文章目录
- 669.修剪二叉搜索树
- 思路
- 错误代码示例
- 最开始的写法
- debug测试
- 逻辑错误:
- 需要两次递归的原因
- 内存操作报错:操作了已经被删除的内存的指针(力扣平台delete操作的问题,放IDE里就好了)
- 打日志debug示例
- 力扣平台delete问题的应对方案
- 完整版
- 108.将有序数组转换为二叉搜索树(递归参数引用or值传递)
- 思路
- 完整版
- 递归参数的引用传递和值传递
- 必须使用引用传递的例子:
- 必须使用值传递的例子:
- 如果nums使用了值传递,会增加多少开销?
- 538.把二叉搜索树转换为累加树(思路注意)
- 思路
- 最开始的写法
- debug测试
- 空指针访问出错
- 逻辑错误
- 修改后的完整版
- 必须定义全局变量的原因
- 遍历的进一步理解
- 一些补充
669.修剪二叉搜索树
- 这种删除操作,最重要的就是接收下层返回的节点,再进行连接
- 本题与 450.删除节点 的最大区别就是,本题在发现root不符合要求的时候,root的左右孩子并不能直接继位!需要通过递归找到确定符合条件的左孩子/右孩子才可以。
给你二叉搜索树的根节点 root ,同时给定最小边界low 和最大边界 high。通过修剪二叉搜索树,使得所有节点的值在[low, high]中。修剪树 不应该 改变保留在树中的元素的相对结构 (即,如果没有被移除,原有的父代子代关系都应当保留)。 可以证明,存在 唯一的答案 。
所以结果应当返回修剪好的二叉搜索树的新的根节点。注意,根节点可能会根据给定的边界发生改变。
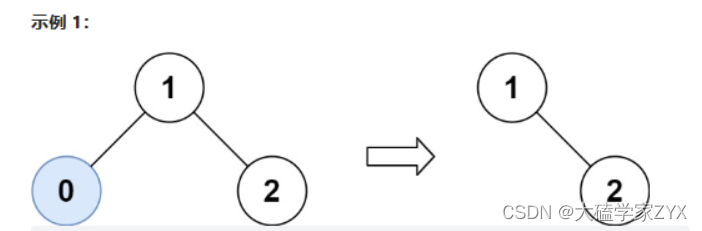
输入:root = [1,0,2], low = 1, high = 2
输出:[1,null,2]
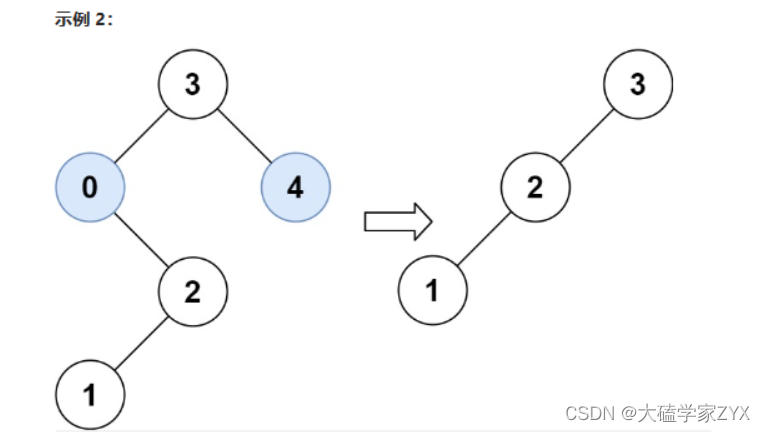 输入:root = [3,0,4,null,2,null,null,1], low = 1, high = 3
输入:root = [3,0,4,null,2,null,null,1], low = 1, high = 3
输出:[3,2,null,1]
提示:
- 树中节点数在范围 [1, 10^4] 内
0 <= Node.val <= 104- 树中每个节点的值都是 唯一 的
- 题目数据保证输入是一棵有效的二叉搜索树
0 <= low <= high <= 104
思路
本题比添加节点和删除节点都要复杂,添加节点只需要在叶子节点处添加,不需要修改树的结构;删除节点复杂一些,会根据不同情况适当改变树的结构。
但是本题要删除的节点不止一个,修剪的操作需要删除所有不在范围内的节点。
删除的操作是,我们直接把要删除节点的右子树返回给上一层,让被删除节点的父节点直接指向这个要删除节点的右孩子,就移除了这个节点。
错误代码示例
- 这种删除操作,最重要的就是接收下层返回的节点,再进行连接,每一层都return root,这是删除操作最重要的逻辑
- 删除操作不能直接return null,因为return null的话空节点就成了树的中间节点,null是不能保留在中间的!空节点不能成为二叉树的中间节点。
TreeNode* travelsal(TreeNode* root,int high,int low){
//遍历到nullptr,return给上一层
if(root==nullptr){
return nullptr;
}
//遍历节点值的判断
//如果节点不在范围内,注意这里是逻辑或||
if(root->val<low||root->val>high){
//进行删除操作
//不能直接return nullptr
//return nullptr;
}
//接收下层返回的数值,并连接返回值
root->left = travelsal(root->left,high,low);
root->right = travelsal(root->right,high,low);
return root;
}
最开始的写法
- 大框架是不变的,修改删除逻辑
- 因为这是BST,所以,当某个节点<low的时候,说明这个节点的所有左子树,都不满足要求,所以应该直接返回节点的右子树!
