头文件
C语言的引用头文件的方式是include名字.h的方式进行引用,而C++去掉了.h,但是又是完全兼容C语言的。在库前面添加一个c来表明这个库是来自于C语言的。
//C语言的方法:带.h的方式进行include
#include<stdio.h>
#include<math.h>
//C++的方法,直接引用即可
#include<cstdio>
#include<cmath>
如果是c++自己的库,则使用命名空间std标准库引入,无需后缀,直接引入名称即可。
#include<iostream> //输入输出流所包含的头文件
using namespace std; //C++标准库中的类和函数是在命名空间std中声明的
c++完全兼容c,因此c语言的标准库在c++中也是可以使用的,所以为了区分c++程序需要使用
using namespace std;重新定义c++的标准库,不至于与c的标准库混淆。
输入输出函数
C语言输出为格式化输出,必须指定输出类型。
int n; //定义n为整形
//C语言的输入输出(需要指定类型,如下指定为整形)
scanf("%d",&n);
printf("%d",n);
C++输出采用流的思想输出,无需指明数据类型,注意必须引入iostream库函数时才可以使用。
//C++语言的输入输出(不需要指定类型,会根据n进行自主的判定)
cin>>n;
cout<<n;
在c语言中语法只实现了基本的功能,例如表的数据结构还需要开发者自己编程,但是在c++中,出现了STL-Standard Template Library的简称,标准模板库。STL是一些“容器”与“算法”的集合,这些“容器”无非就是已经实现好了数据结构,能够让程序设计者更为方便的进行调用。
在C++标准中,STL被组织为下面的13个头文件:
