这篇示例向你介绍普通程序跟机器学习程序的区别,并带着你用百度飞桨框架,实现第一个机器学习程序,并初步认识机器学习。
作为一名开发者,你最熟悉的开始学习一门编程语言,或者一个深度学习框架的方式,可能是通过一个 hello world 程序。
学习飞桨也可以这样,这篇小示例教程将会通过一个非常简单的示例来向你展示如何开始使用飞桨。
一、普通程序跟机器学习程序的逻辑区别
机器学习程序跟通常的程序最大的不同是,通常的程序是在给定输入的情况下,通过告诉计算机处理数据的规则,然后得到处理后的结果。而机器学习程序则是在并不知道这些规则的情况下,让机器来从数据当中学习出来规则。
作为热身,先来看看通常的程序所做的事情。
现在面临这样一个任务:
乘坐出租车的时候,会有一个10元的起步价,只要上车就需要收取。出租车每行驶1公里,需要再支付每公里2元的行驶费用。当一个乘客坐完出租车之后,车上的计价器需要算出来该乘客需要支付的乘车费用。
如果用 python 来实现该功能,会如下所示:
def calculate_fee(distance_travelled):
return 10 + 2 * distance_travelled
for x in [1.0, 3.0, 5.0, 9.0, 10.0, 20.0]:
print(calculate_fee(x))

接下来,把问题稍微变换一下,现在知道乘客每次乘坐出租车的公里数,也知道乘客每次下车的时候支付给出租车司机的总费用。但是并不知道乘车的起步价,以及每公里行驶费用是多少。 也就是说,除了乘坐总公里数据和总费用,我们并不知道总费的计算规则,我们希望让机器从这些数据当中学习出来计算总费用的规则。
更具体的,想要让机器学习程序通过数据学习出来下面的公式当中的参数 w 和参数 b(这是一个非常简单的示例,所以 w 和 b 都是浮点数,随着对深度学习了解的深入,你将会知道 w 和 b 通常情况下会是矩阵和向量)。这样,当下次乘车的时候,知道了行驶里程 distance_travelled 的时候,就可以估算出来用户的总费用 total_fee 了。
total_fee = w * distance_travelled + b
接下来,看看用飞桨如何实现这个 hello, world 级别的机器学习程序。
二、导入飞桨
为了能够使用飞桨,需要先用 python 的 import 语句导入飞桨 paddle。同时,为了能够更好的对数组进行计算和处理,还需要导入 numpy。
如果你是在本机实验,且还没有安装飞桨,请先参考:PaddleOCR #使用PaddleOCR进行光学字符识别 - OCR飞桨实验
亦或者参考官网安装 PaddlePaddle 2.3.0: 开始使用_飞桨-源于产业实践的开源深度学习平台
import paddle
print("paddle " + paddle.__version__)
结果参考:
paddle 2.4.2
三、数据准备
在这个机器学习任务中,已经知道了乘客的行驶里程 distance_travelled,和对应的这些乘客的总费用 total_fee。
通常情况下,在机器学习任务中,像 distance_travelled 这样的输入值,一般被称为x(或者特征feature),像 total_fee 这样的输出值,一般被称为y(或者标签label)。
可以用 paddle.to_tensor 把示例数据转换为 paddle 的 Tensor 数据。
x_data = paddle.to_tensor([[1.], [3.0], [5.0], [9.0], [10.0], [20.0]])
y_data = paddle.to_tensor([[12.], [16.0], [20.0], [28.0], [30.0], [50.0]])
四、用飞桨定义模型的计算
使用飞桨定义模型的计算的过程,本质上,是用python,通过飞桨提供的API,来告诉飞桨计算规则的过程。回顾一下,想要通过飞桨用机器学习方法,从数据当中学习出来如下公式当中的 w 和 b。这样在未来,给定 x 时就可以估算出来 y 值(估算出来的 y 记为 y_predict)
# 如上述 total_fee = w * distance_travelled + b
y_predict = w * x + b
将会用飞桨的线性变换层:paddle.nn.Linear 来实现这个计算过程,这个公式里的变量 x, y, w, b, y_predict,对应着飞桨里面的 Tensor 概念。
稍微补充一下:在这里的示例中,根据经验,已经事先知道了 distance_travelled 和 total_fee 之间是线性的关系,而在更实际的问题当中,x 和 y 的关系通常是非线性的,因此也就需要使用更多类型,也更复杂的神经网络。(比如,BMI指数跟你的身高就不是线性关系,一张图片里的某个像素值跟这个图片是猫还是狗也不是线性关系。)
