruneTree(root.right);
// 如果当前节点的值为0且左右子树都为空,则将当前节点剪除
if (root.val == 0 && root.left == null && root.right == null) {
return null;
}
return root;
}
}这题好简单的,没啥好说的,更难的我们都做过了,其实就是递归的思想。