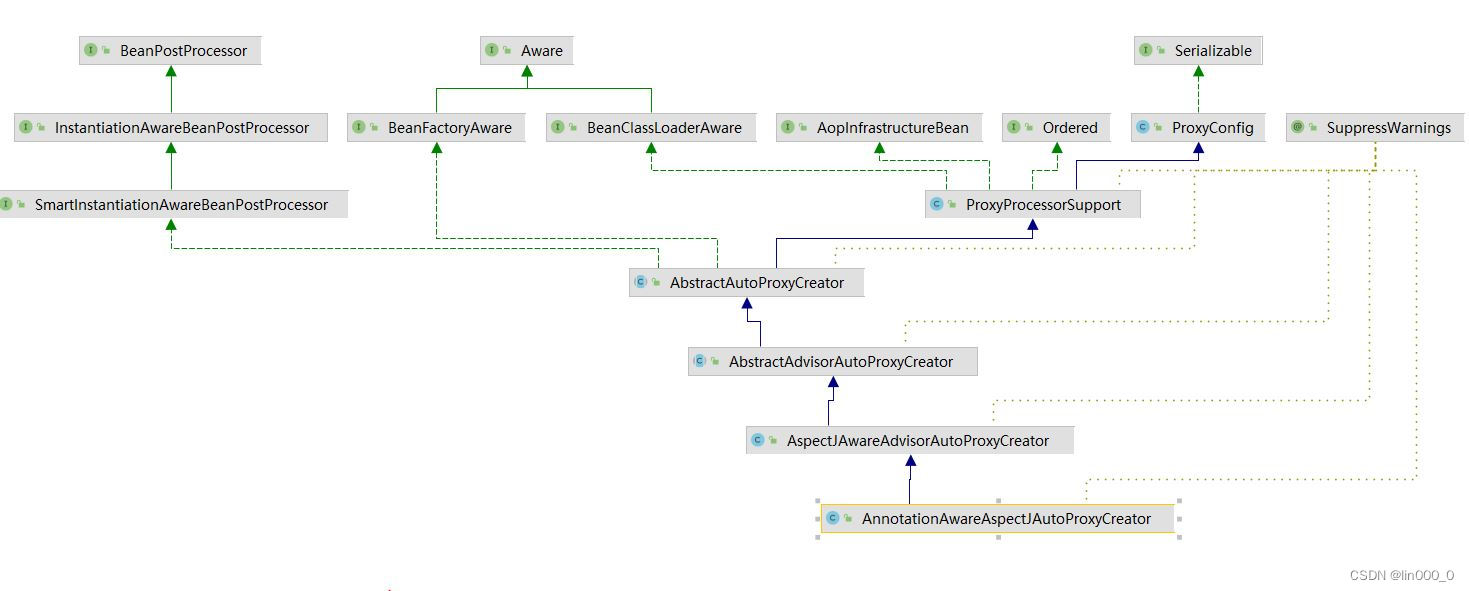
使用Flink的SQL Gateway迁移Hive SQL任务
前言
我们有数万个离线任务,主要还是默认的DataPhin调度CDP集群的Hive On Tez这种低成本任务,当然也有PySpark、打Jar包的Spark和打Jar包的Flink任务这种高成本的任务【Java和Scala都有】。毕竟SQL上手门槛极低,是个人都能写几下并且跑起来,还可以很容易看到run成功的数据长得像不像。其实HQL任务的性能并不会好到哪里去,主要是SQL Boy便宜,无脑堆人天就可以线性提升开发速度。DataPhin的底层基本可以确认就是beeline -f包了一层,而它本身作为二级队列,并不是真正意义上的网关。
我们之前做大数据基础平台时,也有为数据中台租户部署Kyuubi这个网关组件。
Apache Kyuubi:https://kyuubi.apache.org/

这货现在发育的灰常好:

已经不局限于一个霸占Yarn的资源锁定一个Session ID,然后提交Spark任务了。。。这货现在还可以支持Flink和Hudi。。。湖仓一体就需要这货。
燃鹅,新版Flink1.16.0新增了一个和Kyuubi、Spark、Tez抢饭碗的重磅功能:SQL Gateway:

众所周知,Flink的SQL和标准Hive SQL不太一样,新版Flink主动向Hive的dialect看齐:

从而提高了堆HQL的兼容性。官方号称可以97%的HQL任务无需修改直接迁移到Flink!!!还是比较唬人的。
常规的Spark SQL:https://lizhiyong.blog.csdn.net/article/details/120064874
只是让Spark去读Hive9083端口MetaStore的元数据,SQL解析AST、CBO优化和Task执行都是Spark的Catalyst负责。
Hive On Tez【或者MR、Spark】:https://lizhiyong.blog.csdn.net/article/details/123436630
这种方式只是Hive把解析完的任务提交给不同的计算引擎去具体运算。但是很少有听说过Hive On Flink【虽然翻Hive的源码好像可以去实现它】。
所以本文重点就是这个Hive On Flink。用流批一体的运算引擎去跑批也是个有趣的事情。有生之年有望看到Flink一统江湖了。。。
Hive On Flink原理
新增的支持
Hive任务能使用Flink来跑,Flink当然是做了很多支持:

Hive的MetaStore在大数据领域的地位相当于K8S在云原生容器编排领域的地位,或者Alluxio在云原生存算分离架构统一存储层的地位,都是事实上的标准了。能解析Hive的Metastore就可以管理Hadoop集群绝大多数的Hive表了。。。当然Hudi的一些表、Flink的一些SQL流式表也可能被管控到。
而支持Hive的UDF,天然就拥有了Hive的那几百个系统函数:https://lizhiyong.blog.csdn.net/article/details/127501392
当然就可以减少很多写UDF的平台组件二开攻城狮或者部分资深SQL Boy的工作量。UDF函数们是公司的资产,轻易不可以弃用的。

作为一个运算引擎,在Source端和Sink端都支持流式和批式操作Hive表,毫不意外。还可以自动小文件合并,有点像Hudi的Merge On Read这种写多读少的模式了。
SQL解析
在SQL Boy们眼里最重要的SQL,其实在Java和C#种也就是个普通的String字符串,走JDBC传参或者ADO.NET,如果是开发个AD Hoc即席查询平台,单从功能角度,其实都不需要关心租户们传的select语句的具体内容。但是执行引擎必须能把SQL字符串给解析成具体的执行计划或者底层任务。

Flink1.16.0使用了这么一个可插拔的插件,将HQL解析为Logical Plan逻辑计划。后续的ROB、CBO优化生成Physical Plan物理计划,还有转换为Flink最终的Job Graph都是与普通的Blink执行套路一致。
效果

可以满足大部分应用场景了。

命令行和API、运行时、底层资源调度,都可以实现一致,运维起来应该要方便不少。
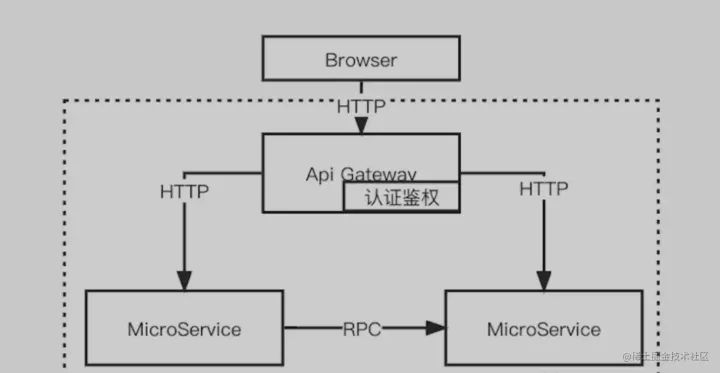
Gateway

Flink自带了Flink SQL Gateway,显而易见的好处是平台和组件二开人员不需要去自己写Gateway去Dispatch分发任务了,甚至二级调度都可以省了。。。

本身后端就可以多租户了。。。还可以支持多种Cluster,K8S和Yarn或者Docker的Standalone混合云考虑一下???
前端支持Rest和Hive Server2,对Java开发人员和SQL Boy们都很友好。
HS2Endpoint

有点区别:

优势

尤其是处理异构数据源:

优势很明显。做联邦查询的改动也只是需要+个Catalog。
Demo
FFA2022的罗宇侠&方盛凯两位大佬带来个Demo,展示了Flink如何使用Hive和Flink的dialect分别按流式和批式跑任务。
为了方便查看,笔者手动敲出来了:
流式
建表:
--创建目标表
create table if not exists dwd_category_by_day(
`i_category` string,
`cate_sales` double,
`cayehory_day_order_cnt` bigint
)
partitioned by (
`year` bigint,
`day` bigint
)
TBLPROPERTIES(
'sink.partition-commit.policy.kind'='metastore,success-file'
)
;
--创建源表
set table.sql-dialect=default;
create table if not exists s_dwd_store_sales(
`ss_item_sk` bigint,
`i_brand` string,
`i_class` string,
`i_category` string,
`ss_sales_price` double,
`d_date` date,
`d_timestamp` as cast(d_date as timestamp(3)),
watermark for `d_timestamp` as `d_timestamp`
) with (
'connector'='kafka',
'topic'='dwd_store_sales',
'properties.bootstrap.servers'='192.168.88.101:9092,192.168.88.102:9092,192.168.88.103:9092',
'properties.group.id'='FFA',
'key.fields'='ss_item_sk',
'scan.startup_mode'='earlist-offset',
'key.format'='json',
)
;
根据Demo的建表DDL,可以看出按照Hive语法建表时,Flink需要设置表的属性。
而使用传统Flink的语法建流式表时,反倒需要手动指定dialect。说明默认的dialect其实是:
set table.sql-dialect=hive;
每日类销量以及订单数统计:
set table.sql-dialect=default;
set execution.runtime-mode=streaming;
set table.cml-sync=false;--异步提交作业
--开启检查点
set execution.checkpointing.interval=30s;
insert into dwd_category_by_day
select
i_category,
sum(ss_sales_price) as month_sales,
count(1) as order_cnt,
year(window_start) as `year`,
dayofyear(window_start) as `day`
from TABLE(
TUMBLE(
TABLE s_dwd_store_sales,DESCRIPTOR(d_timestamp),INTERVAL '1' DAY
)
)
group by
window_start,
window_end,
i_category
;
流式的SQL需要设置滑动的时间窗口,貌似没啥子毛病。
销量最佳Top3:
set table.sql_dialect=default;
select
i_category,
categoru_day_order_cnt,
rownum
from(
select
i_category,
categoru_day_order_cnt,
row_number() over (order by categoru_day_order_cnt desc) as rownum
from
dwd_category_by_day
)
where
rownum<=3
;
Flink的SQL不用像Hive的SQL那样每个子查询都要起别名【Spark SQL也不用】,太棒了!!!
可以看到流式的SQL任务,开发成本肯定比Java和Scala写DataStreaming算子低!!!利好SQL Boy。
批式
desc tpcds_bin_orc_2.dwd_store_sales;
这个表2位大佬已经灌过数据,根据表结构,笔者大概知道大概也是长这样:
create table if not exists tpcds_bin_orc_2.dwd_store_sales(
`ss_item_sk` bigint,
`i_brand` string,
`i_class` string,
`i_category` string,
`ss_sales_price` double
)
partitioned by (
`d_date` date
)
;
每日大类销量以及订单数统计:
insert overwrite dwd_category_by_day
select
i_category,
sum(ss_sales_price) as month_sales,
count(1) as order_cnt,
year(d_date) as `year`,
datediff(d_date,concat(year(d_date)-1,'-12-31'))
from
tpcds_bin_orc_2.dwd_store_sales
group by
year(d_date),
datediff(d_date,concat(year(d_date)-1,'-12-31')),
i_category
;
销量最佳Top3:
select
i_category,
categoru_day_order_cnt,
rownum
from(
select
i_category,
categoru_day_order_cnt,
row_number() over (order by categoru_day_order_cnt desc) as rownum
from
dwd_category_by_day
)
where
rownum<=3
;
可以看到批式的SQL任务由于数据不会在运算时发生变化,不用考虑各种事件时间和水位线还有滑动时间窗口,直接替换即可,更简单!!!
宣传的97%HQL任务可以不加改动,直接迁移到Flink,还算有希望的。不过底层做了什么惊天地泣鬼神的大事,对于只会写业务脚本的SQL Boy们来说,也无关痛痒。
Github参考资料
Flink sql Gateway有个Github地址:https://github.com/ververica/flink-sql-gateway
作者Ververica:https://www.ververica.com/

