读入xlsx文件,将datetime.time转为minute的格式,并将新数据存入csv文件
- 任务概要
- 思路设计
- 代码实现
- 导入相关库
- 时间转换函数
- 算法内核
- csv文件结果
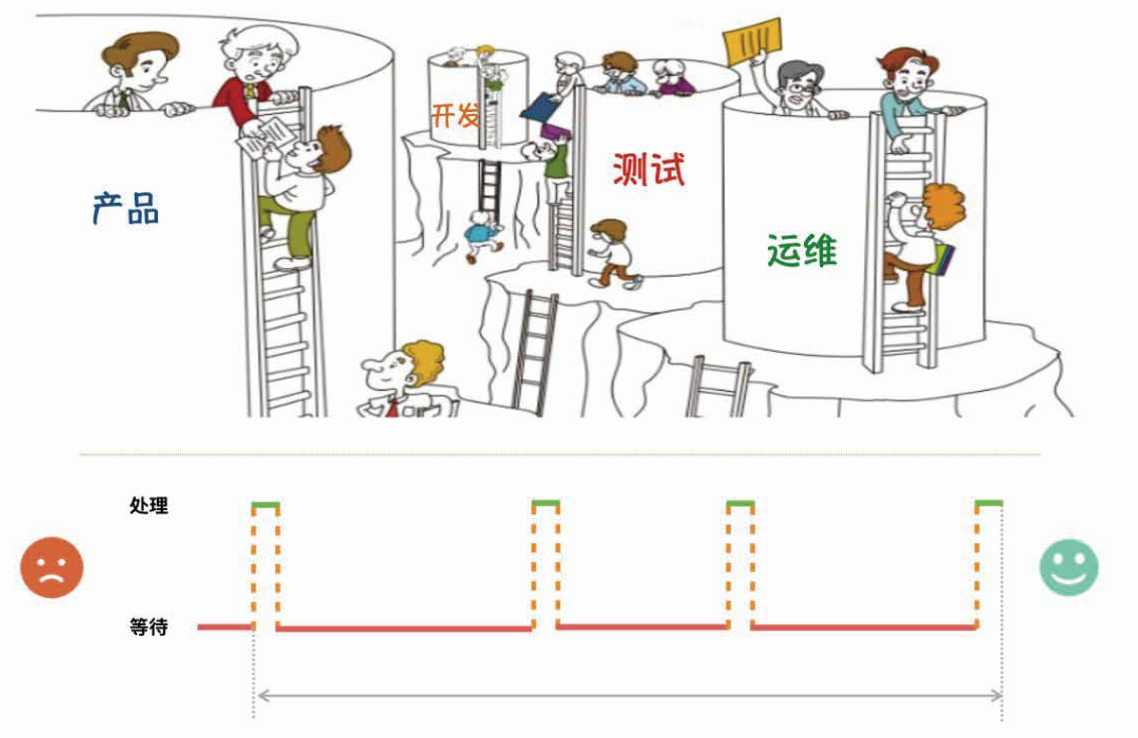
接到一个需求,师兄在做稳定性测试时,时间显示格式为<class ‘datetime.time’>,数据用来画图显示很奇怪,不符合常规的科学形式,希望能将这个时间转为minute显示。
任务概要

思路设计
【思路设计】
- 首先读入xlsx文件(df=pd.read_excel()),读取某列数据,将数据转为列表形式(df.values);
- 接着遍历列表中的数据(for循环),调用函数将datetime转换为min,存入新列表;
- 将列表数据整合,重新写入csc文件保存。
代码实现
导入相关库
import os
import csv
import pandas as pd
时间转换函数
def time_convert(datetime):
'''
本函数实现将12:29:37<class 'datetime.time'>转为显示min的格式;
思路:实际就是将时、分、秒、微秒均转换为min格式
datetime:输入一个datetime数据,如12:29:37<class 'datetime.time'>
输出:以分钟表示的数值
'''
hour=datetime.hour
minute=datetime.minute
second=datetime.second
microsecond=datetime.microsecond
total_time=hour*60+minute+second/60+microsecond/1000000/60
return total_time
算法内核
def read_and_rewrite_data(file_dir,file_name,data_first_row=8):
'''
本函数实现读入一份xlsx文件,将某列的datatime数据转为显示为分的格式,并将新数据写入csv文件
思路设计:
首先读入xlsx文件,读取某列数据,将数据转为列表形式;
接着遍历列表中的数据,调用函数将datetime转换为min,存入新列表;
将列表数据整合,重新写入csc文件保存。
file_dir:文件所处文件夹路径,如:r'D:\some files of others'
file_name:xlsx文件名字,包括后缀,如:'test.xlsx'
data_first_row:第一行数据对应的序号-2
'''
#文件路径
#file_dir=r'D:\some files of others'
#file_name='test.xlsx'
file_path=os.path.join(file_dir,file_name)
#读入第1,2,3,4,5列数据
df = pd.read_excel(file_path,usecols=[0,1,2,3,4])#读入前五列数据
data=df.values#将数据转为np.array
#创建新列表存储前五列数据
data_time=[]
data_convert_time=[]
column2=[]
column3=[]
column4=[]
column5=[]
data_list=data.tolist()#将数据转为list
data_final_row=len(data_list)-3 #最后一行数据对应序号
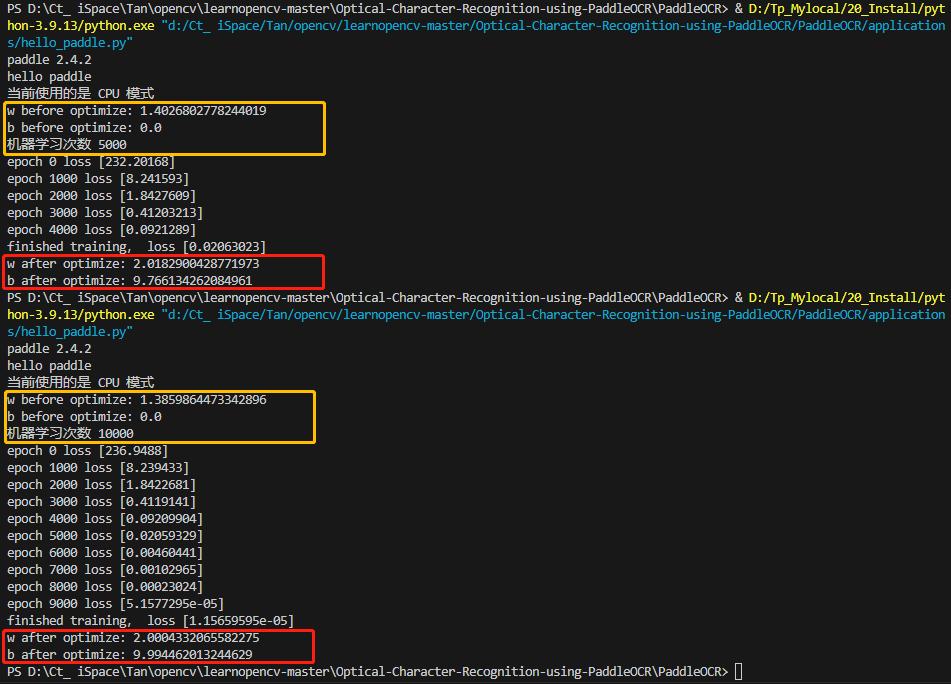
print('data_final_row',data_final_row)
