1.前情提要
下载paddlespeech官网代码并运行http服务进行中文识别时,会发现选择某些模型(我用的是conformer_wenetspeech),是别的结果为一串文字,没有标点,效果如下:
经过调用padddlespeech相关的库、修改相关代码,可以实现如下效果:
如果您感兴趣,就继续往下看吧~~~
可能你主要用的不是http服务,希望这篇文章也可以给你一些启发~~~


2.主要代码修改
🌟🤔️🌟
首先在ps的官方github页面有提到,可以用一下方法对文字串加符号:
import paddle from paddlespeech.cli.text import TextExecutor text_er = TextExecutor() result = text_executor( text='今天的天气真不错啊你下午有空吗我想约你一起去吃饭', task='punc', model='ernie_linear_p7_wudao', lang='zh', config=None, ckpt_path=None, punc_vocab=None, device=paddle.get_device()) print('Text Result: \n{}'.format(result)) ~ ~你可以先运行一下这段代码,确定能运行出加标点的结果。
由此,也可以确定出我们的解决思路:找到ps模型的输出结果,在其输出到前端之前,进行上面的text_executor()处理就行。
🌟🤔️🌟
因为我主要用到的是ps的http服务,我发现正常运行服务的时候终端会输出一下结果:
因此只要确定输出这两行日志的程序在哪里,改该处的代码就可以实现我们想要的效果了。
🌟🤔️🌟
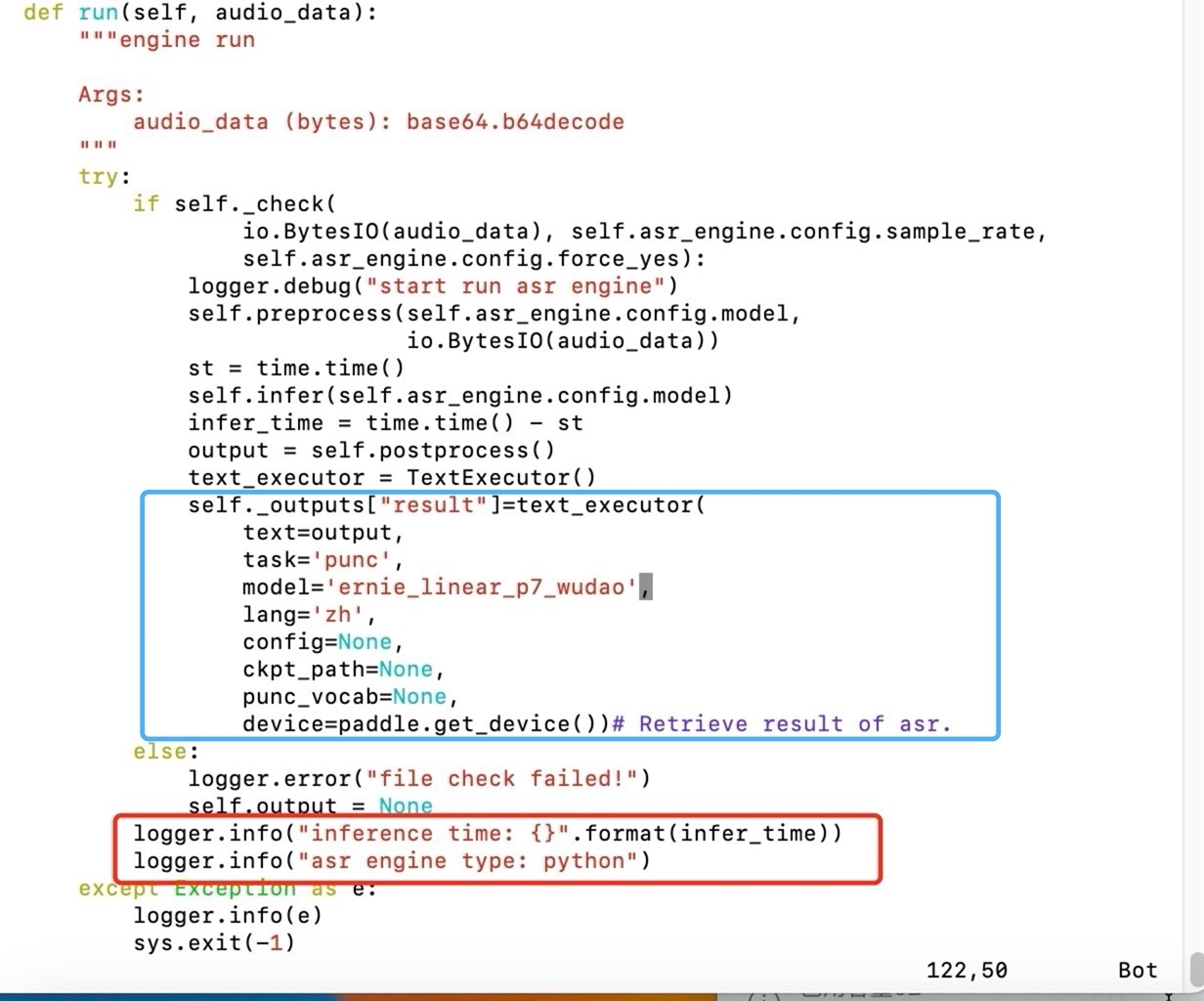
经过千辛万苦,终于找到对应执行的文件:
/usr/local/lib/python3.7/dist-packages/paddlespeech/server/engine/asr/python/asr.engine.py
经过阅读该代码以及该代码调用的其他程序,可以知道,ps语音识别的结果其实是存储在self._outputs["result"]里,因此,只要对self._outputs["result"]进行处理即可。