文章目录
- JVM
- 类的加载过程
- 类加载器有哪些
- 什么是双亲委派
- 双亲委派的好处
- 如何打破双亲委派
- java内存模型
- 栈帧的结构
- java堆的分代设计
- 对象内存分配
- 对应的GC
- 为什么需要Survivor区?只有Eden不行吗?
- 为什么要有两个Survivor区
- 对象创建过程
- 对象内存布局
- 对象头Mark Word
- 对象大小
- 对象访问方式
- JVM的GC执行时机是任何时候都可以吗?
- 常见的垃圾回收器
- serial:
- ParNew:
- Parallel Scavenge
- Serial Old:
- Parallel Old
- CMS
- G1
- 垃圾收集器分类
- 频繁的FullGC是怎么回事
- CMS并发更新失败的原因
- 三色标记算法
- 为什么G1三色标记要用SATB
- mysql
- 普通索引与唯一索引的区别
- mvcc工作机制
- http
- http与https的区别
- https为什么安全
- 多线程
- java线程模型
- 开放性问题
- 如何设计一个CDN服务器
JVM
类的加载过程
从总的阶段来看,一共分为五个动作,分别是加载、验证、准备、解析、初始化,当然,这几个动作不是依次执行的,像校验,是贯穿整个过程的。
第一步: 加载,这个过程主要完成3件事
通过一个类的全限定名来获取此类的二进制流
将二进制流中的静态存储结构,转化为方法区中的运行时数据结构
在内存中生成一个代表此类的Class对象,作为方法区中访问该对象数据的入口
第二步: 验证,主要分为4个阶段
文件格式验证:验证文件格式是否符合class文件格式规范(例如文件是否以0XCAFEBABE开头,版本号是否当前虚拟机能够解析等等)
元数据验证:验证描述信息是否符合JAVA规范(比如这个类是否有父类,是否继承了final修饰的类等等)
字节码验证:验证方法体的语义是否合法,符合逻辑
