paper: CenterFusion: Center-based Radar and Camera Fusion for 3D Object Detection
code: https://github.com/mrnabati/CenterFusion
0 引言
自动驾驶的感知应用中, 通常会融合多模态传感器, 如lidar和camera的融合。 单纯基于radar做感知的研究工作很少, 用radar的场景一般都是和其他传感器进行一个融合。 本文要讲的CenterFusion就是一篇融合Camera和Radar的工作。
1 方法
整体的思路也比较简单,以camera的检测结果为主, 但是单目camera的深度不太准, 而radar不仅可以提供深度信息, 还有速度信息, 因此想要把radar的这些属性给有效利用上。
那怎么才能把radar的信息给有效利用起来呢?比较容易能够想到的思路是, 先把radar的点和图像中对应的目标给关联起来, 这样每个目标就有了对应的radar点, 那就可以得到深度, 速度这些信息了。
关联的时候其实会面临2个问题:
- 1 radar测量的点在 z z z维是很不准的, 甚至有时候没有 z z z的信息
- 2 图像和radar点不是一对一映射的关系, 有的目标可能有多个radr点
- 3 遮挡问题。多个radar点可能对应图像中的同一个目标。
那么论文核心的东西就是为了解决上面的3个问题:
为了解决问题1 , 提出了Pillar Expansion, 具体来说, 就是既然
z
z
z是不准的, 绝对的
z
z
z其实意义不大, 我们在
z
z
z上划分出一定高度的柱子, 这样对
z
z
z的容错性就大大提高了。
为了解决问题2和3, 提出来Frustum Association Mechanism, 基于图像有了2D的Bbox以及估计的深度, 那么Radar的点应该是落在相机中心到这个Bbox的椎体内的, 这样就可以找到目标对应的radar点了, 如果有多个radar点满足要求, 我们就取距离最近的一个就可以了。
得到目标匹配的radar点以后, 我们就提出目标的深度以及速度特征了, 把这些特征和原本基于图像提取的特征进行 一个concat操作,就完成radar特征和图像特征的融合了。
理解了基本的原理,再来看整体的网络结构就很清晰了:
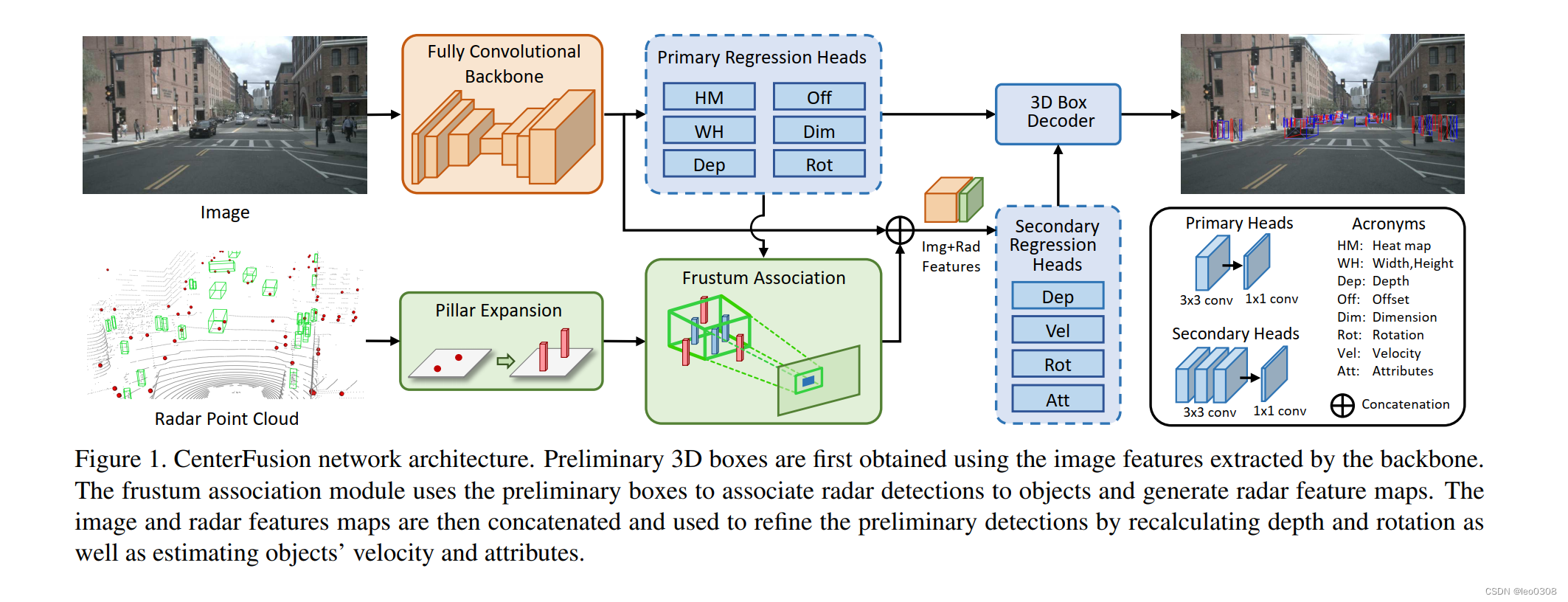
2 结果
首先是跟其他方法的一个对比, 包括基于单目图像的, 基于lidar的方法:

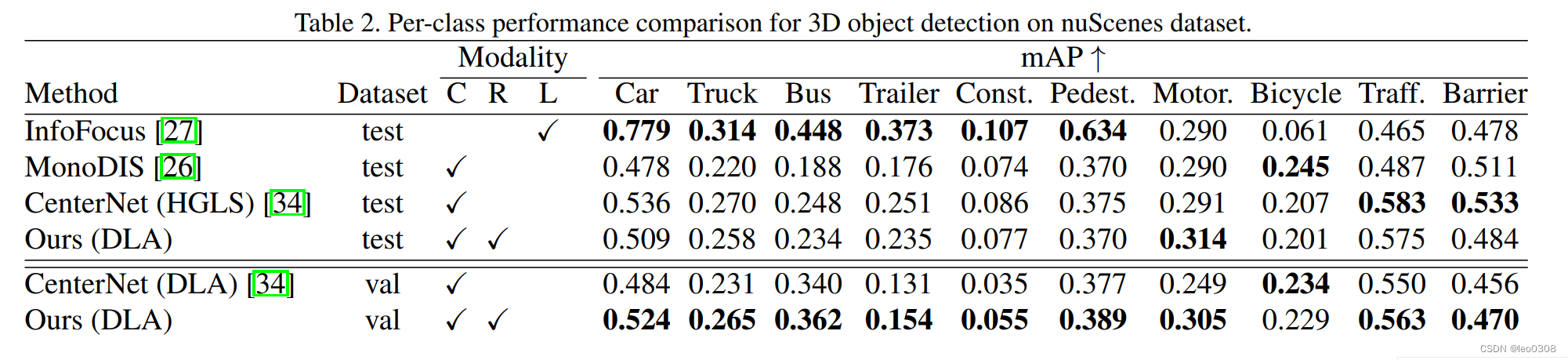
跟上面一样, 只是具体到每一个类别的对比:
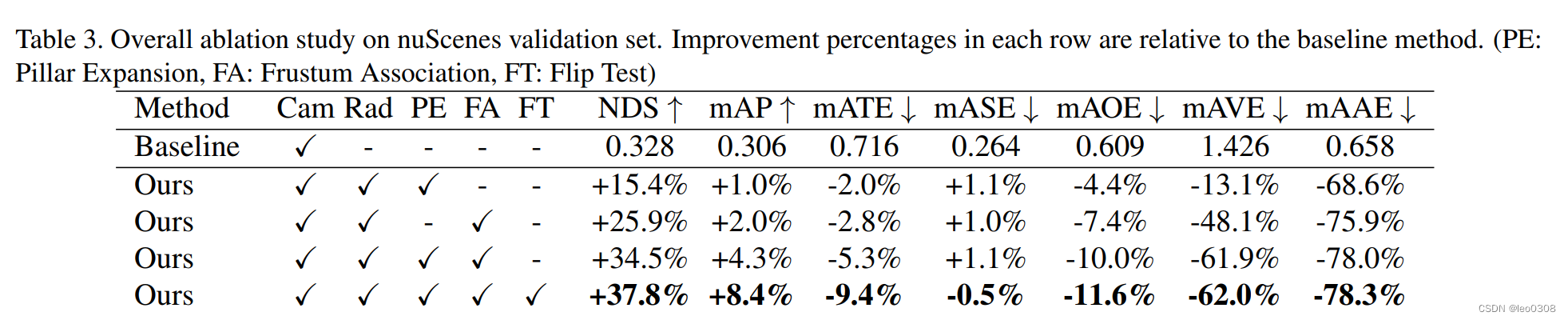
消融实验:
证明上面提到的两个模块的有效性,另外还加了FT,是数据增广的。
跟上面一样, 只是具体到每一个类别比较:

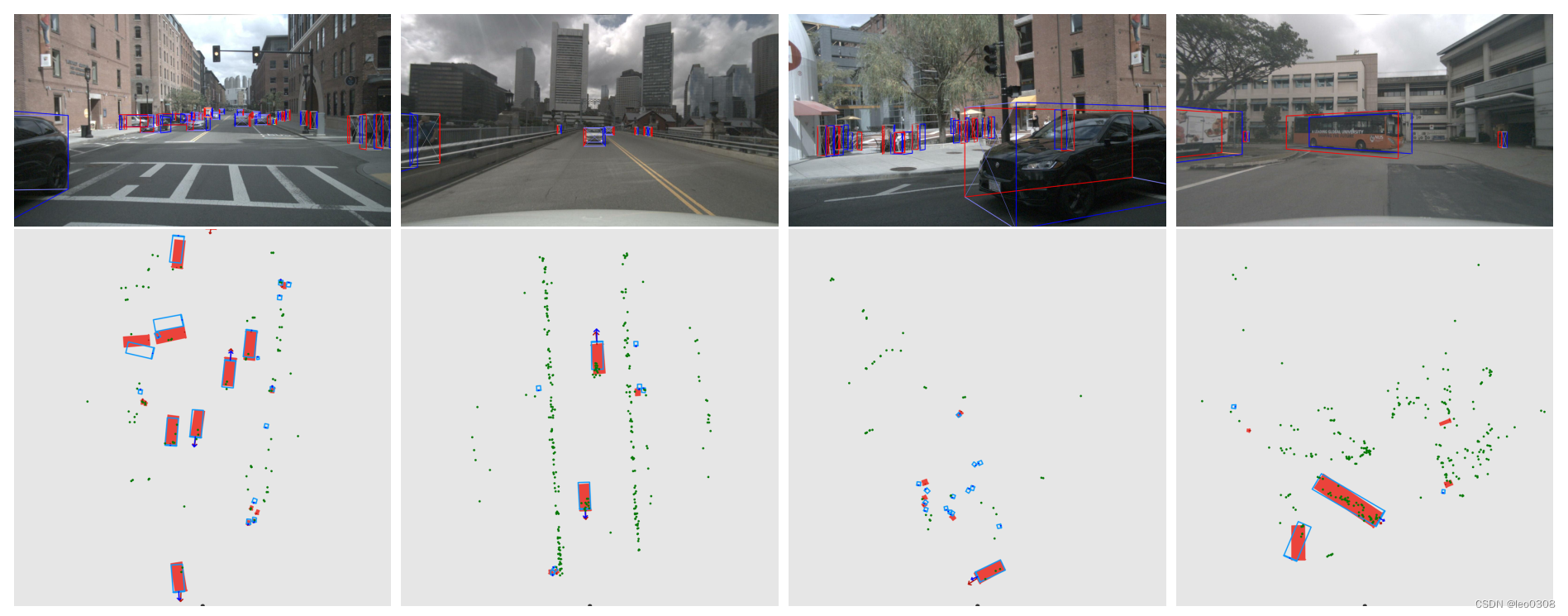
来几张检测的可视化的图, 直观地感受一下:
![[附源码]Python计算机毕业设计Django网上书城网站](https://img-blog.csdnimg.cn/a3274dc4a79f411bb07e2f0bd6678472.png)







![[附源码]计算机毕业设计基于Springboot校园运动会管理系统](https://img-blog.csdnimg.cn/c19c818bb1794c05ab49ae926032c54e.png)





![[附源码]计算机毕业设计基于vuejs的文创产品销售平台app](https://img-blog.csdnimg.cn/dc78f1bb02974fa2bec3229d742fd92a.png)
![[附源码]计算机毕业设计甜品购物网站Springboot程序](https://img-blog.csdnimg.cn/6147589df72c4c79bfbd3358715dfbf3.png)