- 右子树里面也可能有元素不满足要求,也<low,因此右子树内部也需要进行遍历
class Solution {
public:
TreeNode* trimBST(TreeNode* root, int low, int high) {
//遍历到nullptr,return给上一层
if(root==nullptr){
return nullptr;
}
//遍历节点值的判断
//如果节点不在范围内,注意这里是逻辑或||
if(root->val<low){
//进行删除操作,当某个节点<low的时候,说明这个节点的所有左子树,都不满足要求
TreeNode* node = root->right;
delete root;
return node;
}
if(root->val>high){
//节点右子树全部不满足,返回左子树
TreeNode* node = root->left;
delete root;
return node;
}
root->left = trimBST(root->left,low,high);
root->right = trimBST(root->right,low,high);
return root;
}
};
debug测试
我们在debug的过程中先不释放内存,不用delete语句,先调通逻辑
逻辑错误:
这种写法,输入[3,1,4,null,2]二叉树,范围是[3,4]的时候,出现了输出错误。

原始树:
3
/ \
1 4
\
2
当low为3,high为4时,需要删除值为1的节点。这种写法将1替换为了它的右子节点2,但是2也并不在范围[low, high]之内。这就是为什么我们看到2仍然在结果中。
所以,当节点1不满足要求的时候,我们不能直接返回1的右孩子,因为1的右孩子2也可能不满足要求!
我们需要在发现不满足要求的时候进行递归,也就是TreeNode* right = trimBST(root->right,low,high);return right;,用返回的符合条件的right进行继位。(right也可能为空但是空继位是对的)
应修改为:
class Solution {
public:
TreeNode* trimBST(TreeNode* root, int low, int high) {
if(root==nullptr){
return nullptr;
}
//如果root不满足条件,需要一直递归,直到找到满足条件的来继位为止
if(root->val<low){
TreeNode* right = trimBST(root->right, low, high);
delete root; // 删除节点
return right; // 返回修剪后的子树
}
if(root->val>high){
TreeNode* left = trimBST(root->left, low, high);
delete root; // 删除节点
return left; // 返回修剪后的子树
}
//如果root满足条件,那么继续向下遍历
root->left = trimBST(root->left,low,high);
root->right = trimBST(root->right,low,high);
return root;
}
};
需要两次递归的原因
核心原因以及和删除节点操作的最大区别就是,当root(也就是正在遍历的节点)不符合要求的时候,我们不能像 450.删除节点 那样,直接把右孩子继位,顶上root的位置,因为右孩子也可能不符合条件!
因此我们必须进行内部的递归操作,直到找到一个符合要求的右孩子/左孩子,才能进行继位操作。
两次递归的详细解释:
TreeNode* node = root->right; return trimBST(node, low, high);这一段是在处理当前节点(即root节点)不在指定范围内,并需要被删除时的情况。在删除节点后,需要对删除节点后的右子树(或者左子树)进行修剪,确保返回的子树也满足条件。注意这里是对删除节点后的子树进行修剪。root->right = trimBST(root->right,low,high);这一段是在处理当前节点在指定范围内,不需要被删除,但是其子节点可能需要被删除的情况。因此,需要对当前节点的右子树(和左子树)进行修剪,确保它们也满足条件。注意这里是对当前节点的子树进行修剪。
尽管这两个操作看起来很相似,但是它们在操作的对象和目的上是有区别的。第一个是为了处理需要删除的节点,并确保删除后的子树满足条件;第二个是为了处理不需要删除的节点,但是需要确保其子节点满足条件。
