该文章主要为完成实训任务,详细实现过程及结果见【http://t.csdn.cn/Twpwe】
文章目录
- 1. 任务目标
- 2. 实现思路
- 3. 准备工作
- 3.1 启动HDFS服务
- 3.2 启动Spark服务
- 3.3 在本地创建成绩文件
- 3.4 将成绩文件上传到HDFS
- 4. 完成任务
- 4.1 在Spark Shell里完成任务
- 4.1.1 读取成绩文件,生成RDD
- 4.1.2 定义二元组成绩列表
- 4.1.3 利用RDD填充二元组成绩列表
- 4.1.4 基于二元组成绩列表创建RDD
- 4.1.5 对rdd按键归约得到rdd1,计算总分
- 4.1.6 将rdd1映射成rdd2,计算总分与平均分
- 4.2 在IntelliJ IDEA里完成任务
- 4.2.1 打开RDD项目
- 4.2.2 创建计算总分平均分对象
- 4.2.3 运行程序,查看结果
1. 任务目标
- 针对成绩表,计算每个学生总分和平均分

2. 实现思路
- 读取成绩文件,生成lines;定义二元组成绩列表;遍历lines,填充二元组成绩列表;基于二元组成绩列表创建RDD;对rdd按键归约得到rdd1,计算总分;将rdd1映射成rdd2,计算总分与平均分。
3. 准备工作
3.1 启动HDFS服务
- 执行命令:
start-dfs.sh
3.2 启动Spark服务
- 执行命令:
start-all.sh
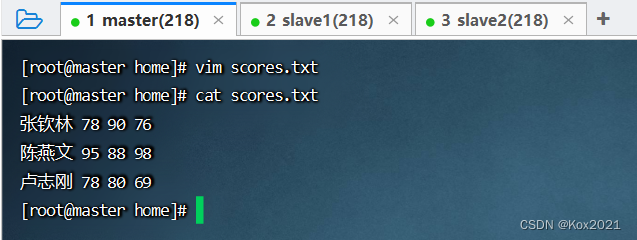
3.3 在本地创建成绩文件
- 在
/home里创建scores.txt文件
3.4 将成绩文件上传到HDFS
- 在HDFS上创建
/scoresumavg/input目录,将成绩文件上传至该目录
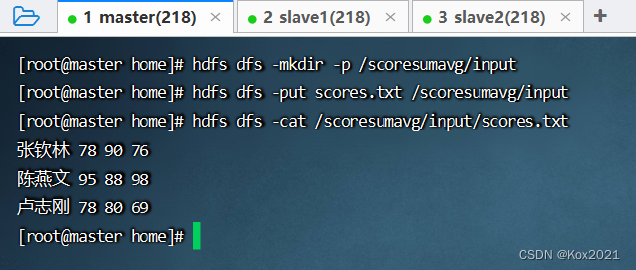