符号引用验证:验证符号引用能否转换成直接引用,包括直接引用能否被当前类所访问
第三步:准备
为类变量分配内存空间,并赋初始值。
第四步:解析
将符号引用替换成直接引用
第五步:初始化
初始化静态变量的值
执行静态代码块
初始化当前类的父类
类加载器有哪些
Bootstrap ClassLoader(启动类加载器)
Extension ClassLoader(扩展类加载器)
Application ClassLoader(应用程序加载器)
自定义类加载器

什么是双亲委派
当需要加载一个类时,先委托父类加载器去完成,如果父类加载器完成不了,才会尝试自己去加载。
双亲委派的好处
安全,防止核心类被外部篡改
避免类重复加载
如何打破双亲委派
重新loadClass方法
设置上下文类加载器
java内存模型
堆: 堆中存放所有new出来的对象
方法区: 类信息、静态变量、常量、即时编译的代码
程序计数器: 记录当前线程运行到哪一步了
本地方法栈: JVM执行native方法的栈
java虚拟机栈: JVM执行java程序的栈
其中,堆,方法区线程共享,其他的线程私有

栈帧的结构
局部变量表: 方法中定义的局部变量以及方法的入参(局部变量表中的数据不能直接使用,如果要使用的话,必须调用相关指令将其加载到操作数栈中作为操作数使用)
操作数栈: 以压栈和出栈的形式存储操作数的
动态链接: 将常量池中的调用其他方法的符号引用转化为直接引用
方法返回地址

java堆的分代设计
Young区:年轻代,包含Eden区和Survivor区
Old区: 老年代

对象内存分配
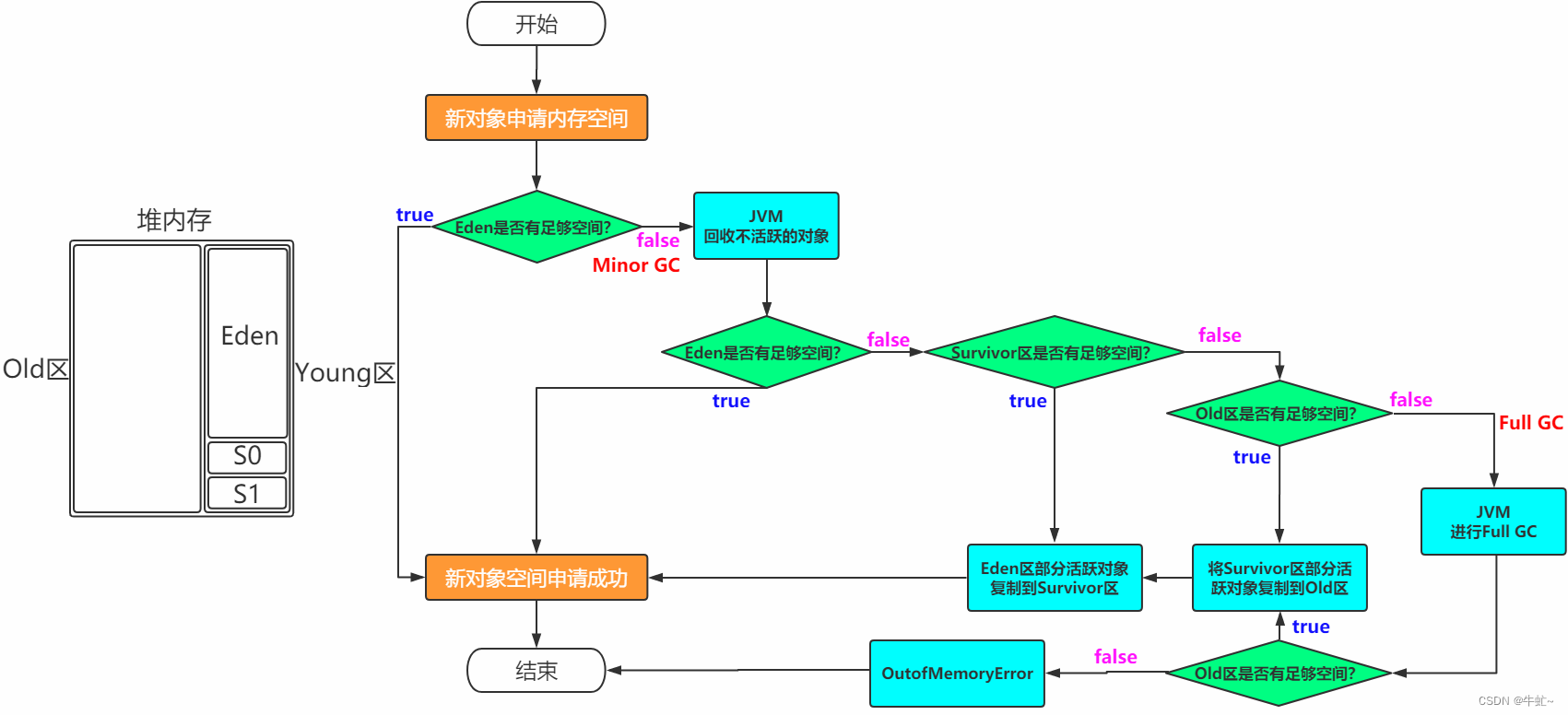
对应的GC
Young区: Young GC(minor GC)
Old区: Old GC(major GC)
Young区+Old区: Full GC,这个是当堆内存不足时触发
为什么需要Survivor区?只有Eden不行吗?