内存操作报错:操作了已经被删除的内存的指针(力扣平台delete操作的问题,放IDE里就好了)
这种写法虽然逻辑正确,但是内存依然会报错
- 这里的delete结束之后直接return结束当前层的递归,所以是不会有内存问题的
- 走到root->left那一句的话,前面是没有delete root的
class Solution {
public:
TreeNode* trimBST(TreeNode* root, int low, int high) {
if(root==nullptr){
return nullptr;
}
//如果root不满足条件,需要一直递归,直到找到满足条件的来继位为止
if(root->val<low){
TreeNode* right = trimBST(root->right, low, high);
delete root; // 删除节点
return right; // 返回修剪后的子树
}
if(root->val>high){
TreeNode* left = trimBST(root->left, low, high);
delete root; // 删除节点
return left; // 返回修剪后的子树
}
//如果root满足条件,那么继续向下遍历
root->left = trimBST(root->left,low,high);
root->right = trimBST(root->right,low,high);
return root;
}
};
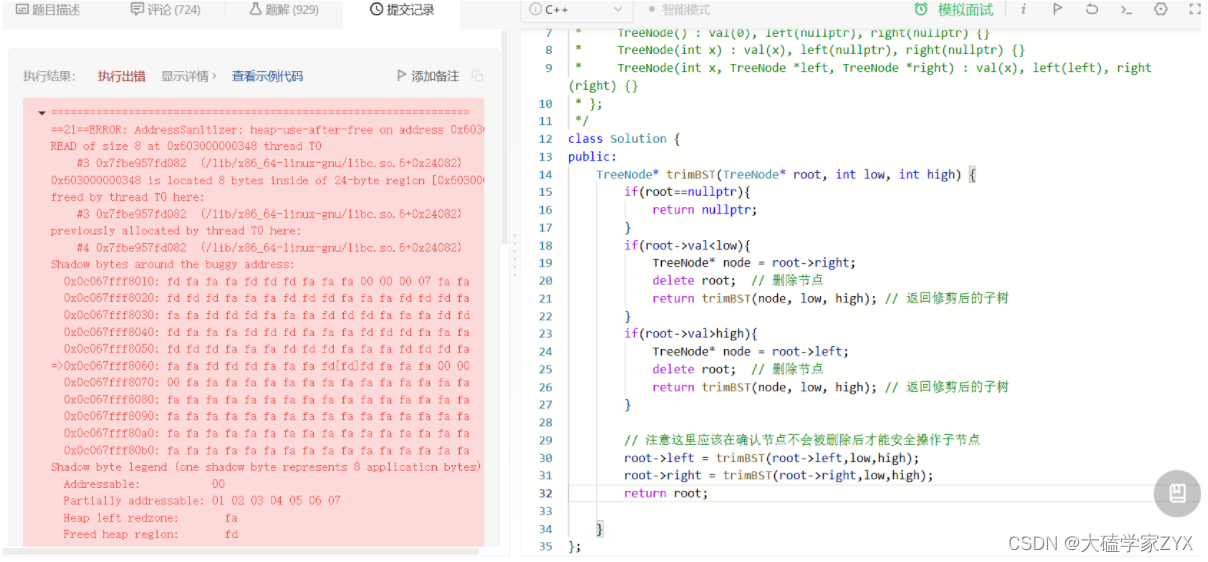
但是,将报错用例在IDE里跑了一下,并没有内存问题。(报错用例就是力扣里面显示的最后执行的输入)
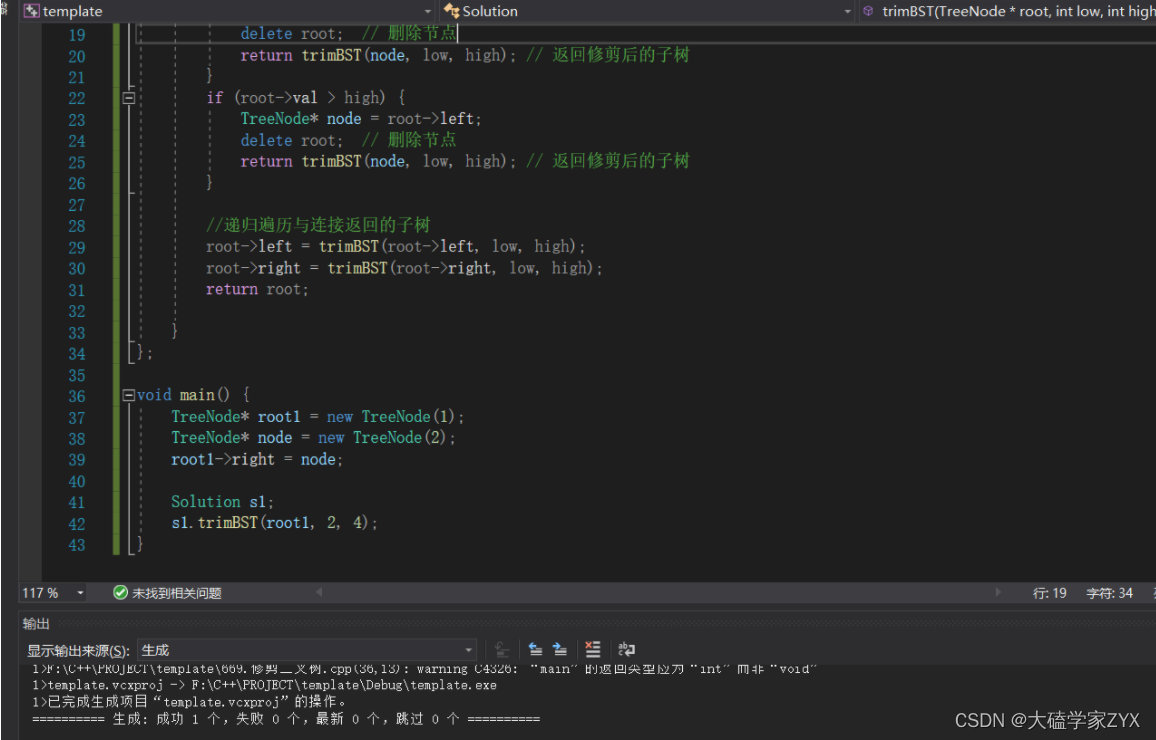
是力扣平台的问题,很坑,delete在IDE里面是正常的,并不会出现内存报错。
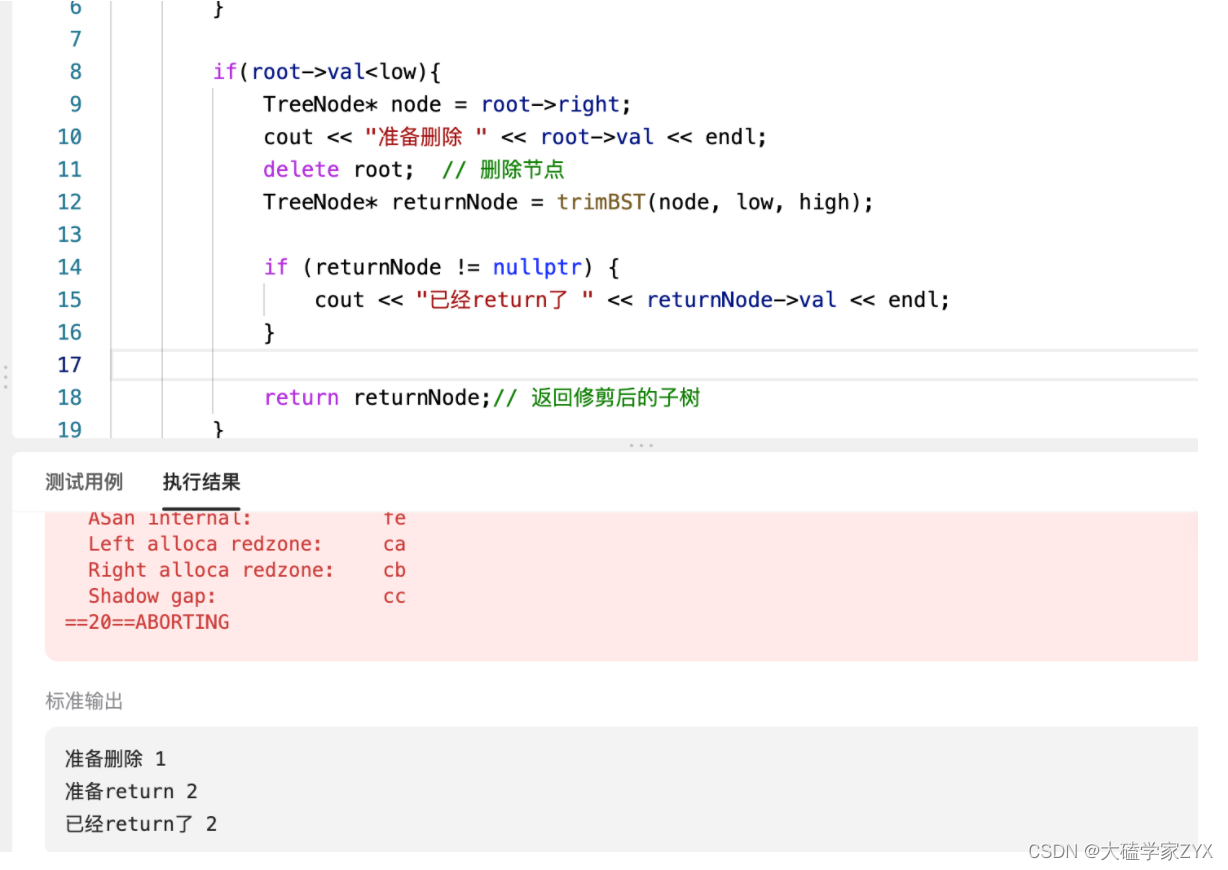
重新看了那个报错用例打了日志看也是也报错,应该判题程序会去调用原来的 root,但是程序把原来的 root 已经删了。这个问题就是平台的问题,但是我们要注意打日志debug的方法。
打日志debug示例
class Solution {
public:
TreeNode* trimBST(TreeNode* root, int low, int high) {
printf("又循环了一次");
if(root==nullptr){
return nullptr;
}
printf("一");
printf("%d",root->val);
if(root->val<low){
TreeNode* node = root->right;
printf("zheli");
printf("...................");
printf("%d",root->val);
delete root; // 删除节点
printf("nali");
return trimBST(node, low, high); // 返回修剪后的子树
}
printf("二");
printf("///");
printf("%d",root->val);
if(root->val>high){
TreeNode* node = root->left;
printf("++++++++++++++++++++++++");
printf("%d",root->val);
delete root; // 删除节点
return trimBST(node, low, high); // 返回修剪后的子树
}
printf("三");
//递归遍历与连接返回的子树
root->left = trimBST(root->left,low,high);
root->right = trimBST(root->right,low,high);
printf("四");
printf("***********************%d",root->val);
return root;
}
};
力扣平台delete问题的应对方案
一般不 delete 也是没问题的,但是就怕有些题数据量一大你不手动回收的话会内存泄露,毕竟不像 Java 那样可以自动 gc。
关于delete的问题,我的建议如果确定删是没问题的,可以删一下,这也是良好的编码习惯,实际开发不可能一直不回收。
这里主要是力扣自己的问题,遇到这道题可以长个心眼,之前还真没遇过。或者先写 delete 版本,出问题可以暂时把 delete 语句注释掉看看,反之也可以。
完整版