4. 完成任务
4.1 在Spark Shell里完成任务
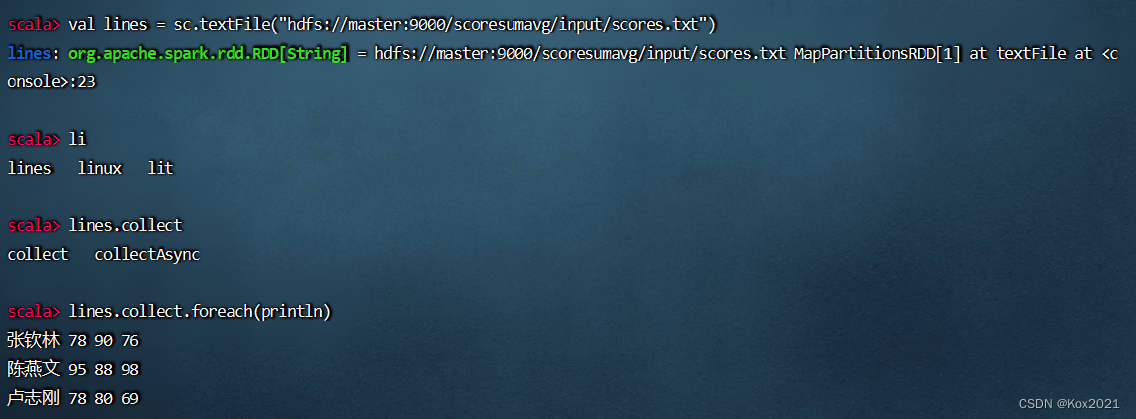
4.1.1 读取成绩文件,生成RDD
- 执行命令:
val lines = sc.textFile("hdfs://master:9000/scoresumavg/input/scores.txt")
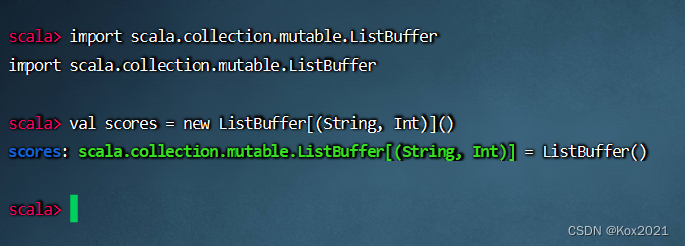
4.1.2 定义二元组成绩列表
- 执行命令:
import scala.collection.mutable.ListBuffer - 执行命令:
val scores = new ListBuffer[(String, Int)]()
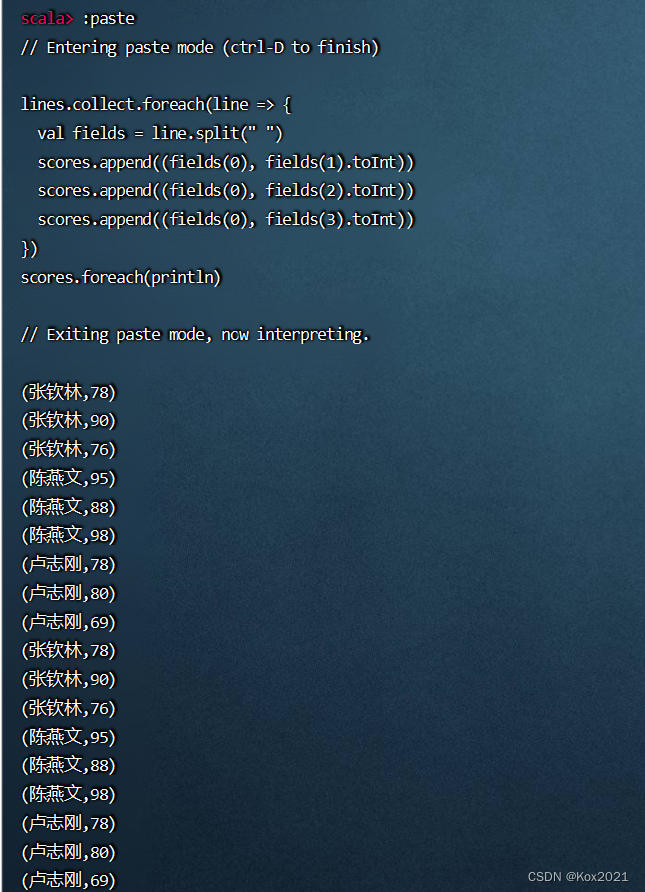
4.1.3 利用RDD填充二元组成绩列表
lines.collect.foreach(line => {
val fields = line.split(" ")
scores.append((fields(0), fields(1).toInt))
scores.append((fields(0), fields(2).toInt))
scores.append((fields(0), fields(3).toInt))
})
scores.foreach(println)
4.1.4 基于二元组成绩列表创建RDD
- 执行命令:
val rdd = sc.makeRDD(scores);
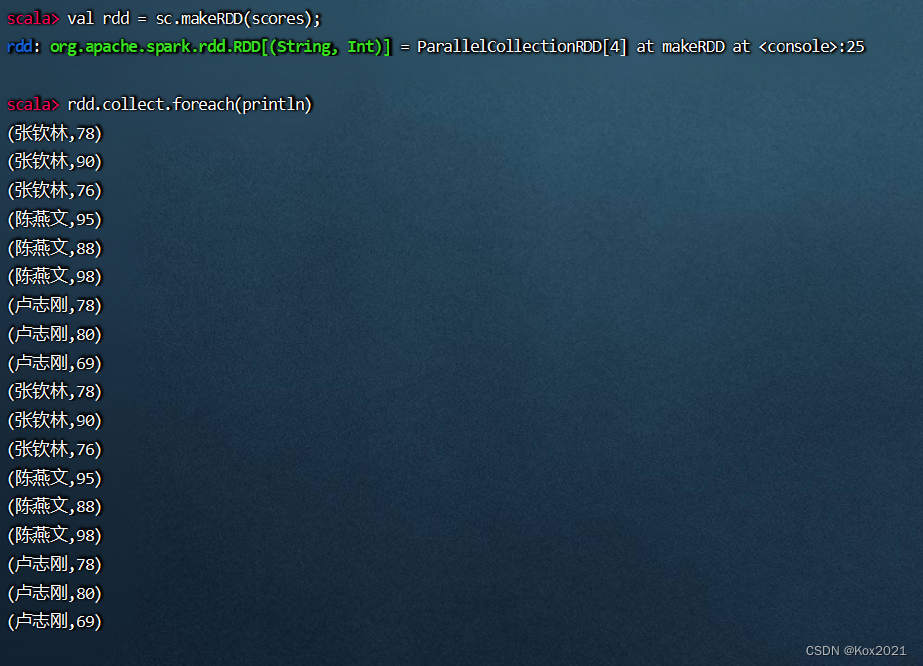
4.1.5 对rdd按键归约得到rdd1,计算总分
- 执行命令:
val rdd1 = rdd.reduceByKey(_ + _)