因为新生代使用的算法是复制回收算法,如果只有Survivor区,那么回收一次就会被送往Old区
这样会导致Old区很快被填满,触发Old GC(一般Old GC会伴随着Young GC,也就是Full GC)
老年代的空间一般大于新生代,所以消耗的时间比较长
另外老年代使用的回收算法是标记清除与标记压缩,不适合频繁的触发
所以,存在Survivor区的意义在于,对象不会很快被送到Old区,只有回收16次,才会被送往老年代
为什么要有两个Survivor区
其实是为了解决碎片化问题,因为复制算法,必须有有一块连续并空余的内存,Eden区回收一次后进入Survivor区
那么找不到一块连续的空间,去进行复制回收算法。
对象创建过程
- 先看该类是否被加载,如果没有被加载,先去加载(到常量池中查询是否有该类的符号引用,并且该Class类是否被初始化完毕)
- 分配内存空间
2.1 分配内存的方式:
内存连续: 指针碰撞(移动指针偏移位即可)
内存不连续: 空闲列表(寻找一块能够创建该对象的区域)
内存的是否连续,跟使用的垃圾回收器有关
2.2 如果开辟内存期间,存在并发,怎么办
CAS的方式
本地线程分配缓存(每个线程有自己独立的空间,在自己独立空间内开辟内存) - 成员变量赋初始值
- 设置对象头信息(markword,Class Point)在·
- 对象初始化
对象内存布局
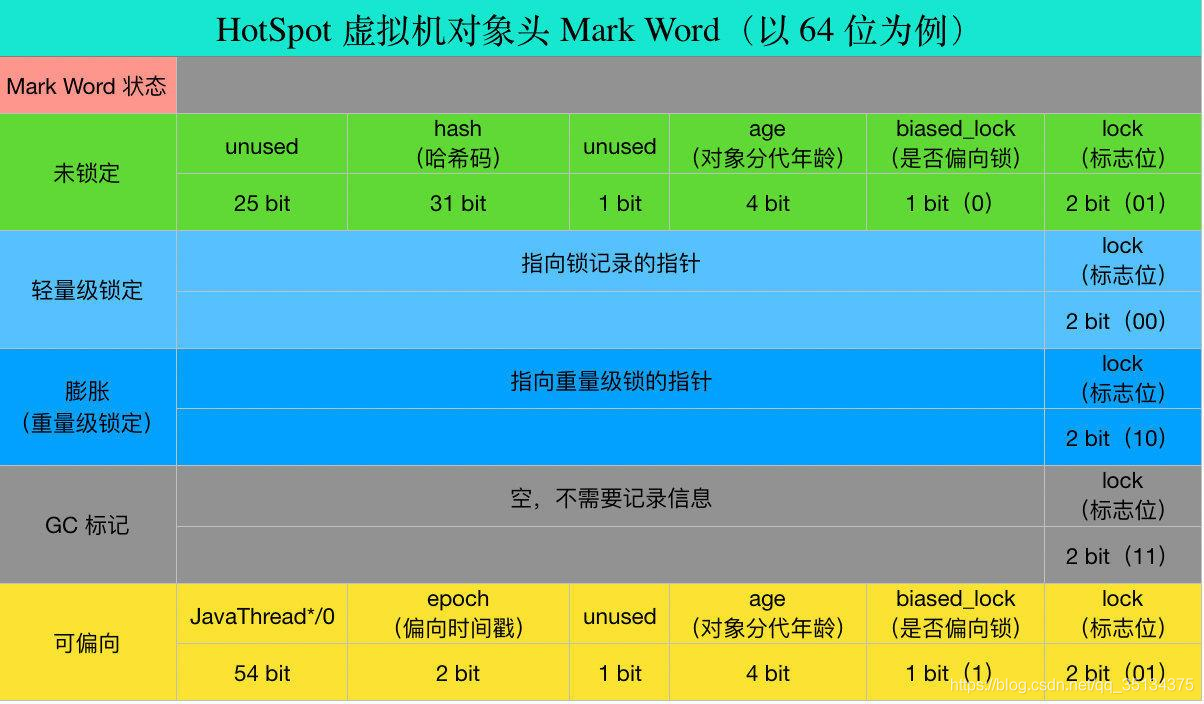
对象头: markword、ClassPoint、length(数组独有)
