一、Explain介绍
1、Explain不用版本的使用
在mysql8.0版本只能用explain,已经弃用了explain extended和explain partitions,用了都会出现语法问题,只能用explain;在explain语句后面加上show warnings;可以查看mysql优化后的语句,但这些语句不一定能正确执行
- explain extended
在mysql8.0版本之前,explain extended语句后面加上show warning;可以查看mysql优化后的语句,row*filtered/100可以估算出表连接数

- explain partitions
查看表的分区信息

2、Explain查询的列
用三个这样的表更加好理解explain查询列的详细信息:
DROP TABLE IF EXISTS `student`;
CREATE TABLE `student` (
`id` int(11) NOT NULL,
`name` varchar(45) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`create_time` datetime(0) NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact;INSERT INTO `student` VALUES (1, 'a', '2023-06-15 09:22:45');
INSERT INTO `student` VALUES (2, 'b', '2023-06-15 09:22:45');
INSERT INTO `student` VALUES (3, 'c', '2023-06-15 09:22:45');DROP TABLE IF EXISTS `teacher`;
CREATE TABLE `teacher` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(10) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
INDEX `idx_name`(`name`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 4 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact;INSERT INTO `teacher` VALUES (3, 'teacher0');
INSERT INTO `teacher` VALUES (1, 'teacher1');
INSERT INTO `teacher` VALUES (2, 'teacher2');DROP TABLE IF EXISTS `teacher_student`;
CREATE TABLE `teacher_student` (
`id` int(11) NOT NULL,
`teacher_id` int(11) NOT NULL,
`student_id` int(11) NOT NULL,
`remark` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
INDEX `idx_teacher_student_id`(`teacher_id`, `student_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact;INSERT INTO `teacher_student` VALUES (1, 1, 1, NULL);
INSERT INTO `teacher_student` VALUES (2, 1, 2, NULL);
INSERT INTO `teacher_student` VALUES (3, 2, 1, NULL);show warnings;查看mysql优化过后的sql
explain extended select * from teacher where id = 1;
show warnings;
查询的列:
- id:查询出来的执行编号,编号越大越先执行,如果编号相等则由上到下依次执行,id为 null最后执行
- select_type:
| simple | 简单查询,基本上就一个select |
| primary | 复杂查询中最外层的select |
| subquery | 子查询,在select之后from之前的查询 |
| derived | 衍生查询,在from之后的查询,把查询结果放到一个临时表中 |
| union | 有用union或者union all连接两个查询 |
explain select * from teacher where id = 2;#simple查询
set session optimizer_switch='derived_merge=off'; #关闭mysql5.7新特性对衍生表的合并优化 explain select (select 1 from student where id = 1) from (select * from teacher where id = 1) der; set session optimizer_switch='derived_merge=on'; #还原默认配置
id值按照从大到小执行,首先看select_type为DERIVED(衍生查询,查询的表是teacher,from之后的查询);select_type为SUBQUERY(子查询,查询的表是student,select之后from之前的查询);select_type为PRIMARY(复杂查询,说明查询中包含其它查询,最外层的select)
explain select 1 union all select 1;#union类型查询
- table:查询用到的表,如果查询需要依赖其它查询的结果,会包含其它explain查询id的值
- partitions:分区信息
- type:查询类型,查询速度由快到慢依次是system、const、eq_ref、ref、range、index、ALL,通常情况下最低保持在range级别
NULL:查询时不需要访问表
explain select 1; explain select min(id) from student;
system:系统查询表时只有一条数据匹配
set session optimizer_switch='derived_merge=off'; #关闭mysql5.7新特性对衍生表的合并优化 explain select * from (select * from student where id = 1) test; set session optimizer_switch='derived_merge=on'; #还原默认配置

const:当查询只有一条数据与之匹配
explain select * from student where id = 1;
eq_ref:当用主键或者唯一索引与主表进行关联
explain select * from teacher_student left join teacher on teacher_student.teacher_id = teacher.id; explain select * from teacher_student left join student on teacher_student.student_id = student.id;


ref:当用普通索引或者联合索引的左边部分字段与主表进行的关联或者做条件查询
explain select * from teacher where name = 'asd'; explain select teacher.id from teacher left join teacher_student on teacher.id = teacher_student.teacher_id;


range:用主键索引或者普通索引进行范围搜索,比如>,=,<,between and,like 'x%'
explain select * from student where id > 1; explain select * from teacher where name like 'x%';


index:这种虽然用到了索引,但是查询所有数据,在普通索引的索引树上的叶子节点查询所有,没有条件从而不会经过非叶子节点的筛选
explain select * from teacher;

ALL:这种是直接在主键索引上去找,而主键索引是聚簇索引树,包含所有数据,所以比index查找要慢
explain select * from student;

