需要从PointNet网络框架中提取encoder部分的参数,然后赋予自己的模型。因此,需要从一个已有的.pth文件读取部分参数,加载到自定义模型上面。做了一些尝试,记录如下。
关于模型保存与载入
torch.save(): 使用Python的pickle实用程序将对象进行序列化,然后将序列化的对象保存到disk,可以保存各种对象,包括模型、张量和字典等。
torch.load(): 使用pickle unpickle工具将pickle的对象文件反序列化为内存。
可以看出,pth文件本质上是一个序列化的dict。
我们在save时,代码如下:
state = {
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
}
然后以下代码load进来:
checkpoint = torch.load(args.model_file, map_location=device)
model.load_state_dict(checkpoint['model_state_dict'])
查看checkpoint,可以看到包含的就是自己保存时的3个dict,分别是epoch,model_state_dict,和optimizer信息。
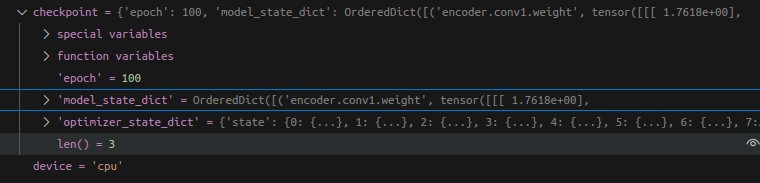
这里我们重点关注 model_state_dict,数据类型是一个 OrderedDict,有序字典。展开如下:
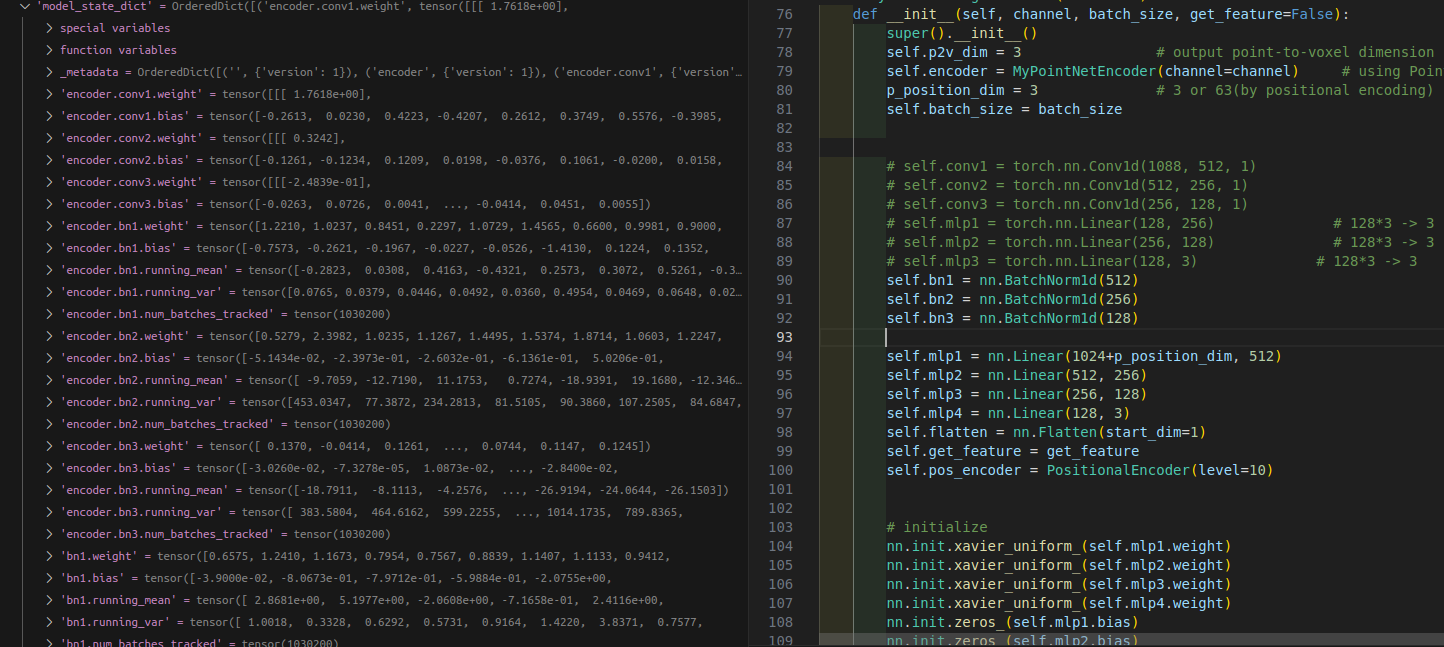
可以看到里面包含了自己定义的encoder,bn1-3,mlp 1-4层,以及每个层对应的参数(权重、bias,对于bn层还有mean, var等)。
这个Dict的顺序就是在Model中我们定义的顺序,这个和模型是一致的。
因此,如果载入时的模型和保存模型完全一致,直接用load_state_dict()就可以按顺序把数据载入进来。但如,如果定义不同怎么办?这就需要手动载入。
方法1:手动载入指定层的参数
从debug的断点可以看到,每个参数就是存在dict中的一个tensor。因此,我们只要读取对应的dict即可。
例如,encoder的conv1的权重,就是 checkpoint['model_state_dict']['encoder.conv1.weight'],那么我们在自己的模型对应的位置读取这个dict即可。
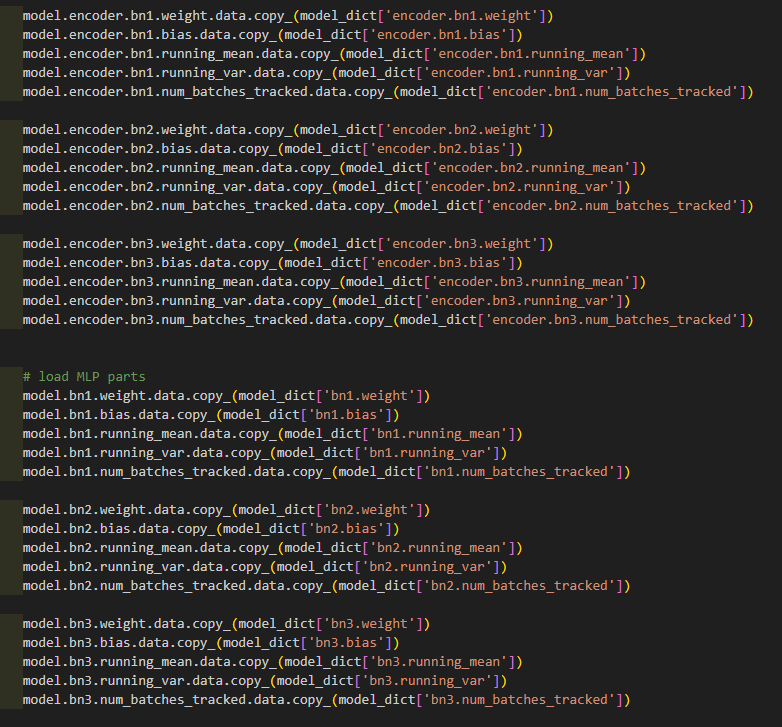
具体载入方式如下:
# 定义模型
model = MyPointNetSegmentation(channel=3, get_feature=True, batch_size=1)
model.to('cpu')
# 载入其他模型的参数
checkpoint = torch.load(model_file, map_location='cpu')
model_dict = checkpoint['model_state_dict']