<algorithm>、<deque>、<functional>、<iterator>、<vector>、<list>、<map>、<memory>、<numeric>、<queue>、<set>、<stack>和<utility>。
例如顺序表,链表的数据结构在lust库中,无需开发者再次编写顺序表的操作,直接引用库中写好的就可以。
串
在c语言中字符为基本数据类型,多个字符组成串,串也是一种数据结构,转用于存储字符,作用比较单一。对该数据结构的操作方法有:strlen:求字符串长度;strcmp:字符串比较;strcat:字符串连接;strcpy:字符串复制等方法,而在c++中将串也定义为基本数据类型,并在STL中添加了串的操作。
int main(){
/*
int n;
cin>>n;
cout<<n;
*/
char chr[10] = {'h','e','l','l','o'};
int i;
for(i=0;i<5;i++){
printf("%c",chr[i]);
}
char *p = "hello";
int i;
for(i=0;i<5;i++){
printf("%c",p[i]);
}
return 0;
}
#include<iostream>
using namespace std;
int main(){
string str = "hello";
cout<<str;
return 0;
}
引用
引用是C++引入的新语言特性,是C++常用的一个重要内容之一。引用就是某一变量(目标)的一个别名,对引用的操作与对变量直接操作完全一样。
在赋值操作中定义变量初始化是值传递,即使值一样也会给变量分配新的内存空间,在指针传递时,是直接传递的变量地址,对地址操作从而实现对原变量的操作。
引用变量是为了简化指针操作的复杂性,c++引入引用的概念,引用是对变量的重命名,对引用变量的修改也是从地址层面修改,完全等价于对变量本身修改。但是引用传递必须遵循:
①一个变量可取多个别名。
②引用必须初始化。
③引用只能在初始化的时候引用一次 ,不能更改为转而引用其他变量。