# y_predict = w * x + b
# 使用 PaddlePaddle 框架定义一个线性层(linear layer)的代码。
# in_features=1 表示输入特征的维度为 1。这意味着线性层的输入是一个大小为 1 的张量或向量。
# out_features=1 表示输出特征的维度为 1。这意味着线性层的输出也是一个大小为 1 的张量或向量。
# 这样的线性层通常被用于将输入特征映射到输出特征,其中每个输入特征与权重相乘,并加上偏置,从而得到输出特征。在这种情况下,输入特征和输出特征的维度都是 1,因此可以看作是一个简单的一对一映射关系。
# 这个线性层可以用于构建神经网络的一部分,或者作为独立的模型使用。
linear = paddle.nn.Linear(in_features=1, out_features=1)
五、准备好运行飞桨
机器(计算机)在一开始的时候会随便猜 w 和 b,先看看机器猜的怎么样。

你应该可以看到,这时候的 w 是一个随机值,b 是 0.0,这是飞桨的初始化策略,也是这个领域常用的初始化策略。(如果你愿意,也可以采用其他的初始化的方式,今后你也会看到,选择不同的初始化策略也是对于做好深度学习任务来说很重要的一点)。
六、告诉飞桨怎么样学习
前面定义好了神经网络(尽管是一个最简单的神经网络),还需要告诉飞桨,怎么样去学习,从而能得到参数 w 和 b。
这个过程简单的来陈述一下,你应该就会大致明白了(尽管背后的理论和知识还需要逐步的去学习)。在机器学习/深度学习当中,机器(计算机)在最开始的时候,得到参数 w 和 b 的方式是随便猜一下,用这种随便猜测得到的参数值,去进行计算(预测)的时候,得到的 y_predict,跟实际的 y 值一定是有差距的。接下来,机器会根据这个差距来调整 w 和 b,随着这样的逐步的调整,w 和 b 会越来越正确,y_predict 跟 y 之间的差距也会越来越小,从而最终能得到好用的 w 和 b。这个过程就是机器学习的过程。
用更加技术的语言来说,衡量差距的函数(一个公式)就是损失函数,用来调整参数的方法就是优化算法。
在本示例当中,用最简单的均方误差(mean square error)作为损失函数(paddle.nn.MSELoss);和最常见的优化算法SGD(stocastic gradient descent)作为优化算法(传给paddle.optimizer.SGD的参数learning_rate,你可以理解为控制每次调整的步子大小的参数)。
# 最简单的均方误差(mean square error)作为损失函数(paddle.nn.MSELoss)
mse_loss = paddle.nn.MSELoss()
# 最常见的优化算法SGD(stocastic gradient descent)作为优化算法,参数learning_rate,可以理解为控制每次调整的步子大小
sgd_optimizer = paddle.optimizer.SGD(learning_rate=0.001, parameters = linear.parameters())
七、运行优化算法
接下来,让飞桨运行一下这个优化算法,这会是一个前面介绍过的逐步调整参数的过程,你应该可以看到 loss 值(衡量 y 和 y_predict 的差距的 loss )在不断的降低。
# 总的迭代次数(控制机器学习次数)
total_epoch = 5000
for i in range(total_epoch):
# 使用线性模型进行预测
y_predict = linear(x_data)
# 计算预测值与真实值之间的均方误差损失
loss = mse_loss(y_predict, y_data)
# 反向传播,计算梯度
loss.backward()
# 使用随机梯度下降优化器更新模型参数
sgd_optimizer.step()
# 清除梯度信息,为下一次迭代做准备
sgd_optimizer.clear_grad()
if i % 1000 == 0:
# 打印每隔1000次迭代的损失值
print("epoch {} loss {}".format(i, loss.numpy()))
# 打印训练完成后的损失值
print("finished training, loss {}".format(loss.numpy()))

八、机器学习出来的参数
经过了这样的对参数 w 和 b 的调整(学习),再通过下面的程序,来看看现在的参数变成了多少。完整代码如下:
import paddle
paddle.set_device("cpu")
print("paddle " + paddle.__version__)
print("hello paddle")
import paddle
if paddle.is_compiled_with_cuda():
print("当前使用的是 GPU 模式")
else:
print("当前使用的是 CPU 模式")
x_data = paddle.to_tensor([[1.], [3.0], [5.0], [9.0], [10.0], [20.0]])