class Solution {
public:
TreeNode* trimBST(TreeNode* root, int low, int high) {
if(root==nullptr){
return nullptr;
}
//如果root不满足条件,需要一直递归,直到找到满足条件的来继位为止
if(root->val<low){
TreeNode* right = trimBST(root->right, low, high);
delete root; // 删除节点
return right; // 返回修剪后的子树
}
if(root->val>high){
TreeNode* left = trimBST(root->left, low, high);
delete root; // 删除节点
return left; // 返回修剪后的子树
}
//如果root满足条件,那么继续向下遍历
root->left = trimBST(root->left,low,high);
root->right = trimBST(root->right,low,high);
return root;
}
};
108.将有序数组转换为二叉搜索树(递归参数引用or值传递)
- 注意数组构建二叉树的方法,最好是不要创建新的空间,直接用数组下标操作
- 每个区间都取中点做根节点,然后一直递归下去
- 构造二叉树很多都是单独写函数,为了传入数组下标left和right
- 本题要注意递归参数的引用传递和值传递的问题
给你一个整数数组 nums ,其中元素已经按 升序 排列,请你将其转换为一棵 高度平衡 二叉搜索树。
高度平衡 二叉树是一棵满足「每个节点的左右两个子树的高度差的绝对值不超过 1 」的二叉树。
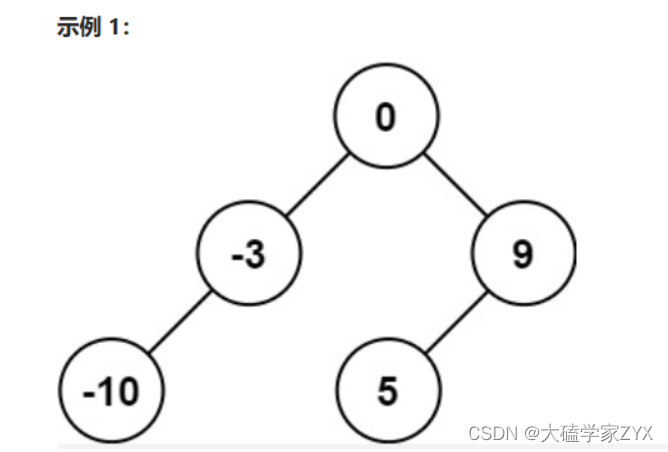
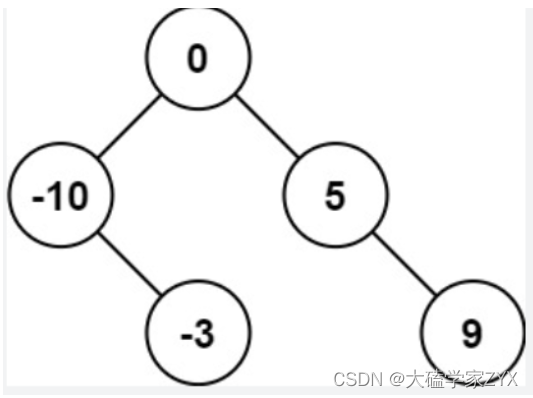
输入:nums = [-10,-3,0,5,9]
输出:[0,-3,9,-10,null,5]
解释:[0,-10,5,null,-3,null,9] 也将被视为正确答案:
输入:nums = [1,3]
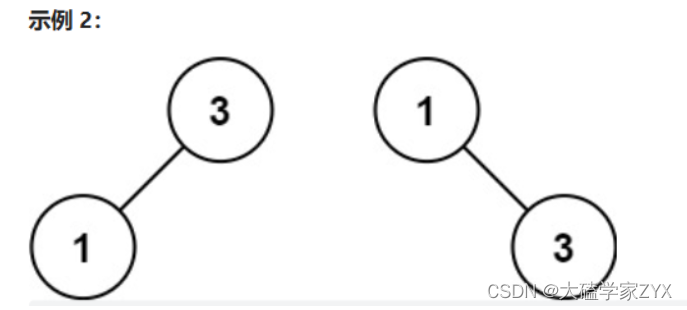
输出:[3,1]
解释:[1,null,3] 和 [3,1] 都是高度平衡二叉搜索树。
提示:
1 <= nums.length <= 10^4-10^4 <= nums[i] <= 10^4nums按 严格递增 顺序排列
思路
本题也属于构造二叉树类的题目,构造二叉树一定是前序遍历。
本题和 106.中序后序遍历构造二叉树 654.最大二叉树 比较像,都是构造类型的。
本题一个重要的点就是需要构造的二叉树是高度平衡二叉树,也就是说左右两边的高度差绝对值不能大于1。
这种情况下,因为是有序数组,所以我们取有序数组中间的点作为根节点,就能保证左右两边高度差<=1。
-
奇数长度:取中间节点
-
偶数长度:取中间靠左和靠右都可以
本质就是寻找分割点,分割点作为当前节点,然后递归左区间和右区间。
我们使用递归函数的返回值来构造中节点的左右孩子,
完整版
- c++中递归,很多情况下参数要用引用&,如果不用引用的话,每次递归都会复制内存空间,会导致性能很差。
- 区间定义很重要,最大二叉树那道题也涉及到区间定义。
- 递归构造每一次都是构造区间的中点,因此区间定义的时候传入参数一定要传入left和right,也就是数组的左右下标
class Solution {
public:
因为需要构造数组的左区间和右区间,所以单独写一个函数
TreeNode* travelsal(vector<int>& nums,int left,int right){
if(left>right){
return nullptr;
}
int mid = (left+right)/2;//数组下标不用考虑越界问题,提示里说了是10^4数量级
//根节点
TreeNode* root = new TreeNode(nums[mid]);
//递归构造左子树,每一次都是构造区间的中点
root->left = travelsal(nums,left,mid-1);
root->right = travelsal(nums,mid+1,right);
return root;
}
TreeNode* sortedArrayToBST(vector<int>& nums) {
//因为需要构造数组的左区间和右区间,注意左闭右开
return travelsal(nums,0,nums.size()-1);
}
};
递归参数的引用传递和值传递