引用使用符号&定义int &a注意在定义是必须初始化:
int a = 10;
int &b = a;
对b的操作完全等价于对a直接操作。
引用类型做参数时发生的是引用传递,引用传递过程中,被调函数的形式参数虽然也作为局部变量在栈中开辟了内存空间,但是这时存放的是由主调函数放进来的实参变量的地址。被调函数对形参的任何操作都被处理成间接寻址,即通过栈中存放的地址访问主调函数中的实参变量。正因为如此,被调函数对形参做的任何操作都影响了主调函数中的实参变量。
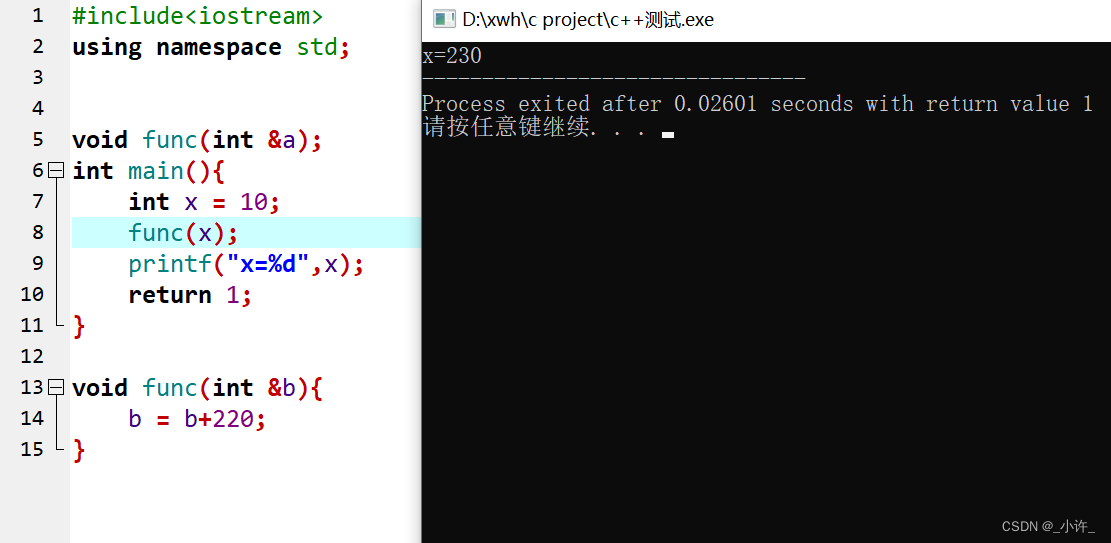
引用类型做参数时发生引用传递,系统自动初始化引用变量等于主函数变量。
引用做返回值
- 普通变量做返回值
#include<iostream>
using namespace std;
int func(int &a);
int main(){
int x = 1000;
int a = func(x);
printf("%d",a);
}
//普通返回值
int func(int &b){
return b+1000; //值传递产生新的地址空间(局部变量赋值新地址后销毁)
}
普通变量做返回值时
return b+1000实际上是返回的临时变量,会随函数的结束而销毁,但是由于普通变量是值传递,声明时会分配空间存储临时变量。
- 指针返回值

在途中指针类型在声明不会分配内存空间,临时变量无地址存储会报错。

在全局声明并初始化后就存在空间存储临时变量了。
- 引用做返回值
引用变量必须初始化,所以在作为函数返回值时必须存在全局变量,用来对引用变量初始化,函数中的局部变量随函数结束小时无法对引用变量初始化。
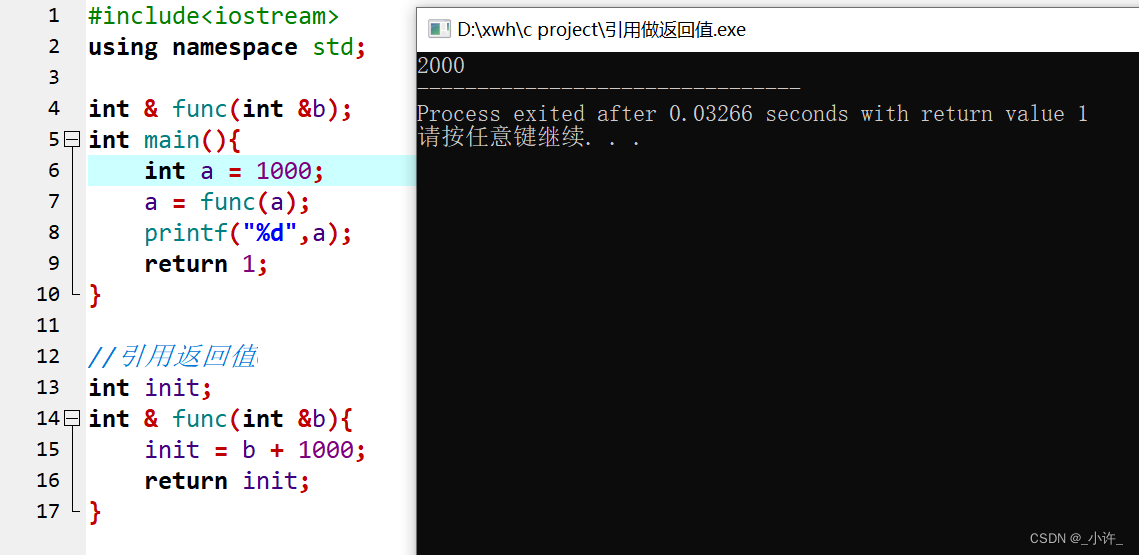
通过声明int init后该变量就是函数的专属返回值,甚至不需要变量接受函数的返回值,如下:
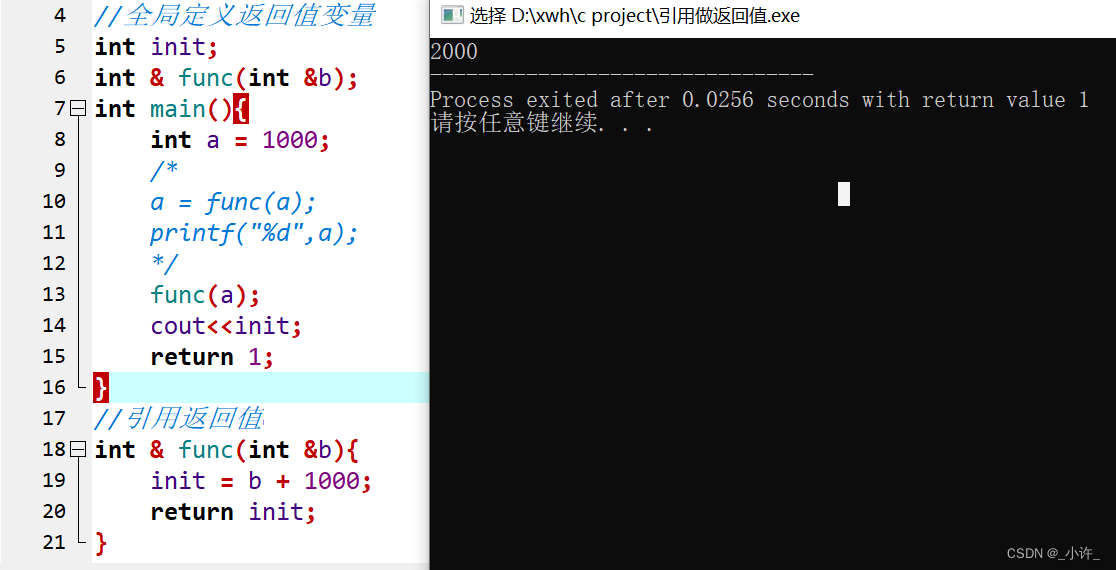
#include<iostream>
using namespace std;
//全局定义返回值变量
int init;
int & func(int &b);
int main(){
int a = 1000;
/*
a = func(a);
printf("%d",a);
*/
func(a);
cout<<init;
return 1;
}
//引用返回值
int & func(int &b){
init = b + 1000;
return init;
}
变量也可以使用C++ 存储类修饰,如static 存储类指示编译器在程序的生命周期内保持局部变量的存在,static 修饰符也可以应用于全局变量。当 static 修饰全局变量时,会使变量的作用域限制在声明它的文件内。extern 存储类用于提供一个全局变量的引用,全局变量对所有的程序文件都是可见的。当您使用 ‘extern’ 时,对于无法初始化的变量,会把变量名指向一个之前定义过的存储位置。extern 是用来在另一个文件中声明一个全局变量或函数。
类
c++添加看新的特性类。
在c语言中程序中结构体是使用最广泛的信息载体,结构体与基本数据类型基本可以满足所有的数据结构的要求。但是对于实体来说每个实体后会有自己的行为,那么可以通过方法作为行为。
对于串变量来说,串的比较,串的赋值,串的计算都可以使用相关的方法来完成。但是由于串的局限性,这些方法只能用户串的操作,是串类型私有的。但是这些方法却在公开区,任何实体都可以用(会报错),这显然是不合理的。类的出现解决了行为(方法)的归属问题,一些行为只归属某个类,并且只能被该类使用。
定义一个类需要使用关键字 class,然后指定类的名称,并类的主体是包含在一对花括号中,主体包含类的成员变量和成员函数。
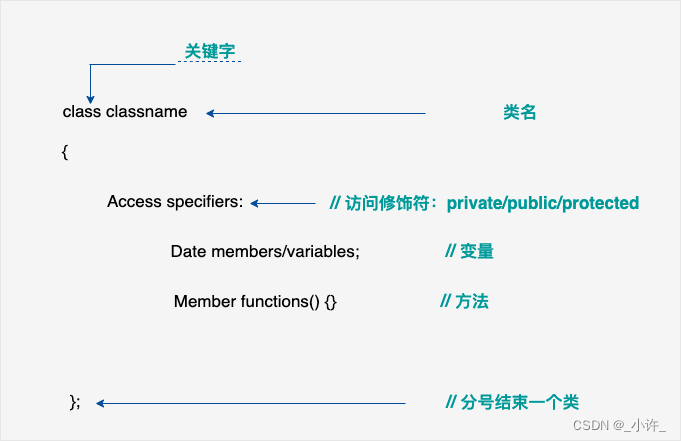
