目录
1 关于:re / regex / regular expression
1.1 什么是正则表达式
1.2 在python中导入 re
1.3 查看regex相关信息
2 正则表达式的相关符号
2.1 行定位符
2.2 元字符 (注意是 反斜杠\)
2.3 限定符号
2.4 字符类,字符集合 需要 中括号[]
2.5 排除字符 [^ ]
2.6 选择字符 |
2.7 转义字符 反斜杠 \
2.8 分组符号 ()
2.9 正则表达式需要用 " " 引号,但是要小心各种特殊符号
3 正则表达式的方法
1 关于:re / regex / regular expression
1.1 什么是正则表达式
- regular expression 正则表达式
- 是计算机科学的一个概念
- 是一个跨多种编程语言的语言格式
1.2 在python中安装正则 pip install regex (安装时不是 re !)
- 导入 re 模块
- 模块其实可以认为是一个 .py文件
- 错误写法: pip install re
- 正确写法: pip install regex
1.3 查看regex相关信息
- pip list
- pip show regex

1.4 在python中导入 re : import re
- 导入 re 模块
- 模块其实可以认为是一个 .py文件
- 正确写法: import re
2 正则表达式的相关符号
2.1 行定位符
用来描述字符串的边界,1行的边界?全部字符串的边界把? 可以叫做 字符串整体定位符?^ ^
^ #表示字符串开头
$ #表示字符串结尾
2.2 元字符 (注意是 反斜杠\)
\w #匹配 字母,数字,下划线等,还有各自文字,比如汉字
\W #^w 非w
\s # 匹配空格,换行,tab 等几种看不见的内容 也就是:空格 \n \t
\S #^s 非s
\b #begin 单词的开始的意思 如 \bw 匹配单词(不是整个字符串)开始的字母,数字,下划线等,所以 \b不同于 ^
\d # 匹配数字
. # 任意字符
三种括号也是有特殊意义的
() #匹配方括号的每个字符,比如(fruit|food)s 表示 fruits|foods
[] # 匹配方括号的任一个字符,比如 [abc] 表示 a,b ,c 都可以
{} # 限定次数符号,看下面
2.3 限定(次数)符号 : 次数 * + ? 以及{}
* # 匹配前面的字符0次/无限次
+ # 匹配前面的字符1次/无限次
? # 匹配前面的字符0次/1次,常用于 .*? 这种非贪婪模式
{n} # 匹配前面的字符n次
{n,} # 匹配前面的字符至少n次
{n,m} # 匹配前面的字符 最少n次,最多m次, n-m次之间的都符合
e.g
^/d{8} #匹配8个数字
.*s #非贪婪匹配任意个数字
2.4 字符类/字符集合 需要 中括号 [ ]
[abcd] # 匹配abcd中的任意一个都可以
[12345] # 匹配1-5中的任意一个都可以
[0-9] # 匹配任意一个数字,等同于\d
[a-z0-9A-Z] # 匹配所有英文字母,数字,几乎等同\w 是\w的子集(不含汉字等)
2.5 排除字符 [^ ]
关键字 ^
/W # 相当于/^w,但是写法不对,必须写在中括号里 [^] 写在外面还是表示字符串开始
[^a-zA-Z] # 相当于非英文字母以外的其他任意字符
2.6 选择字符 |
选择
条件选择 | 表示or的意思
e.g.
^\d{5}|^\d{6}
2.7 转义字符 反斜杠 \
- 转义字符
- 把 普通字符变成特殊意义的字符, n 转成 \n 换行符
- 把 特殊字符变成普通字符, \* 表示 普通字符 * \. 表示 普通字符 .
2.8 分组符号 ()
(fruit|food)s #表示 fruits|foods
([abc]{1,3}){3} #表示 [abc]1到3个,然后再来3个,一会试试
2.9 正则表达式需要用引号"" 包裹起来
如果有特殊符号,表达式前还要注意加 r
- 比如一般的
- ".*?"
- 实际使用时, 如果包含特殊符号,记得使用 r (rawdata)
- r"https://movie.douban.com/apex"
2.10 贪婪模式 / 非贪婪模式
贪婪模式
匹配符合条件的最多的字符数
非贪婪模式
匹配符合条件的最少的字符数
- .*? #非贪婪模式
- *?
- ??
- +?
- {n,m}?
3 正则表达式的方法
3.1 匹配和查找相关
- re.match()
- re.search()
- re.find()
- re.findall()
3.2 相同点和差别
- re.match()
- re.search()
- re.find()
- re.findall()
3.3 re.match()
- 语法
- re.match(pattern, string , flags=0)
- 必须从字符串开头开始匹配
- 返回 none/ 以(符合正则格式的)某字符串开头的 字符串
非贪婪匹配,如果一直到末尾,往往会匹配一个尽量少的字符串=none 空字符串
#E:\work\FangCloudV2\personal_space\2learn\python3\py0004.txt
# re相关
import re
str1=re.match("^\w*","abc123ABC456")
print (str1)
print (type(str1))
print (str1.group())
print (type(str1.group()))
print ("")
str2=re.match("^\w*?","abc123ABC456")
print (str2)
print (type(str2))
print (str2.group())
print (type(str2.group()))
print ("")
str3=re.match("abc","abc123ABC456",re.I)
print (str3)
print (type(str3))
print (str3.group())
print (type(str3.group()))
print ("")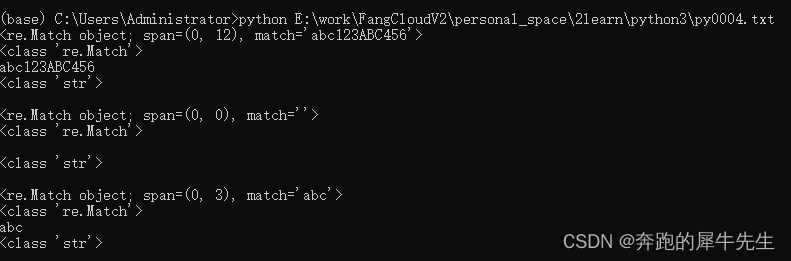
3.3.1 re.match().group()
- 返回一个数组?
- 数组式的字符串
- 默认参数为0,默认返回所有匹配到的字符串
3.3.2 re.match().span()
- 返回一个数组?
- 数组式的字符串
- 默认参数为0,默认返回所有匹配到的字符串
3.5 re.search()
- 语法
- search(pattern, string, flags=0)
- 可以从字符串的任何地方开始查找匹配
3.6 re.find()
- 语法
- find(pattern, string, flags=0)
- 返回none 或者
3.7 re.findall()
- 语法
- findall(pattern, string, flags=0)
- 返回一个列
3.8 re.sub()
- 语法
- sub(pattern, repl, string, count=0, flags=0)
- 在string内部,按正则 pattern 去替换 repl ,数量为 count 次
3.9 re.finditer
3.10 re.compile()
编译正则表达式
compile(pattern, flags=0)
3.11 re.split()
- 分隔
- 语法
- split(pattern, string, maxsplit=0, flags=0)
- 按 pattern 去分割 string,
- 并且返回一个列表!
继续看完
Python正则表达式用法总结_regex re python_zorchp的博客-CSDN博客正则表达式的Python实现以及re库的常用方法总结。https://blog.csdn.net/qq_41437512/article/details/107978327