批处理(Batch Processing)是指在深度学习中每次迭代更新模型参数时同时处理多个样本的方式。
批处理时要注意对应维度的元素个数要一致
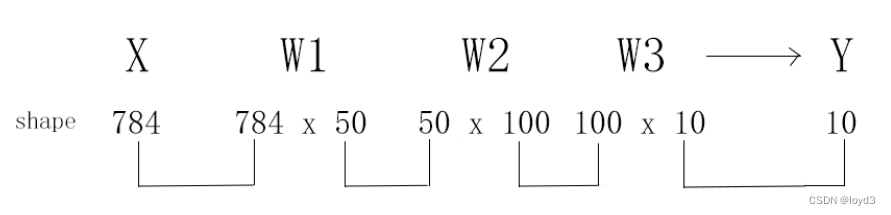
关于之前手写数字识别的例子:
用图表示,可以发现,多维数组的对应维度的元素个数确实是一致的。此外,还可以确认最终的结果是输出元素个数为10的一维数组。
现在来考虑打包输入多张图像的情形。
我们想用predict函数一次性打包处理100张图像。为此,可以把的形状改为100 x 784,将100张图像打包作为输人数据。用图表示的话
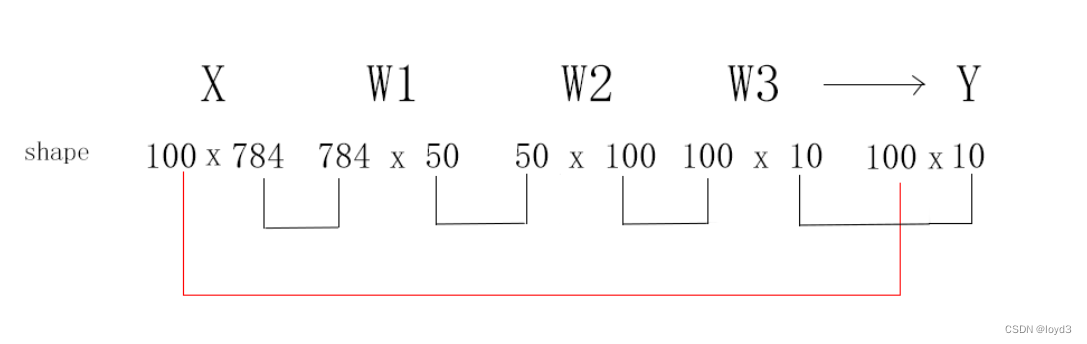
可以发现最后输出数据的形状100 x 10。
这种打包式的输人数据称为批(batch)。
批处理对计算机的运算大有利处,可以大幅缩短每张图像的处理时间。
下面我们进行基于批处理的代码实现。
x,t = get_data()
network= init_network()
batch_size = 100 # 批数量
accuracy_cnt = 0
for i in range(0,len(x),batch_size):
x_batch = x[i:i+batch_size]
y_batch = predict(network,x_batch)
p= np.argmax(y_batch,axis=1)
accuracy_cnt += np.sum(p == t[i:i+batch_size])
print("Accuracy:"+str(float(accuracy_cnt) / len(x)))
通过x[i:i+batch_size]从输入数据中抽出批数据,然后,通过argmax()获取值最大的元素的索引,要注意的是这里给定了axis =1,也意味着在100 x 10的数组中,沿着第1维方向(以第1维为轴)找到值最大的元素的索引(矩阵的第0维是列方向,第1维是行方向),看下面这个例子:
>>>x = np.array([[0.1,0.8,0.1], [0.3,0.1,0.6], [0.2,0.5,0.3], [0.8,0.1,0.1]])
>>>y=np.argmax(x, axis=1)
>>>print(y)
[1 2 1 0]
在实现批处理时,需要注意以下几个方面:
内存限制:批处理大小应该根据硬件设备的内存大小来设置,防止内存溢出。
数据划分:将训练数据划分成多个批次时,应该保证每个批次的样本分布相似,避免训练出现偏差。
学习率调整:批处理的使用可能会对学习率的选择产生影响,需要对学习率进行相应的调整。