更多移步C++ 类 & 对象
异常处理
c++提供全新的异常处理机制,处理程序执行期间出现的各种问题。C++ 异常处理涉及到三个关键字:try、catch、throw。
- throw: 当问题出现时,程序会抛出一个异常。这是通过使用 throw 关键字来完成的。
- catch: 在您想要处理问题的地方,通过异常处理程序捕获异常。catch 关键字用于捕获异常。
- try: try 块中的代码标识将被激活的特定异常。它后面通常跟着一个或多个 catch 块。
try
{
// 保护代码
}catch( ExceptionName e1 )
{
// catch 块
}catch( ExceptionName e2 )
{
// catch 块
}catch( ExceptionName eN )
{
// catch 块
}
可以使用 throw 语句在代码块中的任何地方抛出异常。throw 语句的操作数可以是任意的表达式,表达式的结果的类型决定了抛出的异常的类型。
double division(int a, int b)
{
if( b == 0 )
{
throw "Division by zero condition!";
}
return (a/b);
}
c++标准异常
动态内存分配
在 C++ 中,您可以使用特殊的运算符为给定类型的变量在运行时分配堆内的内存,这会返回所分配的空间地址。这种运算符即 new 运算符。
如果不再需要动态分配的内存空间,可以使用 delete运算符,删除之前由 new 运算符分配的内存。
在c语言中动态分配地址的是malloc函数,释放地址的是free方法,不同的是new是malloc的超集,集成了c++的一些新增的数据结构如string,类等并且使用起来更简单。
和malloc相似的是new申请的地址是分配在堆内存的是全局的,存在于程序的整个生命周期,除非使用delete释放。即使在局部函数中申请也是全局的。