它就是Flink的公司。
Github的这个Flink sql Gateway貌似很久没有更新了。。。但是它毕竟只是与BE交互的FE,还是可以参考。
启动Gateway
./bin/sql-gateway.sh -h
The following options are available:
-d,--defaults <default configuration file> The properties with which every new session is initialized.
Properties might be overwritten by session properties.
-h,--help Show the help message with descriptions of all options.
-j,--jar <JAR file> A JAR file to be imported into the session.
The file might contain user-defined classes needed for
statements such as functions, the execution of table sources,
or sinks. Can be used multiple times.
-l,--library <JAR directory> A JAR file directory with which every new session is initialized.
The files might contain user-defined classes needed for
the execution of statements such as functions,
table sources, or sinks. Can be used multiple times.
-p,--port <service port> The port to which the REST client connects to.
下Flink集群有这个角标。
典型的yaml
默认的配置文件:
# Define server properties.
server:
bind-address: 127.0.0.1 # optional: The address that the gateway binds itself (127.0.0.1 by default)
address: 127.0.0.1 # optional: The address that should be used by clients to connect to the gateway (127.0.0.1 by default)
port: 8083 # optional: The port that the client connects to (8083 by default)
jvm_args: "-Xmx2018m -Xms1024m" # optional: The JVM args for SQL gateway process
# Define session properties.
session:
idle-timeout: 1d # optional: Session will be closed when it's not accessed for this duration, which can be disabled by setting to zero. The minimum unit is in milliseconds. (1d by default)
check-interval: 1h # optional: The check interval for session idle timeout, which can be disabled by setting to zero. The minimum unit is in milliseconds. (1h by default)
max-count: 1000000 # optional: Max count of active sessions, which can be disabled by setting to zero. (1000000 by default)
# Define tables here such as sources, sinks, views, or temporal tables.
tables:
- name: MyTableSource
type: source-table
update-mode: append
connector:
type: filesystem
path: "/path/to/something.csv"
format:
type: csv
fields:
- name: MyField1
type: INT
- name: MyField2
type: VARCHAR
line-delimiter: "\n"
comment-prefix: "#"
schema:
- name: MyField1
type: INT
- name: MyField2
type: VARCHAR
- name: MyCustomView
type: view
query: "SELECT MyField2 FROM MyTableSource"
# Define user-defined functions here.
functions:
- name: myUDF
from: class
class: foo.bar.AggregateUDF
constructor:
- 7.6
- false
# Define available catalogs
catalogs:
- name: catalog_1
type: hive
property-version: 1
hive-conf-dir: ...
- name: catalog_2
type: hive
property-version: 1
default-database: mydb2
hive-conf-dir: ...
hive-version: 1.2.1
# Properties that change the fundamental execution behavior of a table program.
execution:
parallelism: 1 # optional: Flink's parallelism (1 by default)
max-parallelism: 16 # optional: Flink's maximum parallelism (128 by default)
current-catalog: catalog_1 # optional: name of the current catalog of the session ('default_catalog' by default)
current-database: mydb1 # optional: name of the current database of the current catalog
# (default database of the current catalog by default)
# Configuration options for adjusting and tuning table programs.
# A full list of options and their default values can be found
# on the dedicated "Configuration" page.
configuration:
table.optimizer.join-reorder-enabled: true
table.exec.spill-compression.enabled: true
table.exec.spill-compression.block-size: 128kb
# Properties that describe the cluster to which table programs are submitted to.
deployment:
response-timeout: 5000
支持的语法
| statement | comment |
|---|---|
| SHOW CATALOGS | List all registered catalogs |
| SHOW DATABASES | List all databases in the current catalog |
