深度学习(22)——YOLO系列
文章目录
- 深度学习(22)——YOLO系列
- 1. 物体检测方法的两种类型
- 2. YOLO-v1
- 2.1 网络结构
- 2.2 loss 函数
- 2.3 NMS(非极大值抑制)
- 2. 4 优缺点
- 3. YOLO v2
- 3. 1 相较于v1改进点
- 3. 2 网络结构
- 3.3 感受野
- 3.4 特征融合的方法
- 3.5 夸夸v2
- 4. YOLO v3
- 4. 1 在v2的基础上的改进
- 4.2 网络结构
- 4.3 anchor设计
- 4.4 softmax 改进
最近在看物体检测方面的东西,第一个一定是YOLO系列,所以最近的两到三个博客会展开记录自己的学习过程。
1. 物体检测方法的两种类型
-
two-stage
- RCNN
- FastRCNN
-
one-stage
- YOLO
2. YOLO-v1
为什么YOLO的使用面广?快!没别的!
YOLOv1是第一个版本的YOLO算法,它将目标检测问题转化为一个回归问题。具体来说,YOLOv1使用了一个单一的CNN网络,在输入图像上进行多尺度的滑动窗口操作,然后通过回归预测每个窗口内是否存在目标以及其边界框的位置和大小。但是,YOLOv1存在两个主要问题:定位不准确和对小目标不敏感。
2.1 网络结构
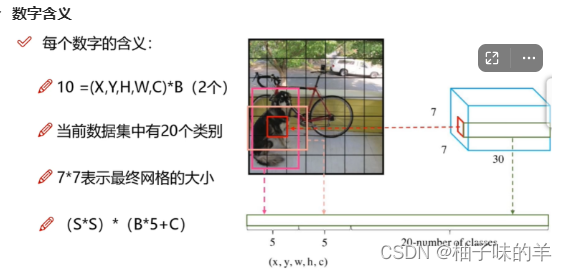
- 虽然卷积对输入没有要求,但是因为有全连接层,所有要确定全连接层前面特征图的大小,所以YOLO的输入图片大小固定
- 卷积得到特征图——>全连接——>7730 (5【4个偏移+1个置信度】+5+20类别)
举例
如果有两个候选框,20个类别
2.2 loss 函数
-
位置误差——MSE
-
置信度误差(背景多,加权重削弱背景重要性)——BCE
- 含object(前景)
- 不含object(背景,有权重)
-
分类误差——BCE
2.3 NMS(非极大值抑制)
按照置信度进行排序,IOU满足一定值时,取出极大值即可
2. 4 优缺点
-
优点
- 网络结构简单
- 快速简单
-
缺点
- 一个点只有一个类别,重合的物体很难检测到
- 小物体检测不到
- 多标签难做
3. YOLO v2
3. 1 相较于v1改进点
- 采用Darknet-19作为特征提取网络,增加网络的深度和感受野
- 舍弃dropout,卷积以后全部加入BN(batch normalization)
- 网络每一层的输入都归一化,收敛相对容易(现在非常主流的一种方法)
- V2分辨率更大,训练使用224224,测试使用448448,V2训练时额外进行了10次448*448做微调
- 聚类提取先验框
- V1只有两种先验框