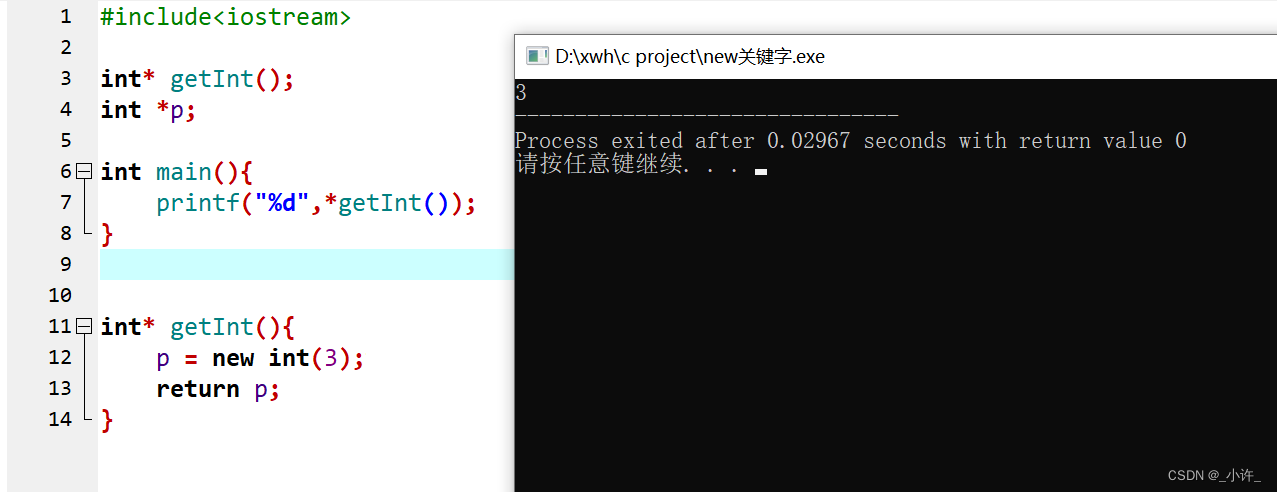
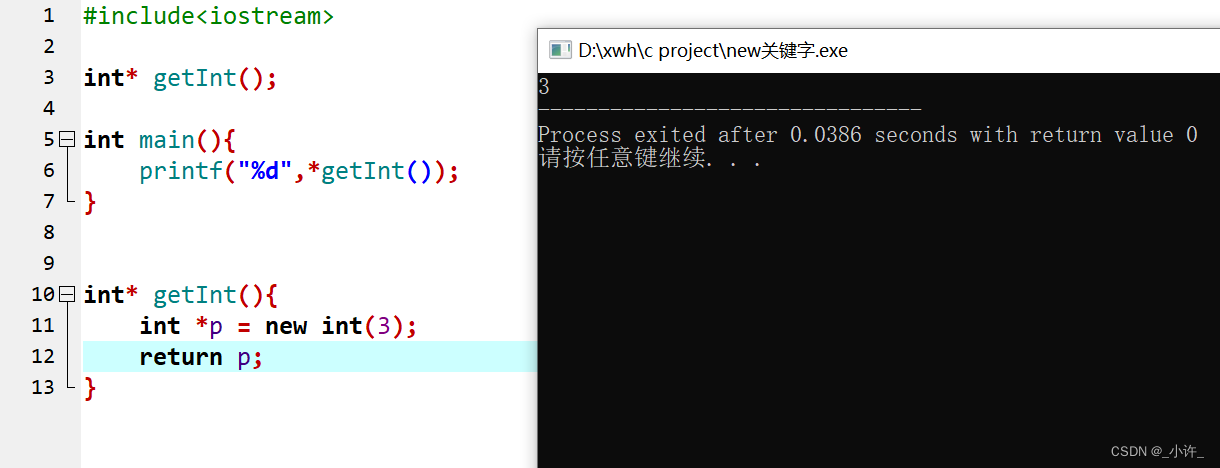
在函数类定义的指针p,函数结束后该地址任然存在,证明new分配的地址还在程序生命周期中。
C++ 命名空间
C++ 命名空间
在c,我们可以通过#include<XXX.h>引入系统STL,c++中模块名引入,也可以通过#include"XXX.h"引入自定义的模块。随着模块的增多,模块难免出现一些同名的函数或者变量。
在c语言中是不允许同名的,如下:
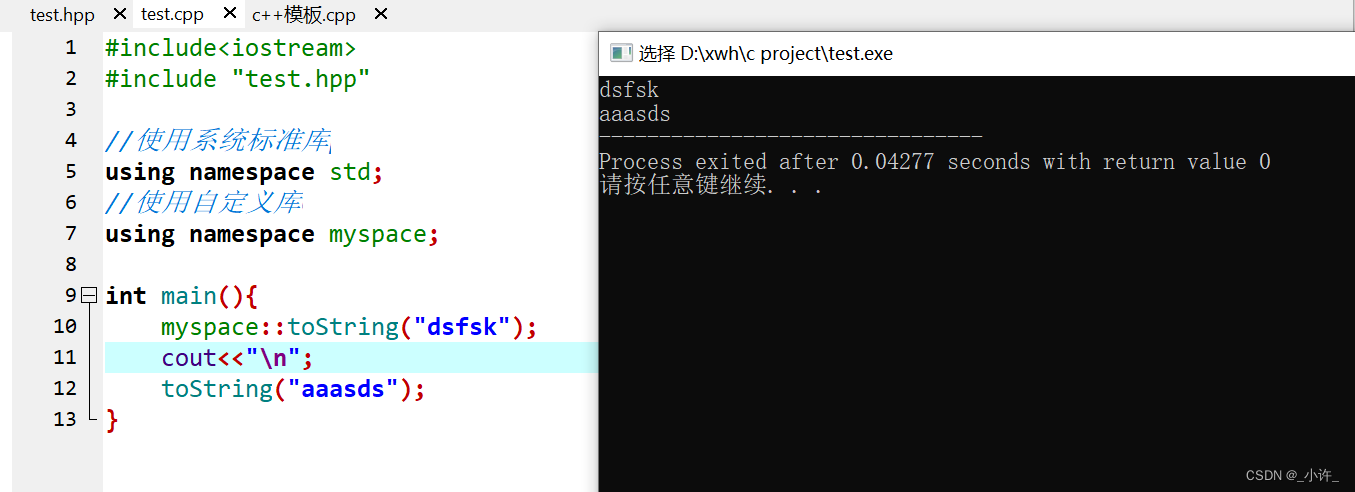
test.h中定义了toString方法。
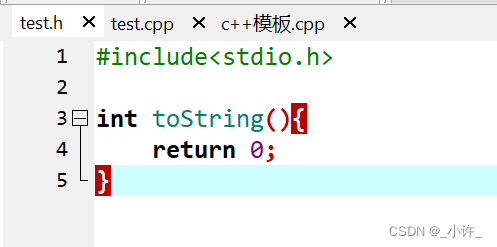
test.c中引入test.h并再次定义toString方法
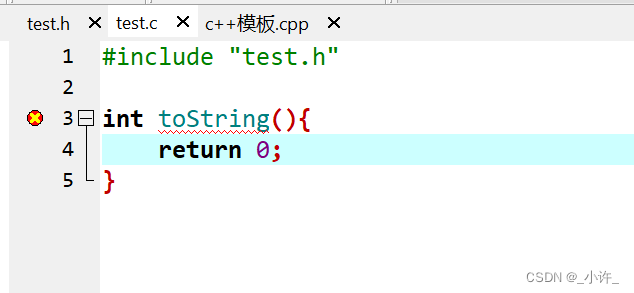
如图所示编辑器会直接报错。
在c++中却是可以定义相同的变量的,通过命名空间来区分不同方法或变量的归属。
- 定义
c++中通过namespace space_name定义命名空间,方法和变量都定义在命名空间中,如下:
#include<iostream>
namespace myspace{
//std是默认导入的标准库 using namespace std
int toString(int str){
cout<<str;
}
}
也就是说在在最外层用namepsace包裹起来。
- 调用
调用带有命名空间的函数或变量,需要在前面加上命名空间的名称,通过::调用。
space_name :: code;
注意space_name是自定义的名称,::是调用符号,code是调用的变量或者方法。
注意调用前一定要先引入头文件。
演示:
- 头文件test.hpp中定义命名空间