| SHOW TABLES | List all tables and views in the current database of the current catalog |
| SHOW VIEWS | List all views in the current database of the current catalog |
| SHOW FUNCTIONS | List all functions |
| SHOW MODULES | List all modules |
| USE CATALOG catalog_name | Set a catalog with given name as the current catalog |
| USE database_name | Set a database with given name as the current database of the current catalog |
| CREATE TABLE table_name … | Create a table with a DDL statement |
| DROP TABLE table_name | Drop a table with given name |
| ALTER TABLE table_name | Alter a table with given name |
| CREATE DATABASE database_name … | Create a database in current catalog with given name |
| DROP DATABASE database_name … | Drop a database with given name |
| ALTER DATABASE database_name … | Alter a database with given name |
| CREATE VIEW view_name AS … | Add a view in current session with SELECT statement |
| DROP VIEW view_name … | Drop a table with given name |
| SET xx=yy | Set given key’s session property to the specific value |
| SET | List all session’s properties |
| RESET ALL | Reset all session’s properties set by SET command |
| DESCRIBE table_name | Show the schema of a table |
| EXPLAIN PLAN FOR … | Show string-based explanation about AST and execution plan of the given statement |
| SELECT … | Submit a Flink SELECT SQL job |
| INSERT INTO … | Submit a Flink INSERT INTO SQL job |
| INSERT OVERWRITE … | Submit a Flink INSERT OVERWRITE SQL job |
功能还算齐全。
Beeline
beeline> !connect jdbc:flink://localhost:8083?planner=blink
Beeline version 2.2.0 by Apache Hive
beeline> !connect jdbc:flink://localhost:8083?planner=blink
Connecting to jdbc:flink://localhost:8083?planner=blink
Enter username for jdbc:flink://localhost:8083?planner=blink:
Enter password for jdbc:flink://localhost:8083?planner=blink:
Connected to: Apache Flink (version 1.10.0)
Driver: Flink Driver (version 0.1)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:flink://localhost:8083> CREATE TABLE T(
. . . . . . . . . . . . . . . > a INT,
. . . . . . . . . . . . . . . > b VARCHAR(10)
. . . . . . . . . . . . . . . > ) WITH (
. . . . . . . . . . . . . . . > 'connector.type' = 'filesystem',
. . . . . . . . . . . . . . . > 'connector.path' = 'file:///tmp/T.csv',
. . . . . . . . . . . . . . . > 'format.type' = 'csv',
. . . . . . . . . . . . . . . > 'format.derive-schema' = 'true'
. . . . . . . . . . . . . . . > );
No rows affected (0.158 seconds)
0: jdbc:flink://localhost:8083> INSERT INTO T VALUES (1, 'Hi'), (2, 'Hello');
No rows affected (4.747 seconds)
0: jdbc:flink://localhost:8083> SELECT * FROM T;
+----+--------+--+
| a | b |
+----+--------+--+
| 1 | Hi |
| 2 | Hello |
+----+--------+--+
2 rows selected (0.994 seconds)
0: jdbc:flink://localhost:8083>
这是比较老的语法了,传统的Flink SQL。
JDBC
当然可以使用Java走JDBC调用:
Jar包:https://github.com/ververica/flink-jdbc-driver/releases
Demo:
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class Sample {
public static void main(String[] args) throws Exception {
Connection connection = DriverManager.getConnection("jdbc:flink://localhost:8083?planner=blink");
Statement statement = connection.createStatement();
statement.executeUpdate("CREATE TABLE T(\n" +
" a INT,\n" +
" b VARCHAR(10)\n" +
") WITH (\n" +
" 'connector.type' = 'filesystem',\n" +
" 'connector.path' = 'file:///tmp/T.csv',\n" +
" 'format.type' = 'csv',\n" +
" 'format.derive-schema' = 'true'\n" +
")");
statement.executeUpdate("INSERT INTO T VALUES (1, 'Hi'), (2, 'Hello')");
ResultSet rs = statement.executeQuery("SELECT * FROM T");
while (rs.next()) {
System.out.println(rs.getInt(1) + ", " + rs.getString(2));
}
statement.close();
connection.close();
}
}
传统的Flink SQL就是这么写。。。相当古老了。。。
Shell脚本
启动sql gateway的shell较新版本:
function usage() {
