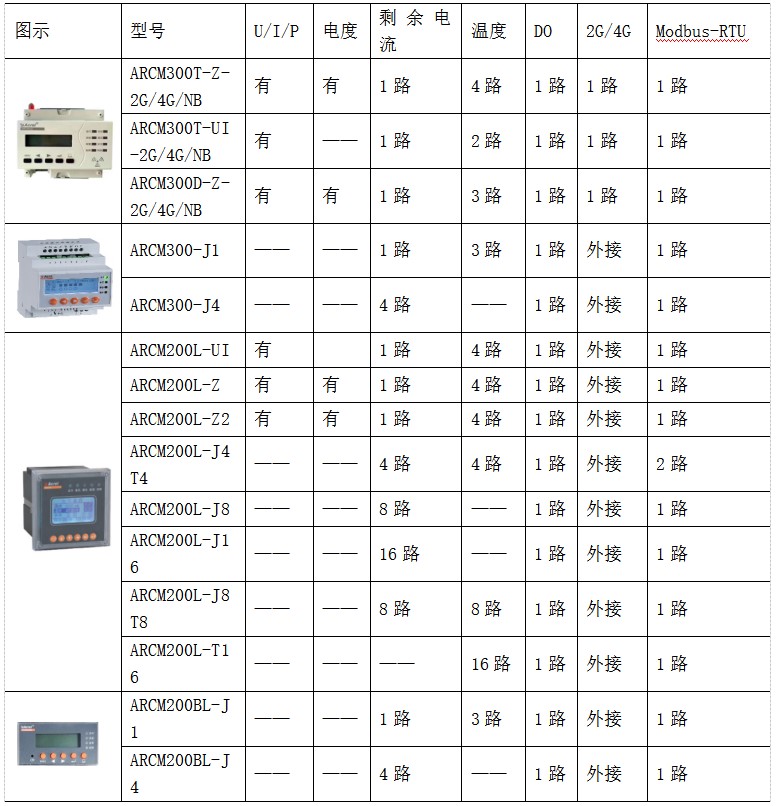
当有人问你如何对数据库进行优化时,很多人第一反应想到的就是SQL优化,如何创建索引,如何改写SQL,他们把数据库优化与SQL优化划上了等号。
当然这不能算是完全错误的回答,只不过思考的角度稍微片面了些,太“程序员思维”化了,没有站在更高层次来思考回答。那今天我们就将视角拔高,站在架构的角度来聊聊这一问题,数据库优化可以从哪些维度入手?

正如上图所示,数据库优化可以从架构优化,硬件优化,DB优化,SQL优化四个维度入手。
此上而下,位置越靠前优化越明显,对数据库的性能提升越高。我们常说的SQL优化反而是对性能提高最小的优化。
接下来我们再看看每种优化该如何实施。
一、架构优化
一般来说在高并发的场景下对架构层进行优化其效果最为明显,常见的优化手段有:分布式缓存,读写分离,分库分表等,每种优化手段又适用于不同的应用场景。
1.1 分布式缓存
有句老话说的好,性能不够,缓存来凑。当需要在架构层进行优化时我们第一时间就会想到缓存这个神器,在应用与数据库之间增加一个缓存服务,如Redis或Memcache。

当接收到查询请求后,我们先查询缓存,判断缓存中是否有数据,有数据就直接返回给应用,如若没有再查询数据库,并加载到缓存中,这样就大大减少了对数据库的访问次数,自然而然也提高了数据库性能。
不过需要注意的是,引入分布式缓存后系统需要考虑如何应对缓存穿透、缓存击穿和缓存雪崩的问题。
“简单理解一下 缓存穿透、缓存击穿 和 缓存雪崩
缓存穿透:它是指当用户在查询一条数据的时候,而此时数据库和缓存都没有关于这条数据的任何记录。这条数据在缓存中没找到就会向数据库请求获取数据。它拿不到数据时,是会一直查询数据库,这样会对数据库的访问造成很大的压力。
缓存击穿:一个热点key刚好在某个时间点失效了,但是这时候突然来了大量对这个key的并发访问请求,导致大并发请求直接穿透缓存直达数据库,瞬间对数据库的访问压力增大。
缓存雪崩:某一个时间段内,缓存集中过期失效,如果这个时间段内有大量请求,而查询数据量巨大,所有的请求都会达到存储层,存储层的调用量会暴增,引起数据库压力过大甚至宕机。
”
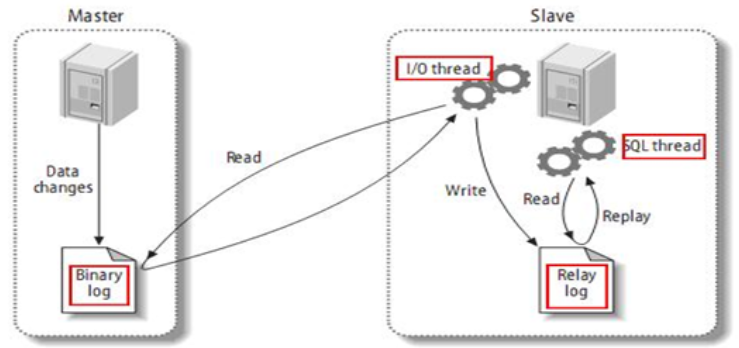
1.2 读写分离
一主多从,读写分离,主动同步,是一种常见的数据库架构优化手段。
一般来说当你的应用是读多写少,数据库扛不住读压力的时候,采用读写分离,通过增加从库数量可以线性提升系统读性能。