递归的参数并不是一直都是引用传递的。是否使用引用传递在递归中主要取决于是否希望保持在递归过程中对参数的修改。
在一些情况下,我们可能希望每一层递归都有其独立的参数副本(例如前序遍历中的depth),在这种情况下应该使用值传递。
在其他情况下,我们可能希望在递归过程中共享同一个参数实例(例如本题构建BST二叉树中的nums),防止多次复制,在这种情况下应该使用引用传递。
必须使用引用传递的例子:
654.最大二叉树 106.中序和后序构造二叉树
- 基于数组构造二叉树类的题目,并不是因为需要不断地切割数组,所以数组必须是引用传递。我们只需要传递两个整数来表示数组的子区间。然后在递归调用中,我们只操作这两个整数,并不会改变原始数组!
- 基于数组构建树,使用引用传递是因为我们不希望在每次递归调用中复制整个数组,这将导致额外的内存和时间消耗。通过传递数组的引用,我们可以避免这种复制
class Solution {
public:
TreeNode* constructMaximumBinaryTree(vector<int>& nums) {
//终止条件:数组内没有没遍历到的元素了,也就是切出来的左区间和右区间都是NULL
//条件是if(nums.empty())的话,就不需要判断left和right是不是空的,是否存在操作空数组的问题了。
if(nums.empty()){
return nullptr; //返回空指针
}
//找最大值及其下标
int maxValue=INT_MIN;
int index;
int maxIndex;
for(index=0;index<nums.size();index++){
if(nums[index]>maxValue){
maxValue = nums[index];//最大值
maxIndex = index;//最大值的下标
}
}
//找到最大值之后,根节点数值确定
TreeNode* root = new TreeNode(maxValue);
//nums.erase(nums[maxIndex]);
//分割数组
//左数组,左闭右开
vector<int>left = vector<int>(nums.begin(),nums.begin()+maxIndex);
//分割数组后进行左右子树的递归
//这种写法不需要判断是不是操作空数组left,因为终止条件会判定
root->left = constructMaximumBinaryTree(left);
//右数组,左闭右开
vector<int>right = vector<int>(nums.begin()+maxIndex+1,nums.end());
root->right = constructMaximumBinaryTree(right);
return root;
}
};
必须使用值传递的例子:
104.二叉树的最大深度 前序遍历写法
- 涉及到前序遍历求深度的问题,由于遍历完了之后每层的depth必须要保持不变才能正确求解深度,因此这类每层深度需要不变的题目,必须用值传递。我们需要在每次递归调用中独立地更新
depth,每次递归调用中,depth的增加并不会影响到其他的递归调用。
class solution {
public:
int result;
//这里的depth必须要用值传递
void getdepth(treenode* node, int depth) {
result = depth > result ? depth : result; // 中
if (node->left == NULL && node->right == NULL) return ;
if (node->left) { // 左
getdepth(node->left, depth + 1);
}
if (node->right) { // 右
getdepth(node->right, depth + 1);
}
return ;
}
int maxdepth(treenode* root) {
result = 0;
if (root == 0) return result;
getdepth(root, 1);
return result;
}
};
是否使用值传递还是引用传递,主要取决于是否希望在递归过程中保持参数的修改。如果希望在每次递归调用中都有独立的参数(例如前序遍历求深度),那么就使用值传递。如果希望在递归过程中共享同一个参数实例(例如基于数组构造二叉树),那么就使用引用传递。
但注意,这个决定也需要考虑到复制参数的代价,特别是当参数是大型数据结构时。
如果nums使用了值传递,会增加多少开销?