- possible_key:可能用到的索引键,如果为Null说明可能不会用到索引
- key:实际用到的索引键,如果为Null说明实际没用到索引
- key_len:索引使用的字节数
计算规则:
字符串类型
char(n):3n个字节
varchar(n):3n+2,加的2是用来存储字符串长度
数值类型
tinyint:1字节
smallint:2字节
int:4字节
bigint:8字节
实际类型
date:3字节
timestamp:4字节
datetime8字节
- ref:关联的表,通常展示const或者要查询列名
- rows:查询表的扫描行数的估值
- filtered:查询出来结果集占总扫描行数的百分比,结果越大说明扫描成本低
- extra:
Using index:使用覆盖索引
用普通索引或者联合索引左边部分字段作为条件,当查询的字段在一颗普通索引树上的叶子节点上都有,这个时候可以说这条sql查询使用了覆盖索引
EXPLAIN select * from teacher where name = '123'; EXPLAIN select teacher_id,student_id from teacher_student where teacher_id = 1;


Using where:使用where过滤的列未被索引覆盖
EXPLAIN select * from student where create_time = '2023-05-11 00:12:49'; EXPLAIN select * from student where name = 'test';


Using index condition:查询的列没有被覆盖索引覆盖到,where是一个联合索引左边部分范围查找
explain select * from teacher_student where teacher_id > 1;

Using temporary:查询时mysql自动建了一个临时表
explain select distinct name from student;#name无索引 explain select distinct name from teacher;#name有索引
distinct会新建一张临时表做去重,可以使用索引做优化

Using filesort:使用的是文件排序,这种排序非常慢的,可以使用索引排序,因为索引本身就是有序的数据结构
explain select * from student order by name;#name无索引 explain select * from teacher order by name;#name有索引


Select tables optimized away: 使用某些聚合函数(如:max、min)来访问某个存在索引字段
explain select min(id) from teacher;
二、索引基本优化示例
表:
DROP TABLE IF EXISTS `member`;
CREATE TABLE `member` (
`id` int(0) NOT NULL AUTO_INCREMENT,
`name` varchar(24) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL DEFAULT '' COMMENT '姓名',
`age` int(0) NOT NULL DEFAULT 0 COMMENT '年龄',
`address` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL DEFAULT '' COMMENT '地址',
`create_time` timestamp(0) NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY (`id`) USING BTREE,
INDEX `idx_name_age_address`(`name`, `age`, `address`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 5 CHARACTER SET = utf8 COLLATE = utf8_general_ci COMMENT = '会员记录表' ROW_FORMAT = Dynamic;
INSERT INTO `member` VALUES (5, 'LiLei', 22, 'manager', '2023-06-15 15:41:53');
INSERT INTO `member` VALUES (6, 'HanMeimei', 23, 'dev', '2023-06-15 15:41:53');
INSERT INTO `member` VALUES (7, 'Lucy', 23, 'dev', '2023-06-15 15:41:53');1、全值匹配
EXPLAIN SELECT * FROM member WHERE name= 'test' order by name desc;
EXPLAIN SELECT * FROM member WHERE name= 'test' AND age = 22;
EXPLAIN SELECT * FROM member WHERE name= 'test' AND age = 22 AND address ='manager';

 name、age、address为联合索引,最好都能用作条件,可以减少非叶子节点load到内存IO次数,减少匹配次数,查询更快
name、age、address为联合索引,最好都能用作条件,可以减少非叶子节点load到内存IO次数,减少匹配次数,查询更快
2、不要在索引字段上加函数匹配,导致全表扫描
EXPLAIN SELECT * FROM member WHERE name = 'LiLei';
EXPLAIN SELECT * FROM member WHERE SUBSTR(1,2) = 'LiLei';

给create_time添加一个普通索引
ALTER TABLE `member` ADD INDEX `create_time` (`create_time`) USING BTREE;
EXPLAIN select * from member where date(create_time) ='2018‐09‐30';#mysql8.0版本 类型校验不通过执行错误
EXPLAIN select * from member where date_format(create_time,'%Y-%m-%d') ='2018‐09‐30';两个explain执行结果:

 timestamp日期类型转成varchar,如果类型都转变了,再去索引树上去找就会找不到,会导致全表扫描
timestamp日期类型转成varchar,如果类型都转变了,再去索引树上去找就会找不到,会导致全表扫描
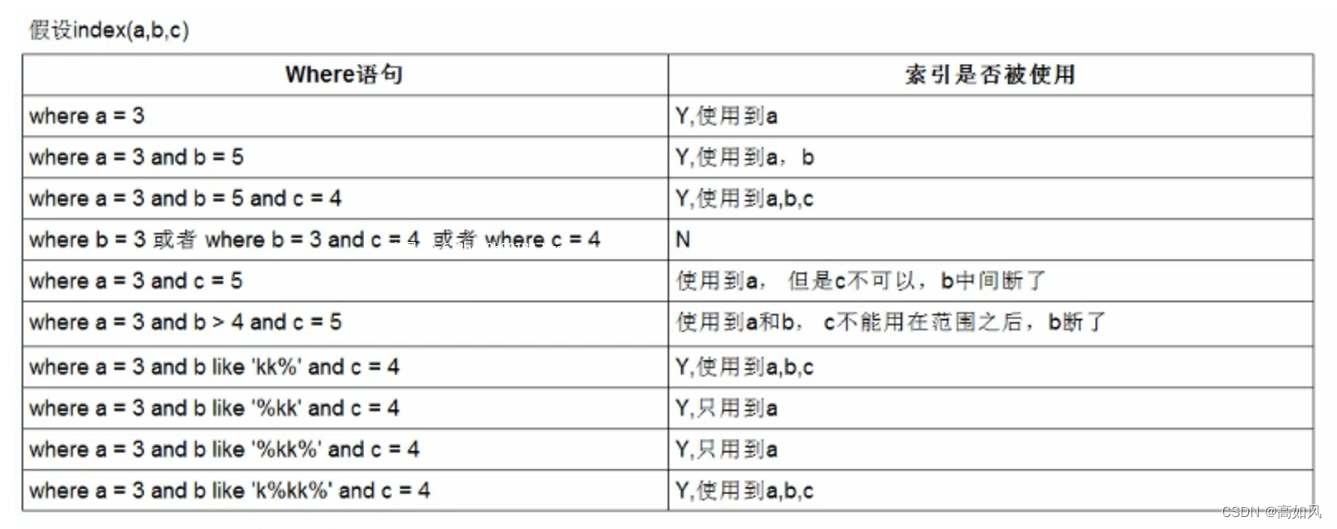
3、联合索引中的列使用范围查询导致用不到后面的索引列
EXPLAIN SELECT * FROM member WHERE name= 'test' AND age = 22 AND address ='guangzhou';
EXPLAIN SELECT * FROM member WHERE name= 'test' AND age > 22 AND address ='guangzhou';前一条sql索引全值匹配联合索引都会用到,后面sql因为是大于,非叶子节点之前没有指针,导致又需要从根节点重新加载匹配,或者因为范围太大导致,到address匹配时次数过多因而用不到address索引
4、尽量使用覆盖索引,只在二级索引树上查找效率快,查询所有的话要回表,效率慢
EXPLAIN SELECT name,age FROM member WHERE name= 'test' AND age = 23 AND address ='manager';
EXPLAIN SELECT * FROM member WHERE name= 'test' AND age = 23 AND address ='manager';

尽量使用第一条sql那样,把二级索引树上所有字段查询出来,这样可以不用回表,不要查所有,因为查询出来的所有记录都会回表
5、mysql中不要使用不等于、大于、小于、not in、not exists,查询范围大,用索引的话也差不多是全表扫描,最好控制条件范围,比如范围时间缩短、in条件减少
mysql8.0对not in、不等于做了优化,用了也会用到索引,mysql8.0之前的版本不会用到
EXPLAIN SELECT * FROM member WHERE name != '1';
EXPLAIN SELECT * FROM member WHERE name not in ('test','1','test','1','test','1','test','1','test','1','test','1','test','1');mysql8.0结果:


6、is null,is not null一般情况下无法用到索引
EXPLAIN SELECT * FROM member WHERE name is null
7、条件查询不要用like '%x'
EXPLAIN SELECT * FROM member WHERE name like '%test';
EXPLAIN SELECT * FROM member WHERE name like 'test%';

最好用第二条sql ,因为前缀已经确定了大部分数据
8、条件值和字段类型不同导致索引失效
EXPLAIN SELECT * FROM member WHERE name = '1000';
EXPLAIN SELECT * FROM member WHERE name = 1000;

用1000数值类型去索引树上找不到,改成全表扫描
9、少用or或in,还是范围过大,mysql根据成本计算,回表次数太多可能扫全表
mysql8.0对or和in都做了优化,能用到索引,之前的版本都可能用不到
EXPLAIN SELECT * FROM member WHERE name = 'test1' or name = 'test2';mysql8.0执行结果:

10、范围查询优化
ALTER TABLE member ADD INDEX idx_age (age) USING BTREE ;
explain select * from member where age >=1 and age <=2000;
explain select * from member where age >=1 and age <=1000;
explain select * from member where age >=1001 and age <=2000;
ALTER TABLE member DROP INDEX `idx_age`;#删除索引
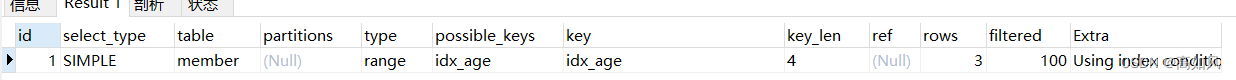
mysql8.0对这种也做了优化,可以用到索引,之前版本可能要拆成几段sql来查才能用到索引,像第二、三条sql一样