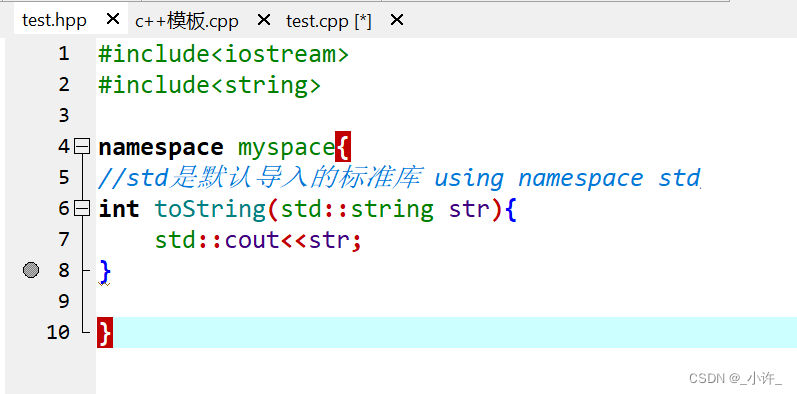
- 引入头文件
- 命名空间名称调用方法或变量
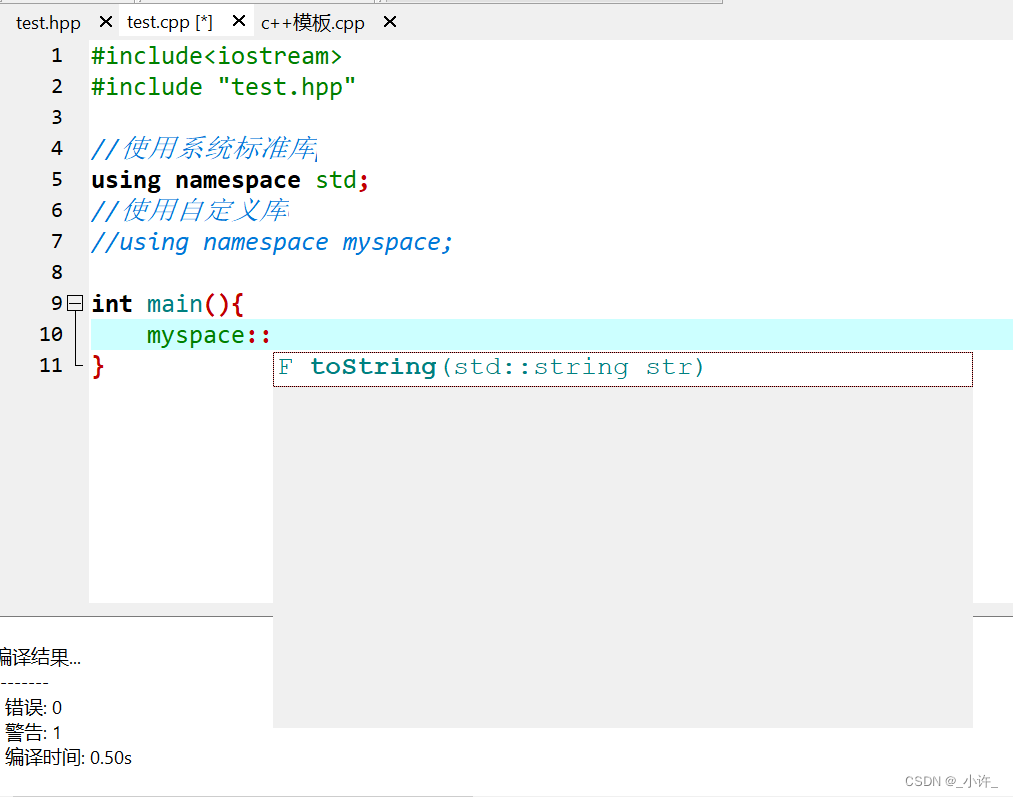
每次在调用是都需要带上命名空间名称和调用符,比较麻烦,可以通过
using 指令来直接引入当前空间内。
//如必要的系统标准库的引入
using namespace std;
//自定义的引入
using namespace myspace;
这样在程序中直接调用头文件中的方法和变量,同时也解决了方法名重复的问题。当方法或变量名重复时带上命名空间就可以了。
泛型
一文带你搞懂 Java 泛型
- 认识泛型
#include<iostream>
using namespace std;
class IntArray{
private : int item[100];
private : int cacur = 0;
public :
void Push(int x){
item[cacur] = x;
cacur ++;
}
int Pop(){
cacur --;
int e = item[cacur];
return e;
}
};
int main(){
IntArray arr;
for(int i=0;i<=5;i++){
//TODO
arr.Push(i+1);
}
for(int i=0;i<=5;i++){
//TODO
int e = arr.Pop();
cout<<e;
}
}
上述代码定义了一个IntArray的对象,用该对象模拟栈,类成员item数组存储元素,类型为int;成员cacur为游标记录位置。类包含两个方法Push添加,和Pop删除。
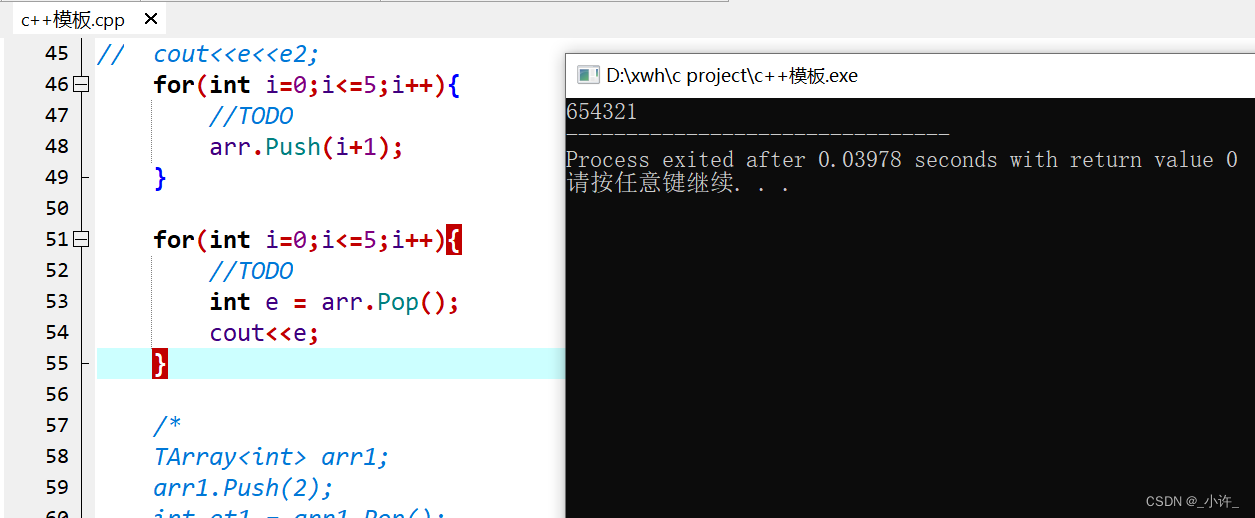
现在该类只能存储int类型,那么如果想存储float,double,struct甚至是class类型呢?