值传递会在每次函数调用时复制整个参数,所以如果参数是一个大型数据结构(例如一个包含n个元素的数组或向量),这会导致很大的开销。
从时间复杂度的角度来看,每次复制一个包含n个元素的数组的时间复杂度是O(n),如果有递归深度为d的递归函数,那么总的时间复杂度至少会是O(n*d),这显然比直接操作原始数据的O(n)要高得多。
从空间复杂度的角度来看,每次函数调用都会在栈上创建一个新的数组副本,所以如果你有递归深度为d的递归函数,那么总的空间复杂度至少会是O(n*d)。这显然比直接操作原始数据的O(n)或者O(log n)(对于平衡二叉树的递归深度,但本题空间复杂度仍是O(n))要高得多。
538.把二叉搜索树转换为累加树(思路注意)
- 注意: 中序遍历倒过来, 右中左遍历, 得到的就是单调递减数组了. 这种思路一定要注意
- 本题涉及到我们对遍历的理解, 遍历就是按照我们定义的顺序对二叉树所有节点进行的筛选, 右中左的反向中序遍历, 走到中的时候已经确保遍历过的元素都是右侧(也就是比它大)的节点了!
给出二叉 搜索 树的根节点,该树的节点值各不相同,请你将其转换为累加树(Greater Sum Tree),使每个节点 node 的新值等于原树中大于或等于 node.val 的值之和。
提醒一下,二叉搜索树满足下列约束条件:
节点的左子树仅包含键 小于 节点键的节点。
节点的右子树仅包含键 大于 节点键的节点。
左右子树也必须是二叉搜索树。
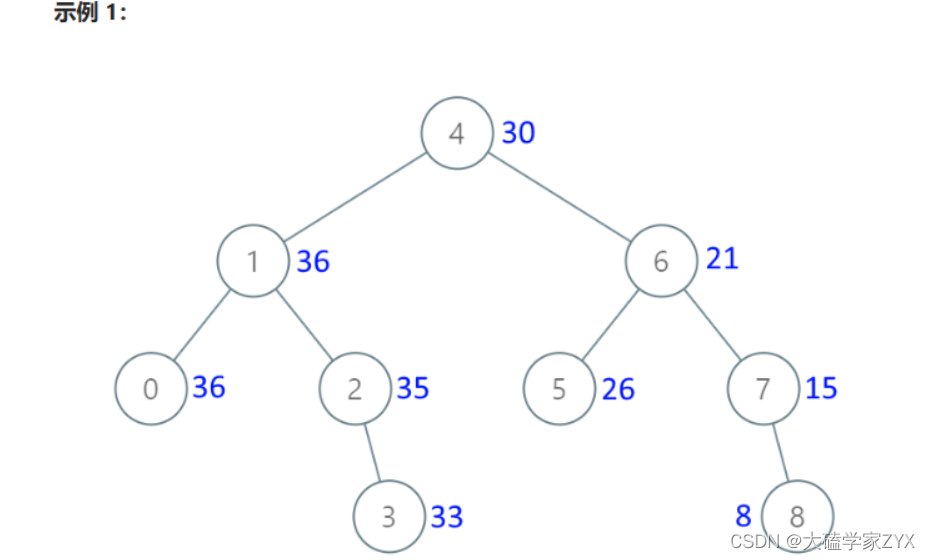
输入:[4,1,6,0,2,5,7,null,null,null,3,null,null,null,8]
输出:[30,36,21,36,35,26,15,null,null,null,33,null,null,null,8]
示例 2:
输入:root = [0,null,1]
输出:[1,null,1]
示例 3:
输入:root = [1,0,2]
输出:[3,3,2]
示例 4:
输入:root = [3,2,4,1]
输出:[7,9,4,10]
提示:
- 树中的节点数介于 0 和 10^4 之间。
- 每个节点的值介于 -10^4 和 10^4 之间。
- 树中的所有值 互不相同 。
- 给定的树为二叉搜索树。
思路
累加树相加,一定要注意还要加上本身.
本题思路可能考虑比较复杂, 我们可以先当成累加数组来做.
例如, 一个有序的递增数组[2,5,6], 想要得到所有>=当前值的累加结果,只需要做倒序遍历即可,因为数组本身就是有序的! 所以所有>=当前值的数字,一定在当前值的后面.
本题的核心点也是因为BST, 中序的左中右会得到递增数组. 我们现在需要对递增数组进行倒序遍历, 以将>=val值的数据都累加起来.
中序左中右得到递增,那么把中序倒过来,右中左就会得到递减!
我们可以举个例子来遍历一下, 例如下面的二叉树:
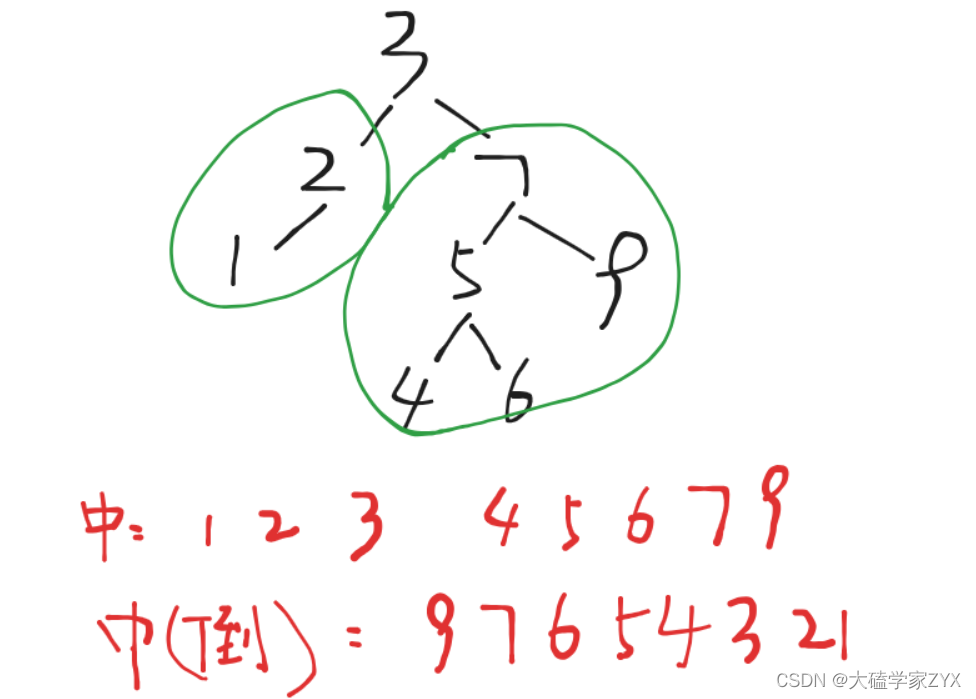
可以看出,中序得到单调递增序列, 但是把中序倒过来, 改为右中左, 就能得到单调递减序列.