实例数据: 成员变量
对其填充: 保证对象大小满足8字节的整数倍

对象头Mark Word
对象大小
| 名称 | 大小 |
|---|---|
| markword | 8 |
| ClassPointer | 默认为4字节,关闭指针压缩为8字节 |
| boolean | 1 |
| byte | 1 |
| short | 2 |
| char | 2 |
| int | 4 |
| float | 4 |
| long | 8 |
| double | 8 |
| 数组 | size占4个字节,加上实例数据大小 |
| 引用类型 | 开启指针压缩为4,不开启为8 |
| padding | 8的倍数对齐 |
对象访问方式
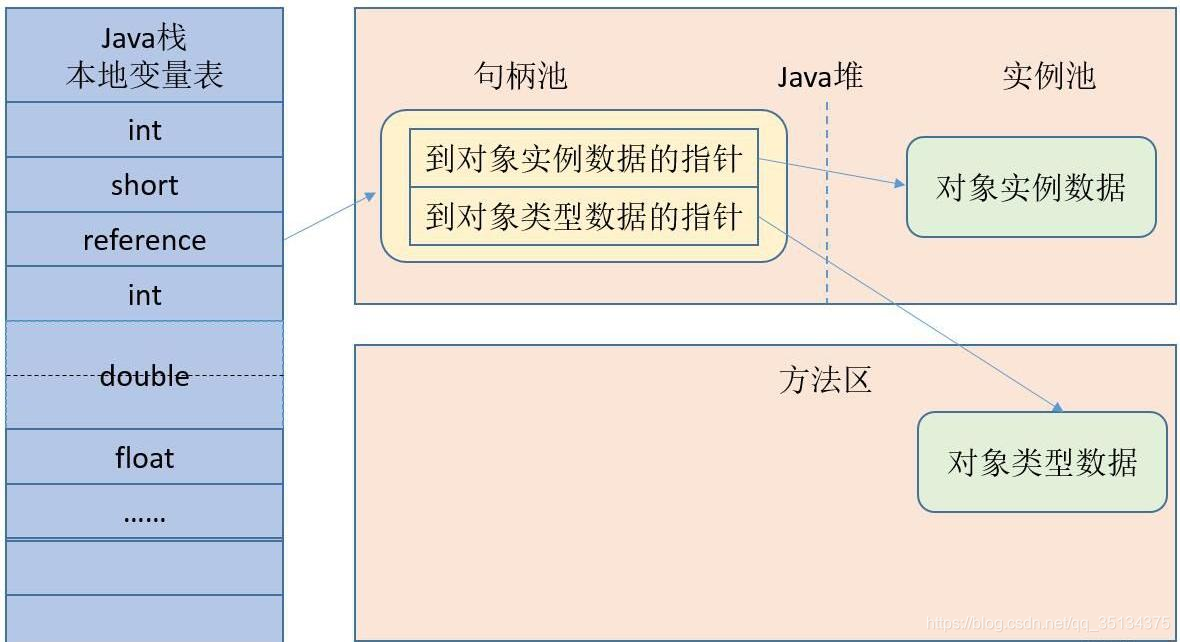
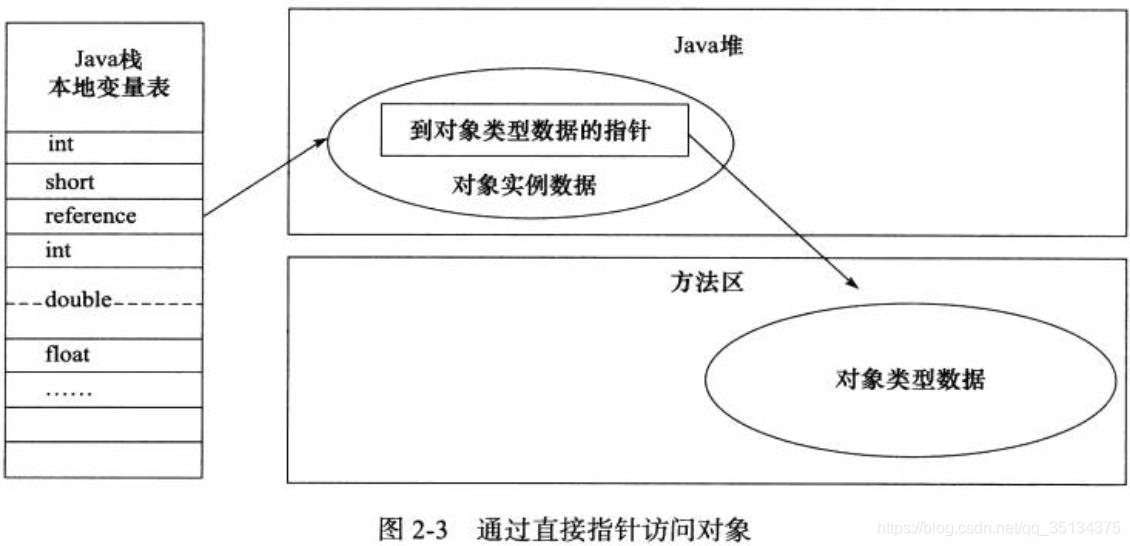
主流的方式有使用句柄跟直接指针两种,HotSpot是使用的直接指针
句柄访问: 变量中存储的是句柄的地址,而句柄中分别存储了对象的类型数据地址(方法区)与对象的实例数据地址(堆)
直接访问: 变量中存储对象的实例数据地址
优缺点:
句柄访问的方式,如果实例对象地址发生变化,不需要更新变量的地址,但是多了一层访问,访问速度低于直接访问
直接访问的优点: 访问速度快
- 句柄池(先执行一块地址,存储的对象地址与class地址,访问这个对象的地址需要经过两步,但是在gc回收时,效率较高)
- 直接指针(直接指向对象)
JVM的GC执行时机是任何时候都可以吗?