主库,提供数据库写服务;从库,提供数据库读能力;主从之间,通过binlog同步数据。
当准备实施读写分离时,为了保证高可用,需要实现故障的自动转移,主从架构会有潜在主从不一致性问题。
1.3 水平切分
水平切分,也是一种常见的数据库架构优化手段。
当你的应用业务数据量很大,单库容量成为性能瓶颈后,采用水平切分,可以降低数据库单库容量,提升数据库写性能。

当准备实施水平切分时,需要结合实际业务选取合理的分片键(sharding-key),有时候为了解决非分片键查询问题还需要将数据写到单独的查询组件,如ElasticSearch。
架构优化小结
-
读写分离主要是用于解决 “数据库读性能问题”
-
水平切分主要是用于解决“数据库数据量大的问题”
-
分布式缓存架构可能比读写分离更适用于高并发、大数据量大场景。
二、硬件优化
我们使用数据库,不管是读操作还是写操作,最终都是要访问磁盘,所以说磁盘的性能决定了数据库的性能。一块PCIE固态硬盘的性能是普通机械硬盘的几十倍不止。这里我们可以从吞吐率、IOPS两个维度看一下机械硬盘、普通固态硬盘、PCIE固态硬盘之间的性能指标。
吞吐率:单位时间内读写的数据量
-
机械硬盘:约100MB/s ~ 200MB/s
-
普通固态硬盘:200MB/s ~ 500MB/s
-
PCIE固态硬盘:900MB/s ~ 3GB/s
IOPS:每秒IO操作的次数
-
机械硬盘:100 ~200
-
普通固态硬盘:30000 ~ 50000
-
PCIE固态硬盘:数十万
通过上面的数据可以很直观的看到不同规格的硬盘之间的性能差距非常大,当然性能更好的硬盘价格会更贵,在资金充足并且迫切需要提升数据库性能时,尝试更换一下数据库的硬盘不失为一个非常好的举措,你之前遇到SQL执行缓慢问题在你更换硬盘后很可能将不再是问题。
三、DB优化
SQL执行慢有时候不一定完全是SQL问题,手动安装一台数据库而不做任何参数调整,再怎么优化SQL都无法让其性能最大化。要让一台数据库实例完全发挥其性能,首先我们就得先优化数据库的实例参数。
数据库实例参数优化遵循三句口诀:日志不能小、缓存足够大、连接要够用。
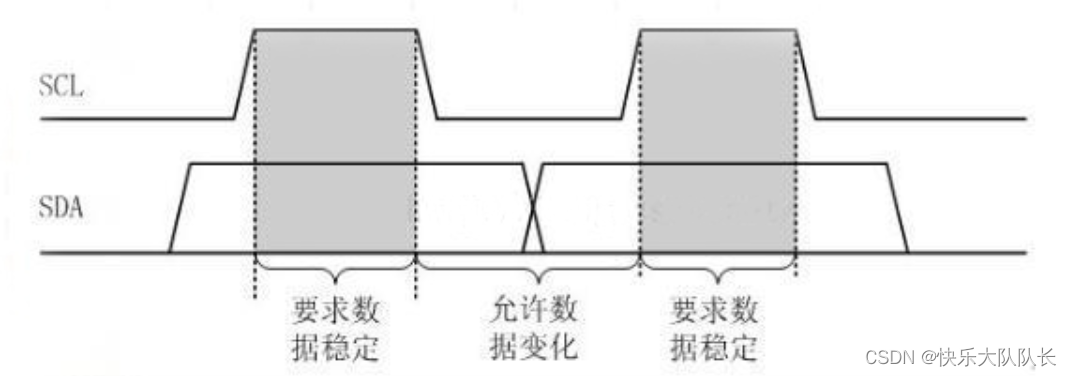
数据库事务提交后需要将事务对数据页的修改刷( fsync)到磁盘上,才能保证数据的持久性。这个刷盘,是一个随机写,性能较低,如果每次事务提交都要刷盘,会极大影响数据库的性能。数据库在架构设计中都会采用如下两个优化手法:
-
先将事务写到日志文件RedoLog(WAL),将随机写优化成顺序写
-
加一层缓存结构Buffer,将单次写优化成顺序写
所以日志跟缓存对数据库实例尤其重要。而连接如果不够用,数据库会直接抛出异常,系统无法访问。
接下来我们以Oracle、MySQL(InnoDB)、POSTGRES、达梦为例,看看每种数据库的参数该如何配置。
3.1 Oracle
| 参数分类 | 参数名 | 参数值 | 备注 |
|---|---|---|---|
| 数据缓存 | SGA_TAGET、MEMORY_TARGET | 物理内存70-80% | 越大越好 |
| 数据缓存 | DB_CACHE_SIZE | 物理内存70-80% | 越大越好 |
| SQL解析 | SHARED_POOL_SIZE | 4-16G | 不建议设置过大 |
| 监听及连接 | PROCESSES、SESSIONS、OPEN_CURSORS | 根据业务需求设置 | 一般为业务预估连接数的120% |
| 其他 | SESSION_CACHED_CURSORS | 大于200 | 软软解析 |