- faster-rcnn中的先验比例比较常规,但是不一定完全适合数据集(不同scale,每个scale有几个不同大小的框)
- 在CoCo中有很多label的框,对这些框做K-means聚类(聚类过程中发现cluster越多越精准,但是没必要,5个的时候效果已经存在)
- 感受野更大
3. 2 网络结构
- 没有全连接层(全连接层容易过拟合,参数多训练慢)
- 5次下采样
- 一般输入(416416)要是2的倍数(下采样),最终希望是奇数(1313),奇数只有一个中心点,偶数存在四个中心点
- 使用很多1*1卷积:只改变特征图个数
- 小卷积核,参数量少,感受野大
3.3 感受野
感受野:特征图上的点能看到原始图像多大区域
- 浅层特征:纹理线条
- 中间特征更高级
- 网络最深层的特征往往是全局特征
- 用多个小卷积核可以取代大的卷积核的同时还可以节省参数量
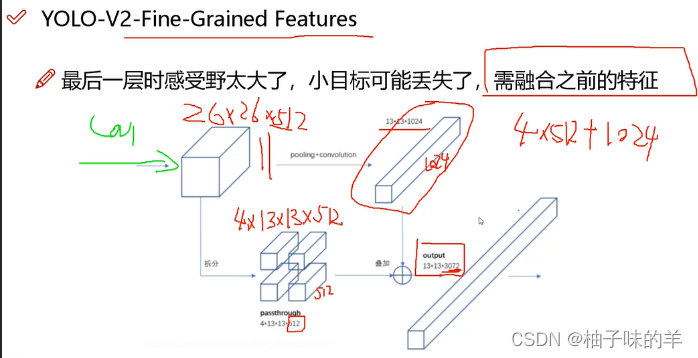
- 越大的感受野,保留的特征是越大的,小目标会丢失 ,需要融合前面的特征
3.4 特征融合的方法
3.5 夸夸v2
- 没有全连接层,无所谓输入图片的输入大小
- 一般输入大小是32的倍数
- 更快更强
4. YOLO v3
4. 1 在v2的基础上的改进
- YOLOv3使用了更深的Darknet-53作为特征提取网络,增加了网络的层数,进一步提取图像特征。
- YOLOv3引入了多尺度检测的概念,将输入图像划分为不同大小的网格,并在每个网格上进行目标检测,以便检测不同尺度的目标。
- YOLOv3还采用了三个不同尺度的特征图来进行目标检测,分别用于检测大、中、小尺寸的目标。
- YOLOv3对Anchor Boxes的使用进行了改进,通过K-means聚类算法自动确定合适的Anchor Box尺寸,进一步提高边界框的定位能力。
- softmax做改进,可以预测多标签任务
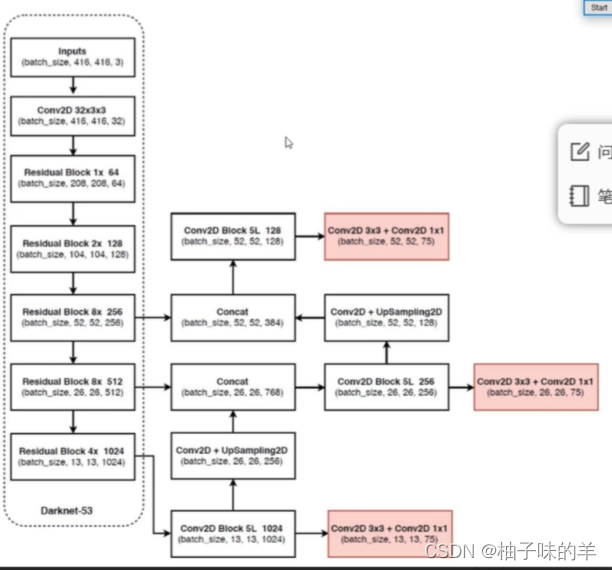
4.2 网络结构
- Darknet-53作为特征提取网络
- 没有池化和全连接,全部是卷积(卷积省时省力)
- 残差连接
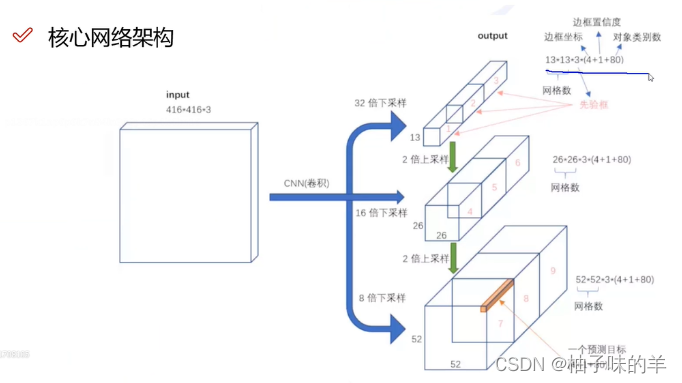
4.3 anchor设计
- v3中有9种常见规格的anchor,将大的先验框分配给1313的,因为他的特征更能顾虑到全局,中等大小的先验框给2626,小框给52*52得到的特征(不同大小感受野不同大小先验框)

4.4 softmax 改进
- v2检测到的物体只有一个标签,不能是多标签
- softmax做改进,将其转换成多个二分类
今天先这样吧,明天出YOLO v3的代码。感觉两个好像不够,感觉需要3+