程序执行时,并非所有地方都能停下来GC,只有在特定的位置,才会去去执行GC,这些特定的位置被称为安全点。
这些特定的位置,就是安全点,这些安全点的选定标准是"是否长时间执行"的特性,比如方法调用,循环跳转,异常跳转等
在GC的时候,有两种方案能够让线程准确的停留在安全点上
抢占式中断: 先让所有线程中断,然后让那些停留在不安全点上的线程跑到安全点上。
主动试中断: 当需要GC是,设置一个标志,线程执行过程中,当发现这个标志的时候,就会主动挂起线程。
除了在安全点上,还有一些情况,比如线程sleep或者blocked状态,那么安全区域来解决
只要在一个特定区域中,对象引用状态不会发生改变,就可以发起GC,当进入安全区域时,就标记自己已经进入了安全区域,那么,在这段时间发起GC时,就不用管是否在安全点上了
常见的垃圾回收器
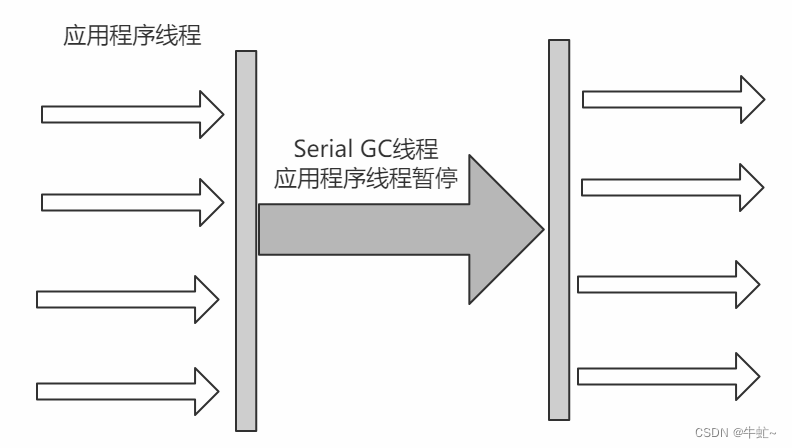
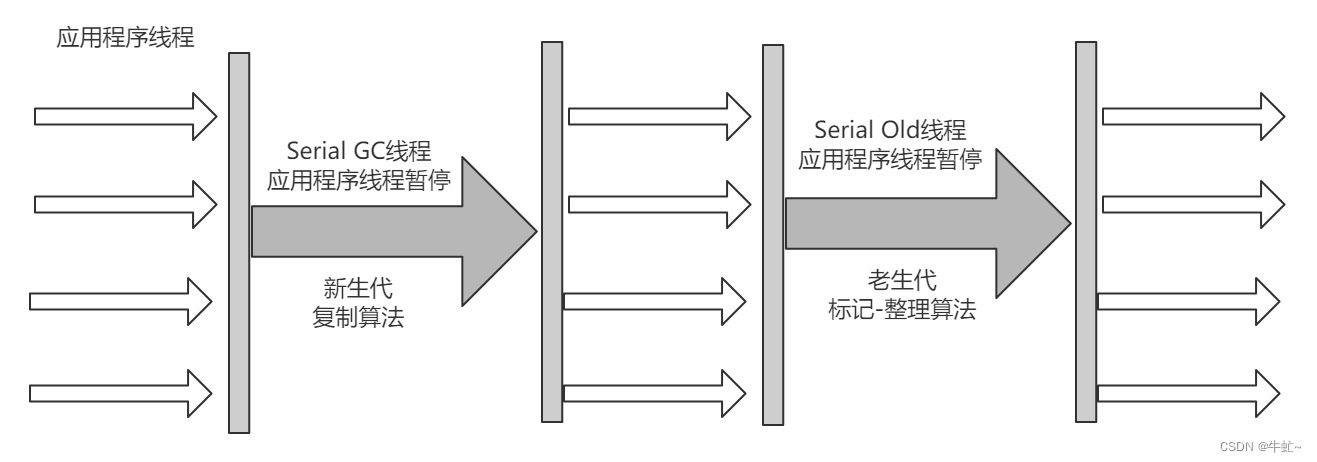
serial:
单线程的垃圾回收器
适合client端使用
优点: 单核效率最高,简单高效
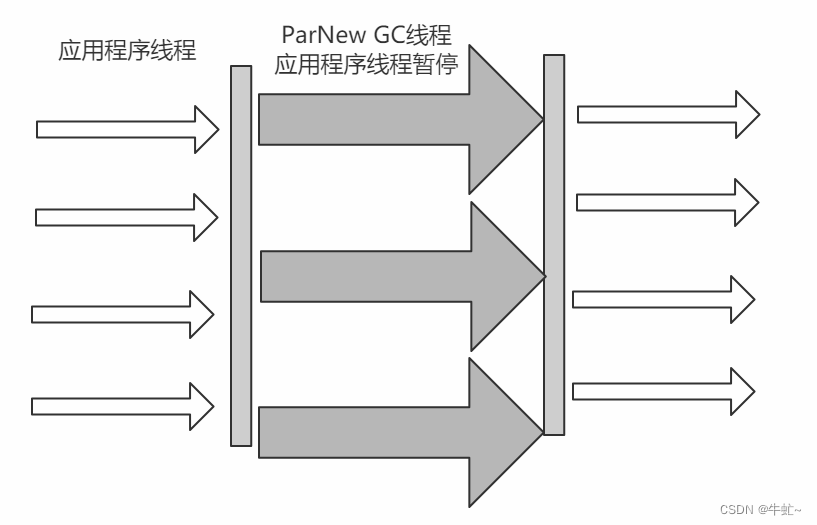
ParNew:
多线程的垃圾回收器
适合service端使用
优点: 适合多线程使用
对于Serial来说,优化的是STW的时间
Parallel Scavenge
与Parnew类似,也是多线程的垃圾回收器
不同点在于,更加注重的是吞吐量,可以手动指定吞吐量,也可以自适应
Serial Old:
单线程的垃圾回收器
使用标记整理算法
JDK1.5之前的老年代垃圾回收器或者作为CMS的备选方案
Parallel Old
多线程的垃圾回收器
与Parallel Scavenge配合,JDK1.6推出。
使用标记整理算法
Parallel Scavenge与Parallel Old配合,用于注重吞吐量的场合