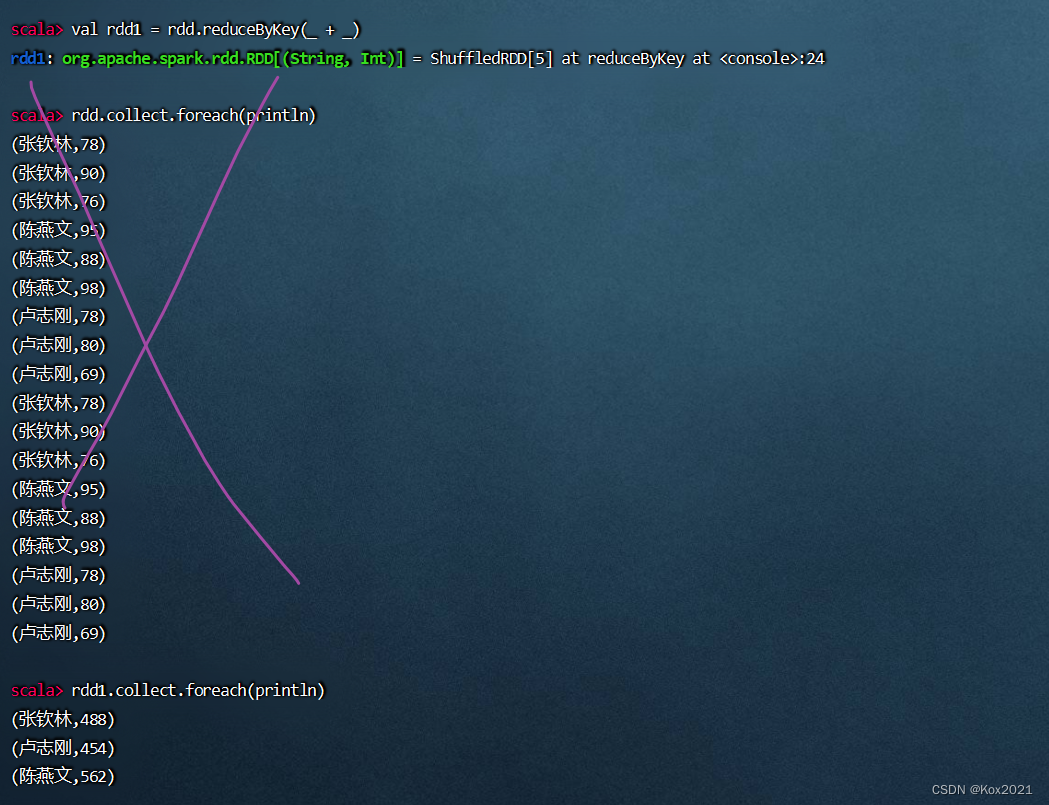
4.1.6 将rdd1映射成rdd2,计算总分与平均分
- 执行命令:
val rdd2 = rdd1.map(score => (score._1, score._2, (score._2 / 3.0).formatted("%.2f")))
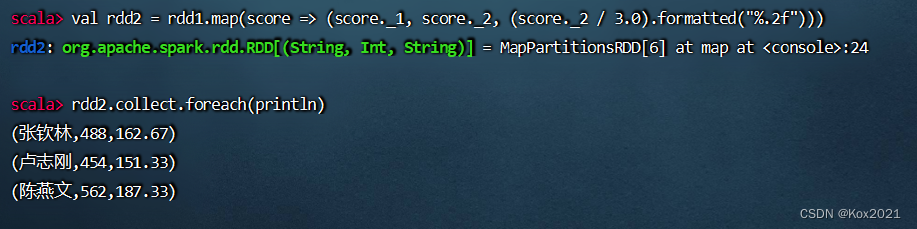
4.2 在IntelliJ IDEA里完成任务
4.2.1 打开RDD项目
SparkRDDDemo
4.2.2 创建计算总分平均分对象
- 在
cn.kox.rdd包里创建day07子包,然后在子包里创建CalculateSumAvg对象
package cn.kox.rdd.day07
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable.ListBuffer
/**
* @ClassName: CalculateSumAvg
* @Author: Kox
* @Data: 2023/6/15
* @Sketch:
*/
object CalculateSumAvg {
def main(args: Array[String]): Unit = {
// 创建Spark配置对象
val conf = new SparkConf()
.setAppName("CalculateSumAvg ") // 设置应用名称
.setMaster("local[*]") // 设置主节点位置(本地调试)
// 基于Spark配置对象创建Spark容器
val sc = new SparkContext(conf)
// 读取成绩文件,生成RDD
val lines = sc.textFile("hdfs://master:9000/scoresumavg/input/scores.txt")