echo "Usage: sql-gateway.sh [start|start-foreground|stop|stop-all] [args]"
echo " commands:"
echo " start - Run a SQL Gateway as a daemon"
echo " start-foreground - Run a SQL Gateway as a console application"
echo " stop - Stop the SQL Gateway daemon"
echo " stop-all - Stop all the SQL Gateway daemons"
echo " -h | --help - Show this help message"
}
################################################################################
# Adopted from "flink" bash script
################################################################################
target="$0"
# For the case, the executable has been directly symlinked, figure out
# the correct bin path by following its symlink up to an upper bound.
# Note: we can't use the readlink utility here if we want to be POSIX
# compatible.
iteration=0
while [ -L "$target" ]; do
if [ "$iteration" -gt 100 ]; then
echo "Cannot resolve path: You have a cyclic symlink in $target."
break
fi
ls=`ls -ld -- "$target"`
target=`expr "$ls" : '.* -> \(.*\)$'`
iteration=$((iteration + 1))
done
# Convert relative path to absolute path
bin=`dirname "$target"`
# get flink config
. "$bin"/config.sh
if [ "$FLINK_IDENT_STRING" = "" ]; then
FLINK_IDENT_STRING="$USER"
fi
################################################################################
# SQL gateway specific logic
################################################################################
ENTRYPOINT=sql-gateway
if [[ "$1" = *--help ]] || [[ "$1" = *-h ]]; then
usage
exit 0
fi
STARTSTOP=$1
if [ -z "$STARTSTOP" ]; then
STARTSTOP="start"
fi
if [[ $STARTSTOP != "start" ]] && [[ $STARTSTOP != "start-foreground" ]] && [[ $STARTSTOP != "stop" ]] && [[ $STARTSTOP != "stop-all" ]]; then
usage
exit 1
fi
# ./sql-gateway.sh start --help, print the message to the console
if [[ "$STARTSTOP" = start* ]] && ( [[ "$*" = *--help* ]] || [[ "$*" = *-h* ]] ); then
FLINK_TM_CLASSPATH=`constructFlinkClassPath`
SQL_GATEWAY_CLASSPATH=`findSqlGatewayJar`
"$JAVA_RUN" -classpath "`manglePathList "$FLINK_TM_CLASSPATH:$SQL_GATEWAY_CLASSPATH:$INTERNAL_HADOOP_CLASSPATHS"`" org.apache.flink.table.gateway.SqlGateway "${@:2}"
exit 0
fi
if [[ $STARTSTOP == "start-foreground" ]]; then
exec "${FLINK_BIN_DIR}"/flink-console.sh $ENTRYPOINT "${@:2}"
else
"${FLINK_BIN_DIR}"/flink-daemon.sh $STARTSTOP $ENTRYPOINT "${@:2}"
fi
有空的时候,可以从这个脚本找到入口类【org.apache.flink.table.gateway.SqlGateway】继续钻研。。。
Java类
入口类就是这个:
package org.apache.flink.table.gateway;
import org.apache.flink.annotation.VisibleForTesting;
import org.apache.flink.configuration.ConfigurationUtils;
import org.apache.flink.runtime.util.EnvironmentInformation;
import org.apache.flink.runtime.util.JvmShutdownSafeguard;
import org.apache.flink.runtime.util.SignalHandler;
import org.apache.flink.table.gateway.api.SqlGatewayService;
import org.apache.flink.table.gateway.api.endpoint.SqlGatewayEndpoint;
import org.apache.flink.table.gateway.api.endpoint.SqlGatewayEndpointFactoryUtils;
import org.apache.flink.table.gateway.api.utils.SqlGatewayException;
import org.apache.flink.table.gateway.cli.SqlGatewayOptions;
import org.apache.flink.table.gateway.cli.SqlGatewayOptionsParser;
import org.apache.flink.table.gateway.service.SqlGatewayServiceImpl;
import org.apache.flink.table.gateway.service.context.DefaultContext;
import org.apache.flink.table.gateway.service.session.SessionManager;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.PrintStream;
import java.util.ArrayList;
import java.util.List;
import java.util.Properties;
import java.util.concurrent.CountDownLatch;
/** Main entry point for the SQL Gateway. */
public class SqlGateway {
private static final Logger LOG = LoggerFactory.getLogger(SqlGateway.class);
private final List<SqlGatewayEndpoint> endpoints;
private final Properties dynamicConfig;