CMS
并发的垃圾回收器
主要是为了优化减少停顿时间
垃圾回收的过程分为了
初始标记: 主要是找到所有的GC Root,这一步是STW的
并发标记: 标记这条引用链上的所有对象,这一步是并发执行
重新标记: 修正并发标记期间产生的变化,这一步是STW的,要比初始标记时间长点,但是远没有并发标记时间长
并发清除: 并发去清理垃圾,这一步是并发执行的
使用CMS也会产生一些问题
CMS的线程数的计算公式(CPU数量+3)/4,如果CPU线程数越少,工作线程执行效率越低,例如只有CPU数量只有两个的时候,那么用户线程的工作效率会降低50%
CMS当老年代分配不下时,会触发Full GC,使用Serial Old单线程垃圾回收器来回收
CMS采用的是标记清除,所以会产生浮动垃圾,由于工作线程与垃圾回收线程同时运行,那么很有可能会出现明明还有很大空间,但是却找不到一块连续的空间来放这个对象,这时候也会触发Full GC
CMS的CPU建议在四核以上

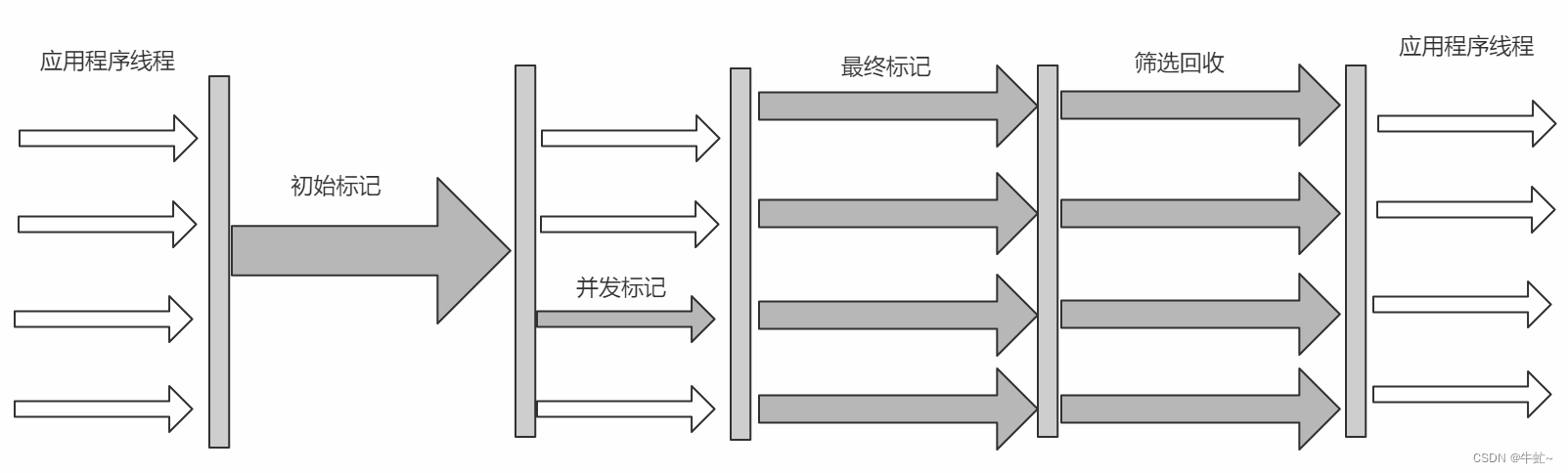
G1
并发的垃圾回收器,可以由用户手动指定停顿时间
垃圾回收过程:
初始标记
并发标记
重新标记
筛选回收: 根据每个Regin区价值(回收获得的空间大小以及回收所需要的时间)排序,优先回收在用户指定时间内的垃圾
回收算法: 从两个Regin区间看的话,是采用的复制算法,如果从整体看的话,是标记压缩算法,可以减少内存碎片的产生。
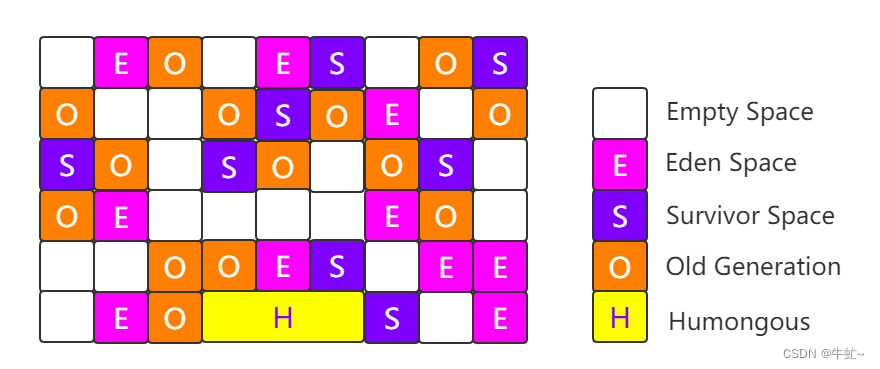
逻辑分代,分为一个一个的Regin区,每一个Regin区可以是为Eden区、Survivor区、Old区,Humongouns可能跨好几个Regin区来存放大对象
G1分成了2048个Regin区,每一个Regin区大小1M-30M之间