也就是说, 本题是累计所有节点值>=val值的和, 只需要倒过来中序的遍历顺序得到递减, 再进行节点值累加就可以了.因为倒过来的话所有>=val值的, 都在之前遍历过了.
最开始的写法
- 遍历顺序是倒过来的中序遍历, 右中左, 再累加数值
- 本质就是累加所有遍历过的数值
class Solution {
public:
TreeNode* convertBST(TreeNode* root) {
if(root==nullptr){
return nullptr;
}
//倒着的中序遍历
//右
TreeNode* right = convertBST(root->right);
//连接右
root->right = right;
//中
root->val = right->val+root->val;
//左
TreeNode* left = convertBST(root->left);
//连接左
root->left = left;
return root;
}
};
debug测试
空指针访问出错
Line 24: Char 28: runtime error: member access within null pointer of type ‘TreeNode’ (solution.cpp)
这个错误是因为在尝试访问一个空指针的成员,在right->val这一行对right这个指针进行了解引用操作。但是,如果right是一个空指针(也就是nullptr),这就会导致错误。
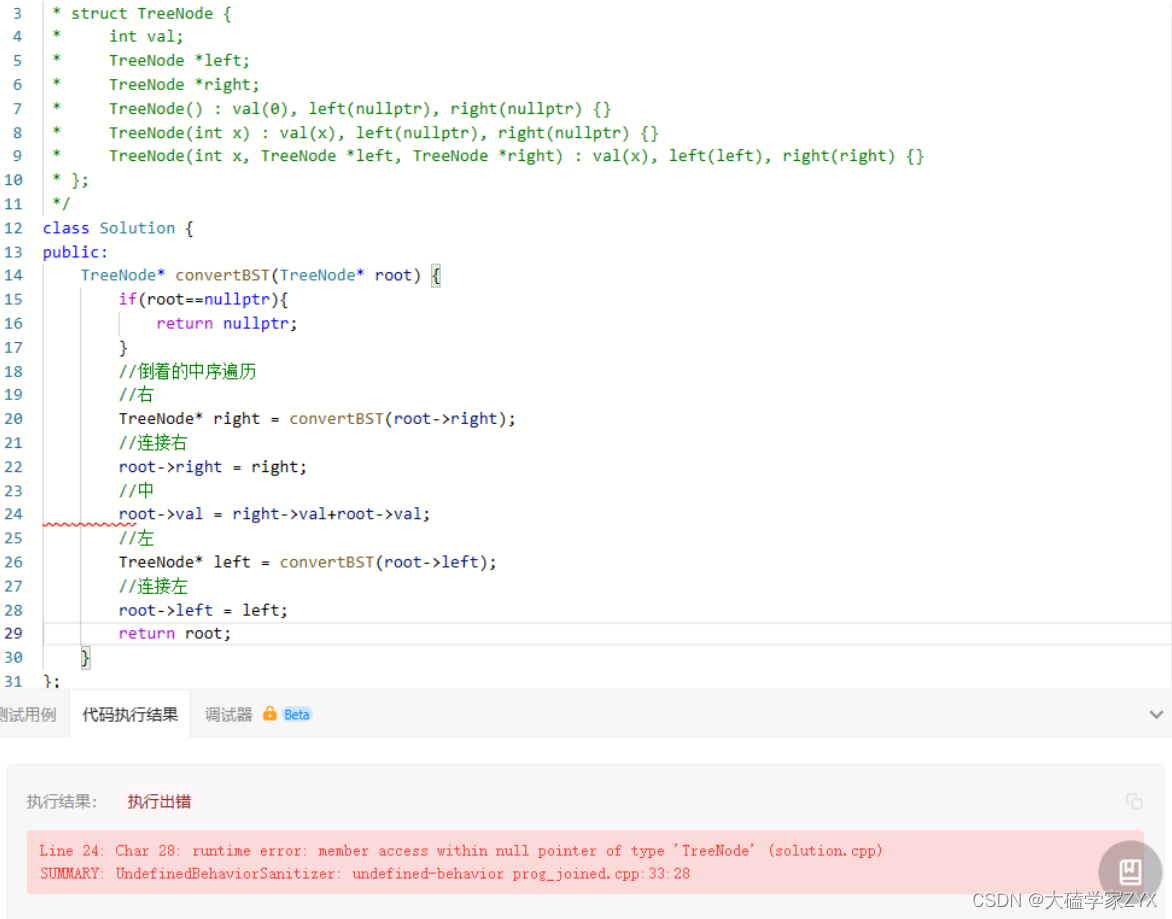
修改为:
class Solution {
public:
TreeNode* convertBST(TreeNode* root) {
if(root==nullptr){
return nullptr;
}
//倒着的中序遍历
//右
TreeNode* right = convertBST(root->right);
//连接右
root->right = right;
//中
if(right!=nullptr){
root->val = right->val+root->val;
}
//左
TreeNode* left = convertBST(root->left);
//连接左
root->left = left;
return root;
}
};
逻辑错误
画一下就会发现是因为没累加左子树, 中这里的处理逻辑应该是累加当前遍历过的所有root的值, 因为遍历顺序已经是右中左了! 不需要单独累加右了!