// 定义二元组成绩列表
val scores = new ListBuffer[(String, Int)]()
// 利用RDD填充二元组成绩列表
lines.collect.foreach(line => {
val fields = line.split(" ")
scores.append((fields(0), fields(1).toInt))
scores.append((fields(0), fields(2).toInt))
scores.append((fields(0), fields(3).toInt))
})
// 基于二元组成绩列表创建RDD
val rdd = sc.makeRDD(scores);
// 对rdd按键归约得到rdd1,计算总分
val rdd1 = rdd.reduceByKey(_ + _)
// 将rdd1映射成rdd2,计算总分与平均分
val rdd2 = rdd1.map(score => (score._1, score._2, (score._2 / 3.0).formatted("%.2f")))
// 在控制台输出rdd2的内容
rdd2.collect.foreach(println)
// 将rdd2内容保存到HDFS指定位置
rdd2.saveAsTextFile("hdfs://master:9000/scoresumavg/output")
// 关闭Spark容器
sc.stop()
}
}
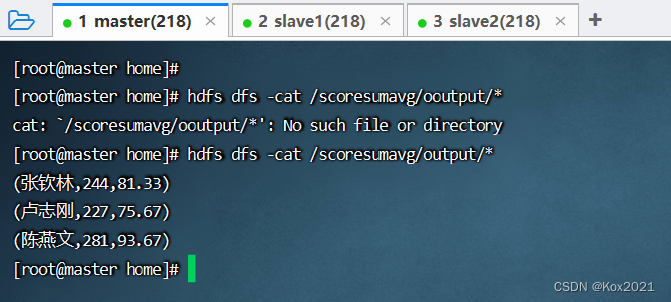
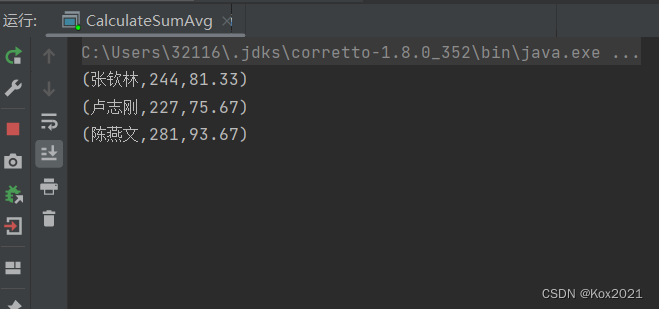
4.2.3 运行程序,查看结果
- 运行程序
CalculateSumAvg,控制台结果
- 查看HDFS的结果文件