# 将其他模型的参数,赋值给自己模型对应参数
model.encoder.conv1.weight.data.copy_(model_dict['encoder.conv1.weight'])
model.encoder.conv1.bias.data.copy_(model_dict['encoder.conv1.bias'])
把所有有用的参数都赋值过来就好,但要注意参数对应的tensor维度是一样的。
方法2:一次性载入key值相同的参数
如果说两个model的某些key值相同,可以用python的字典推导方式,将名称相关的参数提取出来。例如:
def load_dict_from_pointnet(model : Point2VoxelNet, checkpoint):
my_model_dict = model.state_dict()
pretrained_dict = checkpoint['model_state_dict']
# 只将pretraind_dict中那些在model_dict中的参数,提取出来
state_dict = {k:v for k,v in pretrained_dict.items() if k in my_model_dict .keys()}
my_model_dict.update(state_dict) # 注意要更新state的变量,如果直接赋值,会出现某些key没有定义,导致运行失败
model.load_state_dict(my_model_dict)
# 对比参数是否一致
print(f"{checkpoint['model_state_dict']['feat.stn.conv1.weight'][1]}")
print(f"{model.feat.stn.conv1.weight[1]}")
return model
看到这里,可以知道如果自己的模型改了名称,例如.pth的参数是:feat.stn.conv1,我这边叫做了 encoder.stn.conv1,那么是无法直接赋值的。可以用方法1,一个个载入,但是太慢了。另一种方式,是做一个键值映射,如果读到的是 feat.xxx,则赋予自定义模型中的 encoder.xxx ,简单处理即可。
注意事项
- conv层需要载入的参数有:weight 和 bias
- BN层涉及的参数有:
- weight,bias
- running_mean,running_var:这两个参数用于归一化的均值和方差, 因此也需要载入
- num_batches_tracked:在训练时需要载入,在test时不需要载入
- 载入参数后,如果用于测试,需要调用
eval()。注意不能在载入参数前调用 eval。eval 会将 bn 层的training参数设置为 false ,这样在测试时 batch_size 时如果是 1 也能够正常运行。
测试
用默认方式载入参数,以及手动方式载入后的两个模型,预测结果一致。