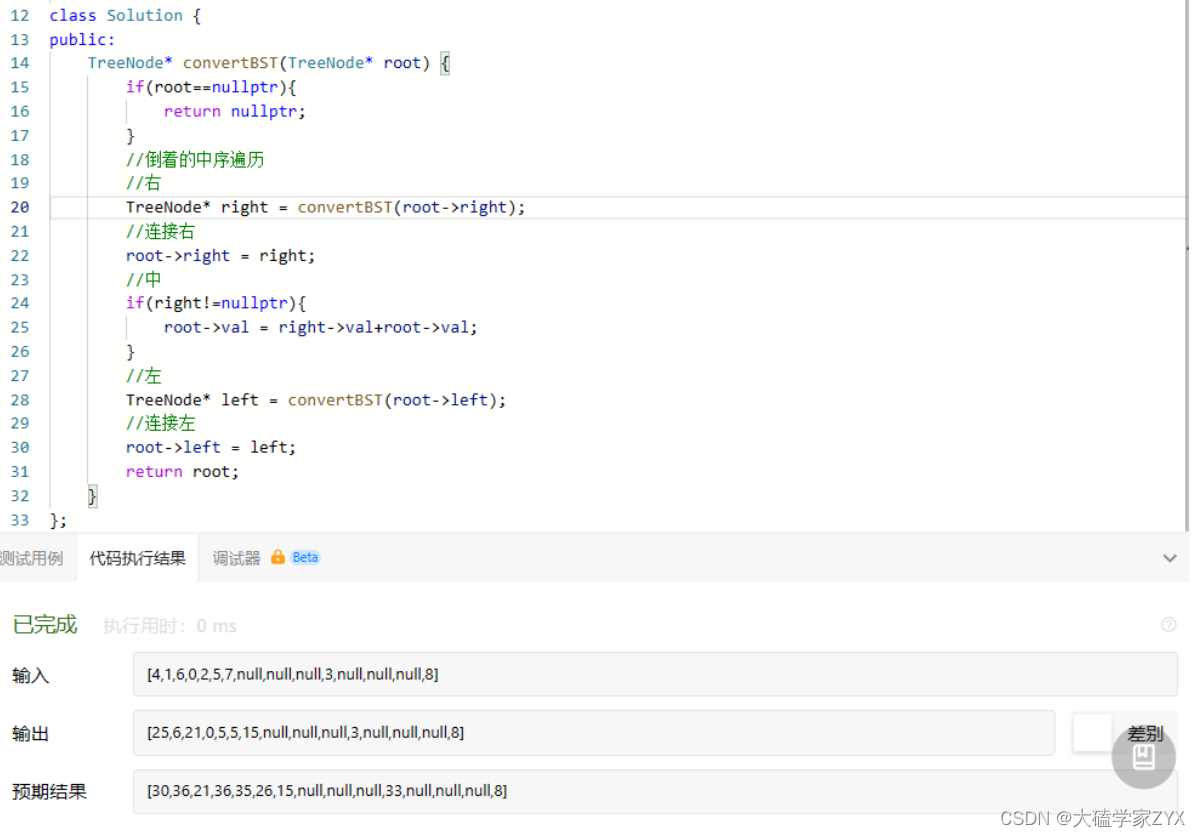
这是一个比较重要的逻辑错误, 遍历的时候已经遵循右中左原则, 那么遍历累加的时候就必须要累加目前为止遍历过的所有元素.
修改后的完整版
- 我们需要注意一点, 当前的遍历顺序已经是倒着的中序遍历了! 因此我们在处理中的逻辑的时候, 并不需要只加右子树, 而是必须要把所有的节点值都加上, 因为右子树也有左节点!
- 设置全局变量的原因
class Solution {
public:
int sum = 0;
TreeNode* convertBST(TreeNode* root) {
if(root==nullptr){
return nullptr;
}
//倒着的中序遍历
//右
TreeNode* right = convertBST(root->right);
//连接右
root->right = right;
//中,累加
sum += root->val;
root->val = sum;
//左
TreeNode* left = convertBST(root->left);
//连接左
root->left = left;
return root;
}
};
必须定义全局变量的原因
定义一个全局变量sum用来累加目前为止遍历过的所有节点的值,而不是仅仅累加右子树的值,是因为在遍历的过程中,我们需要累加的是所有比当前节点值大的节点的值,而不仅仅是右子节点的值。
遍历的进一步理解
遍历的本质,是会按照规定的顺序对二叉树进行遍历. 因为本题规定的顺序是右中左,所以二叉树就会按照右子树-根节点-左子树顺序进行遍历.
因此, 我们在遍历的时候就已经规定了,当前节点之前遍历过的节点,全部都是元素值比它大的节点,所以必须使用累加的方式,存储在这之前遍历过的所有元素的值。因为在这之前遍历过的所有元素, 都符合比当前元素值要大的这一点! 右中左的反向中序遍历已经是在只筛选右侧的节点了.
一些补充
"遍历"二叉树是按照某种特定顺序访问树中所有节点的过程。
在二叉搜索树中,所有右子节点的值都大于根节点,而所有左子节点的值都小于根节点。因此,当按照右-中-左的顺序遍历时,会先访问所有比当前节点大的节点(在右子树),然后是当前节点,最后才是所有比当前节点小的节点(在左子树)。所以,当走到"中"的时候,已经遍历过所有在右侧(也就是值比当前节点大)的节点。
因此,通过这种方式遍历,我们已经可以确保在访问每个节点时,在这之前访问的都是比它大的节点的值。这就是为什么我们可以用这种方式来将二叉搜索树转化为“累加树”。