Remembered Set中存放的是当前Regin区中,每个对象被哪些对象所引用,这个引用可能跨Rengin
引用关系的记录维护在Remembered Set中,判断存活对象,只需要扫描Remembered Set即可,就不需要扫描整个堆了
垃圾收集器分类
- 串行收集器->Serial和Serial Old
只能有一个垃圾回收线程执行,用户线程暂停。
适用于内存比较小的嵌入式设备 。 - 并行收集器[吞吐量优先]->Parallel Scanvenge、Parallel Old
多条垃圾收集线程并行工作,但此时用户线程仍然处于等待状态。
适用于科学计算、后台处理等若交互场景 。 - 并发收集器[停顿时间优先]->CMS、G1
用户线程和垃圾收集线程同时执行(但并不一定是并行的,可能是交替执行的),垃圾收集线程在执行的时
候不会停顿用户线程的运行。
适用于相对时间有要求的场景,比如Web 。
频繁的FullGC是怎么回事
首先发生Full GC说明是老年代满了,那么有如下可能性
一般Full GC的原因是老年代满了,那么老年代满了又有很多种情况
1. 年轻代满了,对象直接进入老年代,那么像这种情况,调大Young区
2. 大对象直接进入老年代
3. 内存泄漏
4. 频繁调用System.gc()
CMS并发更新失败的原因
因为并发标记阶段,用户线程与垃圾回收线程同时在运行,那么如果此时新进来对象新生代老年代都放不下,那么就可能导致晋升失败
如果是这种情况,那么有如下几个解决办法
1. 如果是年轻代设置的太小了,导致对象很容易进入老年代,那么年轻代空间设置的较大点即可
2. 如果老年代设置的太小了,导致对象放不下,那么老年代设置的大一点
3. 另外,增加老年代的回收频率
三色标记算法
白色: 未被标记过的对象
灰色: 自身被标记,子节点没有被标记
黑色: 自身与子节点都有被标记