3.2 MySQL
| 参数分类 | 参数名 | 参数值 | 备注 |
|---|---|---|---|
| 数据缓存 | INNODB_BUFFER_POOL_SIZE | 物理内存50-80% | 一般来说越大性能越好 |
| 日志相关 | Innodb_log_buffer_size | 16-32M | 根据运行情况调整 |
| 日志相关 | sync_binlog | 1、100、0 | 1安全性最好 |
| 监听及连接 | max_connections | 根据业务情况调整 | 可以预留一部分值 |
| 文件读写性能 | innodb_flush_log_at_trx_commit | 2 | 安全和性能的折中考虑 |
| 其他 | wait_timeout,interactive_timeout | 28800 | 避免应用连接定时中断 |
3.3 POSTGRES
| 参数分类 | 参数名 | 参数值 | 备注 |
|---|---|---|---|
| 数据缓存 | SHARED_BUFFERS | 物理内存10-25% | |
| 数据缓存 | CACHE_BUFFER_SIZE | 物理内存50-60% | |
| 日志相关 | wal_buffer | 8-64M | 不建议设置过大过小 |
| 监听及连接 | max_connections | 根据业务情况调整 | 一般为业务预估连接数的120% |
| 其他 | maintenance_work_mem | 512M或更大 | |
| 其他 | work_mem | 8-16M | 原始配置1M过小 |
| 其他 | checkpoint_segments | 32或者更大 |
3.4 达梦数据库
| 参数分类 | 参数名 | 参数值 | 备注 |
|---|---|---|---|
| 数据缓存 | MEMROY_TARGET、MEMROY_POOL | 物理内存90% | |
| 数据缓存 | BUFFER | 物理内存60% | 数据缓存 |
| 数据缓存 | MAX_BUFFER | 物理内存70% | 最大数据缓存 |
| 监听及连接 | max_sessions | 根据业务需求设置 | 一般为业务预估连接数的120% |
四、SQL优化
SQL优化很容易理解,就是通过给查询字段添加索引或者改写SQL提高其执行效率,一般而言,SQL编写有以下几个通用的技巧:
-
合理使用索引
索引少了查询慢;索引多了占用空间大,执行增删改语句的时候需要动态维护索引,影响性能 选择率高(重复值少)且被where频繁引用需要建立B树索引;一般join列需要建立索引;复杂文档类型查询采用全文索引效率更好;索引的建立要在查询和DML性能之间取得平衡;复合索引创建时要注意基于非前导列查询的情况
-
使用UNION ALL替代UNION
UNION ALL的执行效率比UNION高,UNION执行时需要排重;UNION需要对数据进行排序
-
避免select * 写法
执行SQL时优化器需要将 * 转成具体的列;每次查询都要回表,不能走覆盖索引。
-
JOIN字段建议建立索引
一般JOIN字段都提前加上索引
-
避免复杂SQL语句
提升可阅读性;避免慢查询的概率;可以转换成多个短查询,用业务端处理
-
避免where 1=1写法
-
避免order by rand()类似写法
RAND()导致数据列被多次扫描
4.1 执行计划
要想优化SQL必须要会看执行计划,执行计划会告诉你哪些地方效率低,哪里可以需要优化。我们以MYSQL为例,来认识一下执行计划。
通过explain sql 可以查看执行计划,如:

| 字段 | 解释 |
|---|---|
| id | 每个被独立执行的操作标识,标识对象被操作的顺序,id值越大,先被执行,如果相同,执行顺序从上到下 |
| select_type | 查询中每个select 字句的类型 |
| table | 被操作的对象名称,通常是表名,但有其他格式 |
| partitions | 匹配的分区信息(对于非分区表值为NULL) |
| type | 连接操作的类型 |
| possible_keys | 可能用到的索引 |
| key | 优化器实际使用的索引(最重要的列) 从最好到最差的连接类型为const、eq_reg、ref、range、index和ALL。当出现ALL时表示当前SQL出现了“坏味道” |
| key_len | 被优化器选定的索引键长度,单位是字节 |
| ref | 表示本行被操作对象的参照对象,无参照对象为NULL |
| rows | 查询执行所扫描的元组个数(对于innodb,此值为估计值) |
| filtered | 条件表上数据被过滤的元组个数百分比 |
| extra | 执行计划的重要补充信息,当此列出现Using filesort , Using temporary 字样时就要小心了,很可能SQL语句需要优化 |
4.2 SQL优化实战
这里为大家准备了一套SQL优化的综合实战,一步一步带你走一遍完整SQL优化的过程。
在执行优化之前我们需要先认识一下原始表及待优化的SQL。
1.原数据库表结构
CREATE TABLE `a`
(
`id` int(11) NOT NULL AUTO_INCREMENT,
`seller_id` bigint(20) DEFAULT NULL,
`seller_name` varchar(100) CHARACTER SET utf8 COLLATE utf8_bin DEFAULT NULL,
`gmt_create` varchar(30) DEFAULT NULL,
PRIMARY KEY (`id`)
);
CREATE TABLE `b`
(
`id` int(11) NOT NULL AUTO_INCREMENT,
`seller_name` varchar(100) DEFAULT NULL,
`user_id` varchar(50) DEFAULT NULL,
`user_name` varchar(100) DEFAULT NULL,
`sales` bigint(20) DEFAULT NULL,
`gmt_create` varchar(30) DEFAULT NULL,
PRIMARY KEY (`id`)
);
CREATE TABLE `c`
(
`id` int(11) NOT NULL AUTO_INCREMENT,
`user_id` varchar(50) DEFAULT NULL,
`order_id` varchar(100) DEFAULT NULL,
`state` bigint(20) DEFAULT NULL,
`gmt_create` varchar(30) DEFAULT NULL,
PRIMARY KEY (`id`)
);
2.待优化的SQL(查询当前用户在当前时间前后10个小时的订单情况,并根据订单创建时间升序排列)
select a.seller_id,
a.seller_name,
b.user_name,
c.state
from a,
b,
c
where a.seller_name = b.seller_name
and b.user_id = c.user_id
and c.user_id = 17
and a.gmt_create
BETWEEN DATE_ADD(NOW(), INTERVAL – 600 MINUTE)
AND DATE_ADD(NOW(), INTERVAL 600 MINUTE)
order by a.gmt_create;
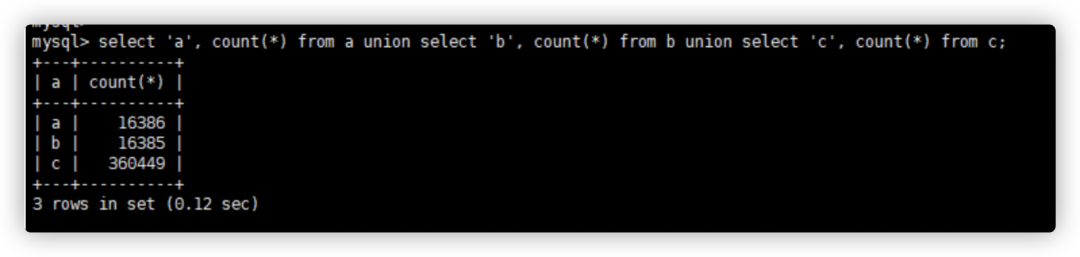
3.原表数据量:
4.原执行时间