print(data_list[data_final_row][0],type(data_list[data_final_row][0]))
#获取数据的标题
header_name=data_list[data_first_row-1]
print('header_name',header_name)
for i in data_list:
if data_list.index(i)>=data_first_row and data_list.index(i)<=data_final_row:#从第九行开始读入数据,进行转化
#print(i)
#print(i[0].minute)
data_time.append(i[0])#第一列数据
total_time=time_convert(i[0])
data_convert_time.append(total_time)##将数据中的时间转为min显示
column2.append(i[1])#第二列数据
column3.append(i[2])#第三列数据
column4.append(i[3])#第四列数据
column5.append(i[4])#第五列数据
#将转化好的数据重新写入新的文件
rows = zip(data_time,data_convert_time,column2,column3,column4,column5)
with open(os.path.join(file_dir,file_name+'_convert_time'+'.csv'), "w", newline='') as f:
writer = csv.writer(f)
# 标题行写入
header = [header_name[0],header_name[0]+'_convert(min)', header_name[1],header_name[2],header_name[3],header_name[4]]
# 数据写入
csvrow1 = []
csvrow2 = []
csvrow3 = []
csvrow4 = []
csvrow5 = []
csvrow6 = []
csvrow1.extend(header_name[0])
csvrow2.extend(header_name[0]+'_convert(min)')
csvrow3.extend(header_name[1])
csvrow4.extend(header_name[2])
csvrow5.extend(header_name[3])
csvrow6.extend(header_name[4])
writer.writerow(header)
writer.writerows(rows)
print('文件已转换完毕')
运行部分:
file_dir=r'D:\some files of others' #文件所处文件夹路径
file_name='test.xlsx' #xlsx文件名字
data_first_row=8 #第一行数据对应的序号-2,比如在excel文件中,第一行数据对应的序号是10,那么这里就写8
read_and_rewrite_data(file_dir,file_name,data_first_row=8)
输出结果:
data_final_row 89962
12:29:37 <class 'datetime.time'>
header_name ['Time', 'TProc', 'TInt', 'TBox', 'TAvg']
文件已转换完毕
csv文件结果
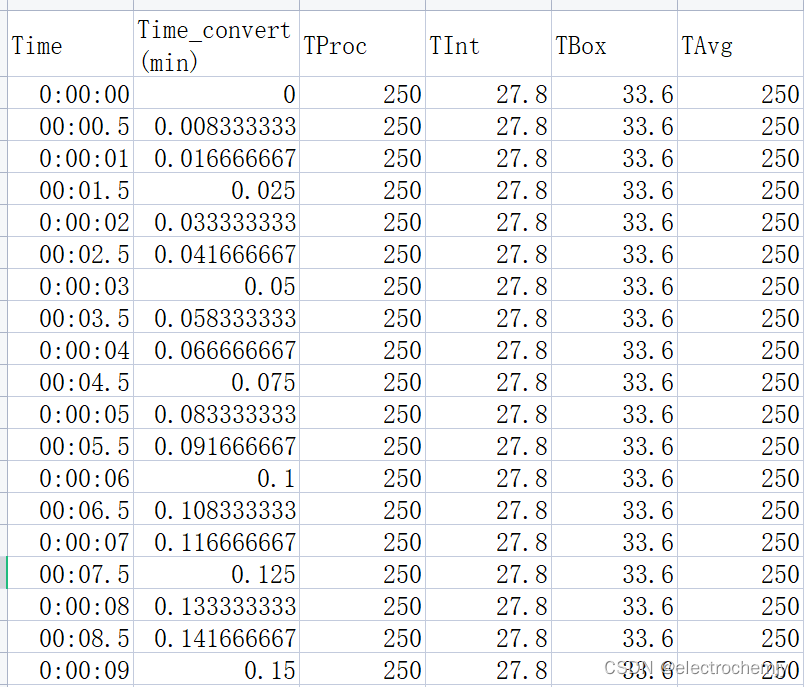
如果需要批量转换文件,在算法内核外部加一个for循环即可。