于是就引入了泛型的概念,泛型就是泛指各种类型,任意类型。那么只要定义一个任意类型,程序的所有都可以传递。
- 使用泛型
#include<iostream>
using namespace std;
template <typename T>
T Max(T a,T b){
return a>b?a:b;
}
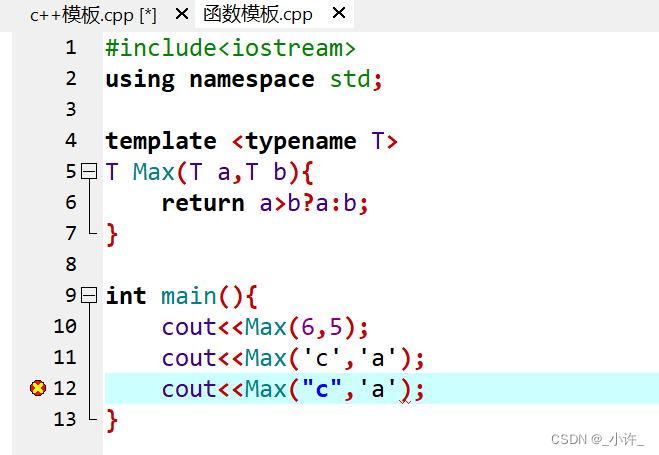
int main(){
cout<<Max(6,5);
cout<<Max(6.5,5.4);
cout<<Max('c','a');
}
虽然定义的T为任意类型,但是在传递是同一部分的T必须是同一类型。下面就是错误的。
函数泛型
在函数中使用的泛型为函数泛型。定义方式如下:
template <typename T>
template <typename T>
T Max(T a,T b){
return a>b?a:b;
}
类泛型
在类上定义的泛型为类泛型,定义方式如下:
template <class T>
template <class T>
class TArray{
private : T item[100];
private : int cacur = 0;
public :
void Push(T x){
item[cacur] = x;
cacur ++;
}
T Pop(){
cacur --;
T e = item[cacur];
return e;
}
};
继初识泛型时模拟栈的存储,上述代码定义了类泛型,并存储任意类型变量。
int main{
TArray<int> arr1;
//存储int
arr1.Push(2);
//存储float
arr1.Push(4.7);
//存储char
arr1.Push('a');
int et1 = arr1.Pop();
int et2 = arr.Pop();
int et3 = arr1.Pop();
cout<<et1<<"-"<<et2<<"-"<<et3;
return 0;
}
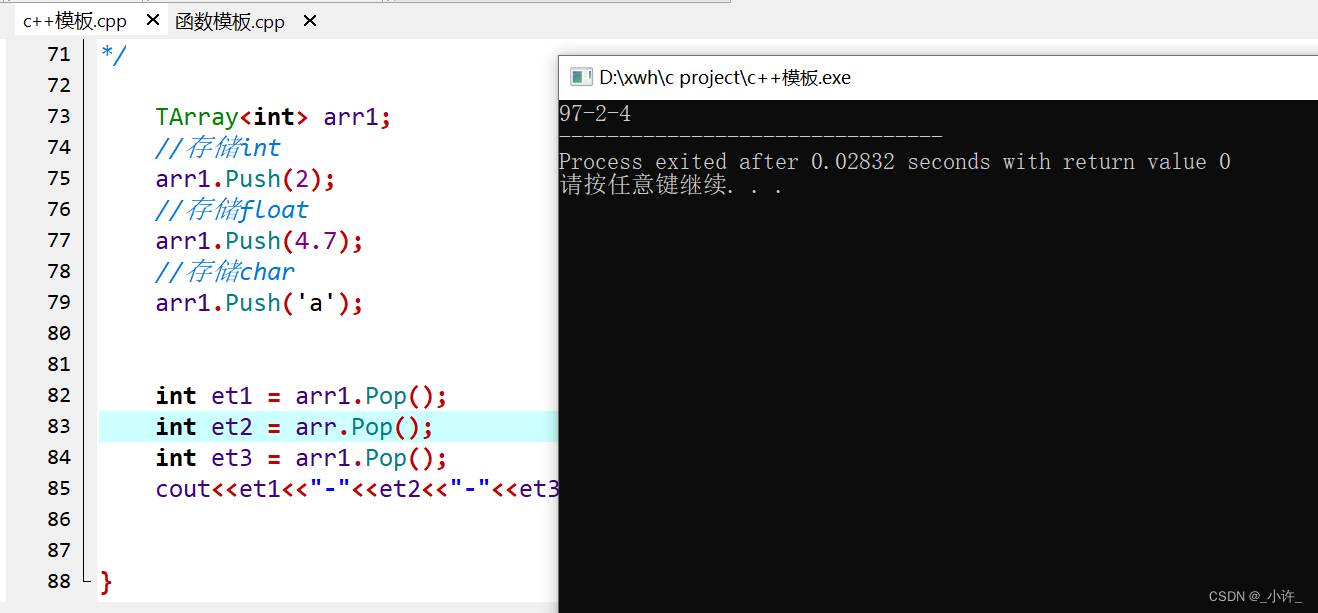
在入栈操作分别插入了三种数据类型,但是在出栈是却不知道是什么类型,这里全用int接收了,这里会涉及到类型转换,但是如果用char类型接收类型转换就会报错,程序就会错误。
c++的泛型作为参数时,会根据传入的实际类型自动转换,形参T只是占位符。也就是说在编译器在对泛型形参操作时其本身是知道数据类型的。
因此,一般情况下一个表中只存储一种数据类型,用作限定使用限定符<>.
TArray<int> arr;
TArray<int> arr1;
//存储int
arr1.Push(2);
//存储float
arr1.Push(4);
//存储char
arr1.Push(5);
int et1 = arr1.Pop();
int et2 = arr.Pop();
char et3 = arr1.Pop();
cout<<et1<<"-"<<et2<<"-"<<et3;
这样限定表中存储的元素都是int,便于取出元素。
·