0.21s,执行速度还挺快
5.原执行计划

真是糟糕的执行计划。(全表扫描,没有索引;临时表;排序)
初步优化思路:
-
SQL中 where条件字段类型要跟表结构一致,表中
user_id为varchar(50)类型,实际SQL用的int类型,存在隐式转换,也未添加索引。将b和c表user_id字段改成int类型。 -
因存在b表和c表关联,将b和c表
user_id创建索引 -
因存在a表和b表关联,将a和b表
seller_name字段创建索引 -
利用复合索引消除临时表和排序
初步优化SQL
alter table b modify `user_id` int(10) DEFAULT NULL;
alter table c modify `user_id` int(10) DEFAULT NULL;
alter table c add index `idx_user_id`(`user_id`);
alter table b add index `idx_user_id_sell_name`(`user_id`,`seller_name`);
alter table a add index `idx_sellname_gmt_sellid`(`gmt_create`,`seller_name`,`seller_id`);
查看优化后的执行时间

通过执行计划可以看到,执行时间从0.21s优化成了0.01s,执行时间近乎缩短20倍。
查看优化后的执行计划

执行计划显示从全表扫描优化成了走索引,rows减少,但是此时出现了2个告警。
通过show warning语句 查看告警信息

提示gmt_crteate 的格式不对,mysql进行了隐式转换导致不能使用索引。
继续优化,修改gmtc-create的格式
alter table a modify "gmt_create" datetime DEFAULT NULL;
再次查看执行时间

再次查看执行计划
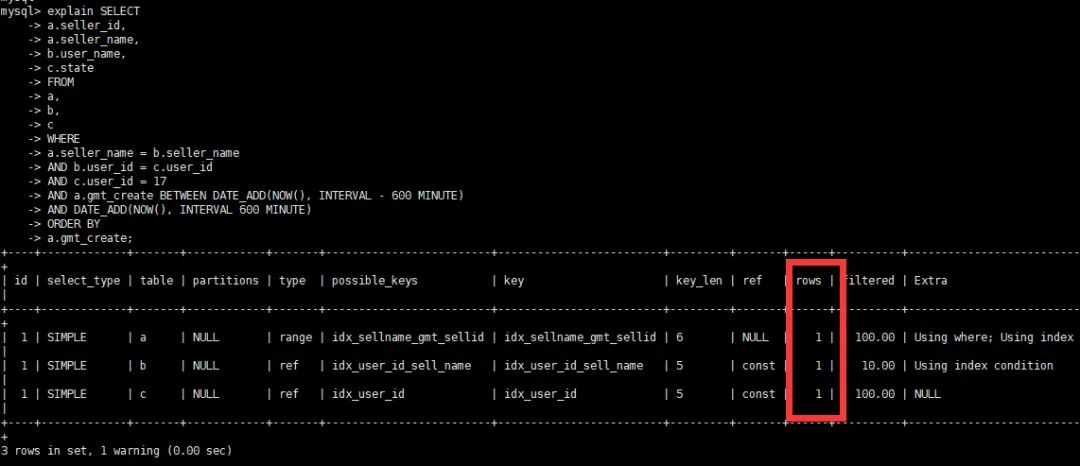
至此,我们的优化过程结束,结果非常完美。
SQL优化小结
这里给大家总结一下SQL优化的套路:
-
查看执行计划
explain sql -
如果有告警信息,查看告警信息
show warnings; -
查看SQL涉及的表结构和索引信息
-
根据执行计划,思考可能的优化点
-
按照可能的优化点执行表结构变更、增加索引、SQL改写等操作
-
查看优化后的执行时间和执行计划
-
如果优化效果不明显,重复第四步操作
五、小结
我们今天分别从架构优化、硬件优化、DB优化、SQL优化四个角度探讨了如何实施优化,提升数据库性能。但是大家还是要记住一句话,数据库系统没有银弹, 要让适合的系统,做合适的事情。