private final CountDownLatch latch;
private SessionManager sessionManager;
public SqlGateway(Properties dynamicConfig) {
this.endpoints = new ArrayList<>();
this.dynamicConfig = dynamicConfig;
this.latch = new CountDownLatch(1);
}
public void start() throws Exception {
DefaultContext context =
DefaultContext.load(ConfigurationUtils.createConfiguration(dynamicConfig));
sessionManager = new SessionManager(context);
sessionManager.start();
SqlGatewayService sqlGatewayService = new SqlGatewayServiceImpl(sessionManager);
try {
endpoints.addAll(
SqlGatewayEndpointFactoryUtils.createSqlGatewayEndpoint(
sqlGatewayService, context.getFlinkConfig()));
for (SqlGatewayEndpoint endpoint : endpoints) {
endpoint.start();
}
} catch (Throwable t) {
LOG.error("Failed to start the endpoints.", t);
throw new SqlGatewayException("Failed to start the endpoints.", t);
}
}
public void stop() {
for (SqlGatewayEndpoint endpoint : endpoints) {
stopEndpointSilently(endpoint);
}
if (sessionManager != null) {
sessionManager.stop();
}
latch.countDown();
}
public void waitUntilStop() throws Exception {
latch.await();
}
public static void main(String[] args) {
startSqlGateway(System.out, args);
}
@VisibleForTesting
static void startSqlGateway(PrintStream stream, String[] args) {
SqlGatewayOptions cliOptions = SqlGatewayOptionsParser.parseSqlGatewayOptions(args);
if (cliOptions.isPrintHelp()) {
SqlGatewayOptionsParser.printHelpSqlGateway(stream);
return;
}
// startup checks and logging
EnvironmentInformation.logEnvironmentInfo(LOG, "SqlGateway", args);
SignalHandler.register(LOG);
JvmShutdownSafeguard.installAsShutdownHook(LOG);
SqlGateway gateway = new SqlGateway(cliOptions.getDynamicConfigs());
try {
Runtime.getRuntime().addShutdownHook(new ShutdownThread(gateway));
gateway.start();
gateway.waitUntilStop();
} catch (Throwable t) {
// User uses ctrl + c to cancel the Gateway manually
if (t instanceof InterruptedException) {
LOG.info("Caught " + t.getClass().getSimpleName() + ". Shutting down.");
return;
}
// make space in terminal
stream.println();
stream.println();
if (t instanceof SqlGatewayException) {
// Exception that the gateway can not handle.
throw (SqlGatewayException) t;
} else {
LOG.error(
"SqlGateway must stop. Unexpected exception. This is a bug. Please consider filing an issue.",
t);
throw new SqlGatewayException(
"Unexpected exception. This is a bug. Please consider filing an issue.", t);
}
} finally {
gateway.stop();
}
}
private void stopEndpointSilently(SqlGatewayEndpoint endpoint) {
try {
endpoint.stop();
} catch (Exception e) {
LOG.error("Failed to stop the endpoint. Ignore.", e);
}
}
// --------------------------------------------------------------------------------------------
private static class ShutdownThread extends Thread {
private final SqlGateway gateway;
public ShutdownThread(SqlGateway gateway) {
this.gateway = gateway;
}
@Override
public void run() {
// Shutdown the gateway
System.out.println("\nShutting down the Flink SqlGateway...");
LOG.info("Shutting down the Flink SqlGateway...");
try {
gateway.stop();
} catch (Exception e) {
LOG.error("Failed to shut down the Flink SqlGateway: " + e.getMessage(), e);
System.out.println("Failed to shut down the Flink SqlGateway: " + e.getMessage());
}
LOG.info("Flink SqlGateway has been shutdown.");
System.out.println("Flink SqlGateway has been shutdown.");
}
}
}
等有空的时候再研究。
总结
从Flink1.16.0开始,就可以使用Hive On Flink了,SQL Boy们可以依旧只关心所谓的逻辑,只写几个Join。平台和组件二开人员可以尝试下Sql Gateway的方式了,简化Spark的Thrift Server和Hive的Hive Server2,架构简单化以后,组件运维起来应该要容易一些。暂时不清楚Hive On Flink和Spark SQL在性能上的区别,还停留在Flink1.13老版本不敢吃螃蟹的公司也可以先吃瓜,看看大白鼠们直接上生产环境的稳定性来判断这个特性是否GA。
Apache Flink的公众号还是有不少干货,灰常适合笔者这样的学徒工观摩和学习。
Flink1.16.0基本是2022年的收官之作了。
转载请注明出处:https://lizhiyong.blog.csdn.net/article/details/128195438