漏标: 满足漏标,必须是黑色对象指向灰色对象,灰色对象指向白色对象,这时候,黑色对象指向白色对象,同时,灰色对象对白色对象的引用消失,这时候就会产生漏标的情况。
那么解决漏标的话,有两种解决方案
CMS: increment update -> 关注引用增加,也就是将黑色对象重新标记成灰色对象
G1: SATB -> 关注引用删除,引用删除时,将他加入到栈中,由于有Remembered Set的存在,就不需要扫描整个堆去查找指向白色的引用,效率较高

为什么G1三色标记要用SATB
SATB是关注的引用删除,当引用删除时,将他加入到一个栈中
当进行回收时,只需要将栈中数据拿出来遍历,并查询Remembered Set就可以解决漏标的问题了,这样就不用扫描整个堆了,效率比较高
mysql
普通索引与唯一索引的区别
mvcc工作机制
http
http与https的区别
https为什么安全
多线程
java线程模型
开放性问题
如何设计一个CDN服务器
- 如何确定用户在哪
根据用户ip地址来判断用户的位置,例如(北京海淀联通) - 如何做分发
2.1 用户配置域名解析 域名->CDN域名
2.2 根据用户的位置,指向离用户最近的CDN服务器
2.3 这台CDN服务器查找是否有该数据,如果没有,去源站获取 - 内容管理
3.1 是否满足用户设置的存储规则,如果不满足直接重定向到源站
3.2 如果满足规则, 查询是否有该数据,如果有直接返回数据
3.3 如果没有该数据,从源站中拉取数据存储,并返回给用户

![[附源码]计算机毕业设计基于vuejs的文创产品销售平台app](https://img-blog.csdnimg.cn/dc78f1bb02974fa2bec3229d742fd92a.png)
![[附源码]计算机毕业设计甜品购物网站Springboot程序](https://img-blog.csdnimg.cn/6147589df72c4c79bfbd3358715dfbf3.png)