y_data = paddle.to_tensor([[12.], [16.0], [20.0], [28.0], [30.0], [50.0]])
# y_predict = w * x + b
# 使用 PaddlePaddle 框架定义一个线性层(linear layer)的代码。
# in_features=1 表示输入特征的维度为 1。这意味着线性层的输入是一个大小为 1 的张量或向量。
# out_features=1 表示输出特征的维度为 1。这意味着线性层的输出也是一个大小为 1 的张量或向量。
# 这样的线性层通常被用于将输入特征映射到输出特征,其中每个输入特征与权重相乘,并加上偏置,从而得到输出特征。在这种情况下,输入特征和输出特征的维度都是 1,因此可以看作是一个简单的一对一映射关系。
# 这个线性层可以用于构建神经网络的一部分,或者作为独立的模型使用。
linear = paddle.nn.Linear(in_features=1, out_features=1)
# 获取优化后的线性模型的权重,并转换为标量值
w_before_opt = linear.weight.numpy().item()
# 获取优化后的线性模型的偏置,并转换为标量值
b_before_opt = linear.bias.numpy().item()
print("w before optimize: {}".format(w_before_opt))
print("b before optimize: {}".format(b_before_opt))
# 最简单的均方误差(mean square error)作为损失函数(paddle.nn.MSELoss)
mse_loss = paddle.nn.MSELoss()
# 最常见的优化算法SGD(stocastic gradient descent)作为优化算法,参数learning_rate,可以理解为控制每次调整的步子大小
sgd_optimizer = paddle.optimizer.SGD(learning_rate=0.001, parameters = linear.parameters())
# 总的迭代次数(控制机器学习次数)
total_epoch = 5000
print("机器学习次数 {}".format(total_epoch))
for i in range(total_epoch):
# 使用线性模型进行预测
y_predict = linear(x_data)
# 计算预测值与真实值之间的均方误差损失
loss = mse_loss(y_predict, y_data)
# 反向传播,计算梯度
loss.backward()
# 使用随机梯度下降优化器更新模型参数
sgd_optimizer.step()
# 清除梯度信息,为下一次迭代做准备
sgd_optimizer.clear_grad()
if i % 1000 == 0:
# 打印每隔1000次迭代的损失值
print("epoch {} loss {}".format(i, loss.numpy()))
# 打印训练完成后的损失值
print("finished training, loss {}".format(loss.numpy()))
# 获取优化后的线性模型的权重,并转换为标量值
w_after_opt = linear.weight.numpy().item()
# 获取优化后的线性模型的偏置,并转换为标量值
b_after_opt = linear.bias.numpy().item()
print("w after optimize: {}".format(w_after_opt))
print("b after optimize: {}".format(b_after_opt))
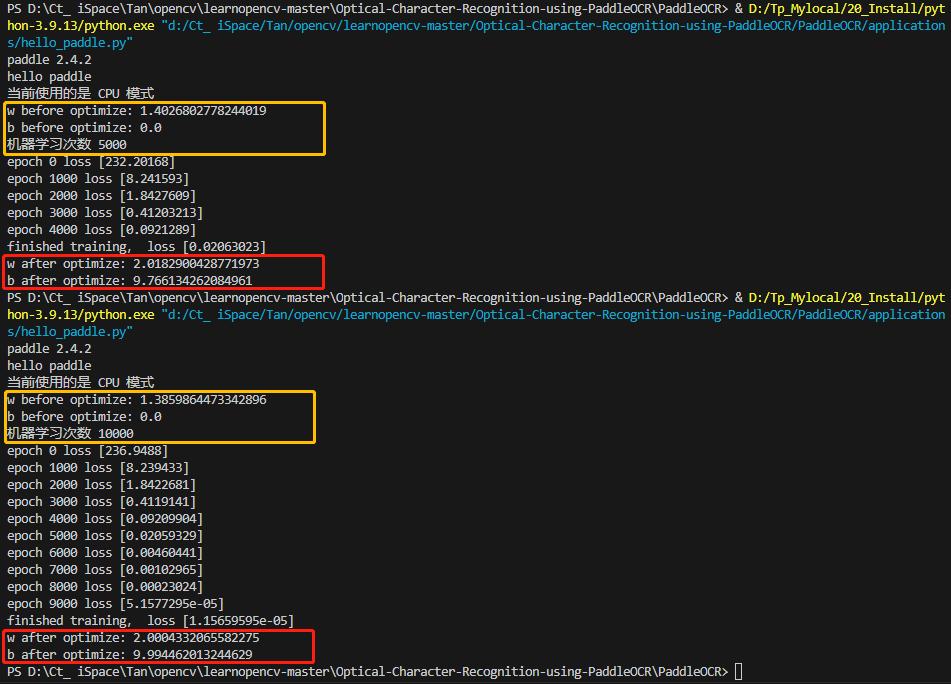
你应该会发现 w 变成了很接近 2.0 的一个值,b 变成了接近 10.0 的一个值。虽然并不是正好的 2 和 10,但却是从数据当中学习出来的还不错的模型的参数,可以在未来的时候,用从这批数据当中学习到的参数来预估了。(如果你愿意,也可以通过控制机器学习次数,让机器多学习一段时间,从而得到更加接近 2.0 和 10.0 的参数值。)
九、hello paddle
通过这个小示例,希望你已经初步了解了飞桨,能在接下来随着对飞桨的更多学习,来解决实际遇到的问题。
十、参考文档
paddlepaddle官方文档:hello paddle: 从普通程序走向机器学习程序-使用文档-PaddlePaddle深度学习平台
paddlepaddle官方文档:开始使用_飞桨-源于产业实践的开源深度学习平台
系列攻略:
PaddleOCR #使用PaddleOCR进行光学字符识别 - OCR飞桨实验
PaddleOCR #使用PaddleOCR进行光学字符识别 - OCR模型对比