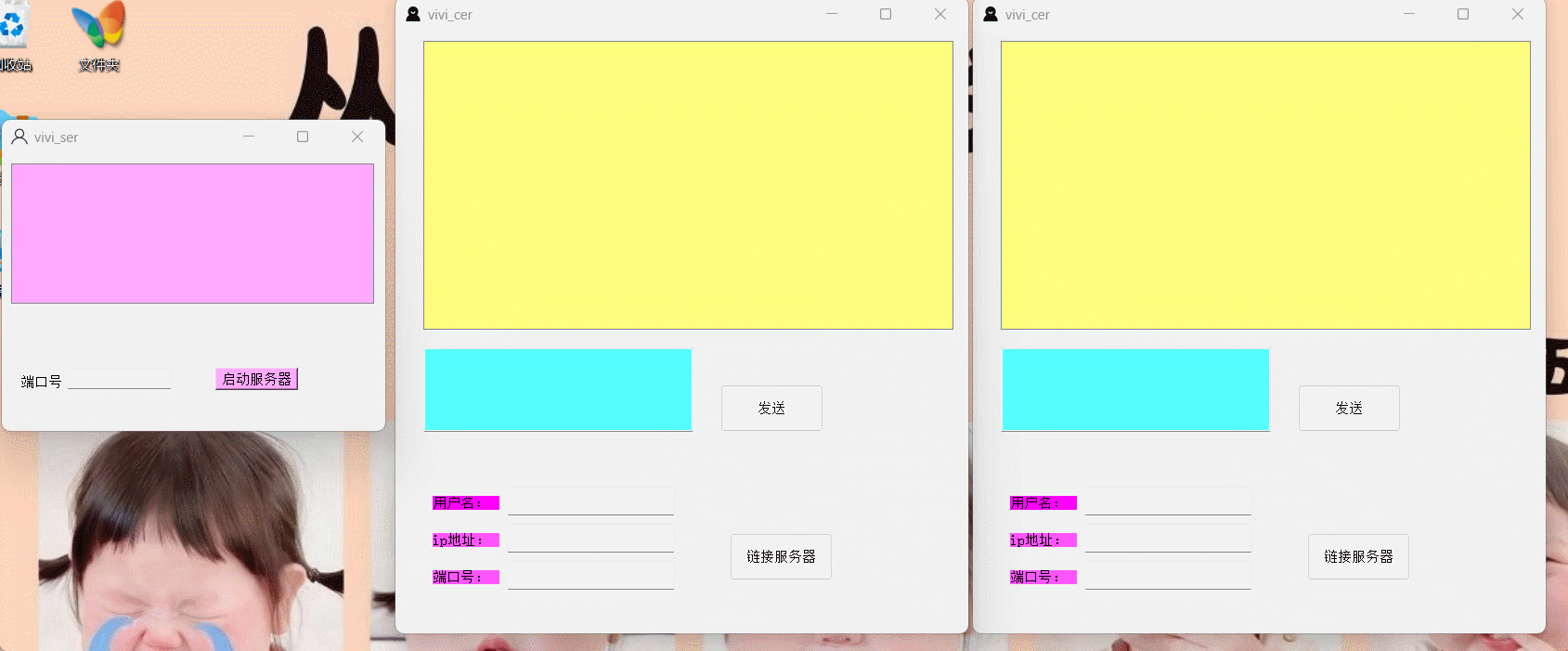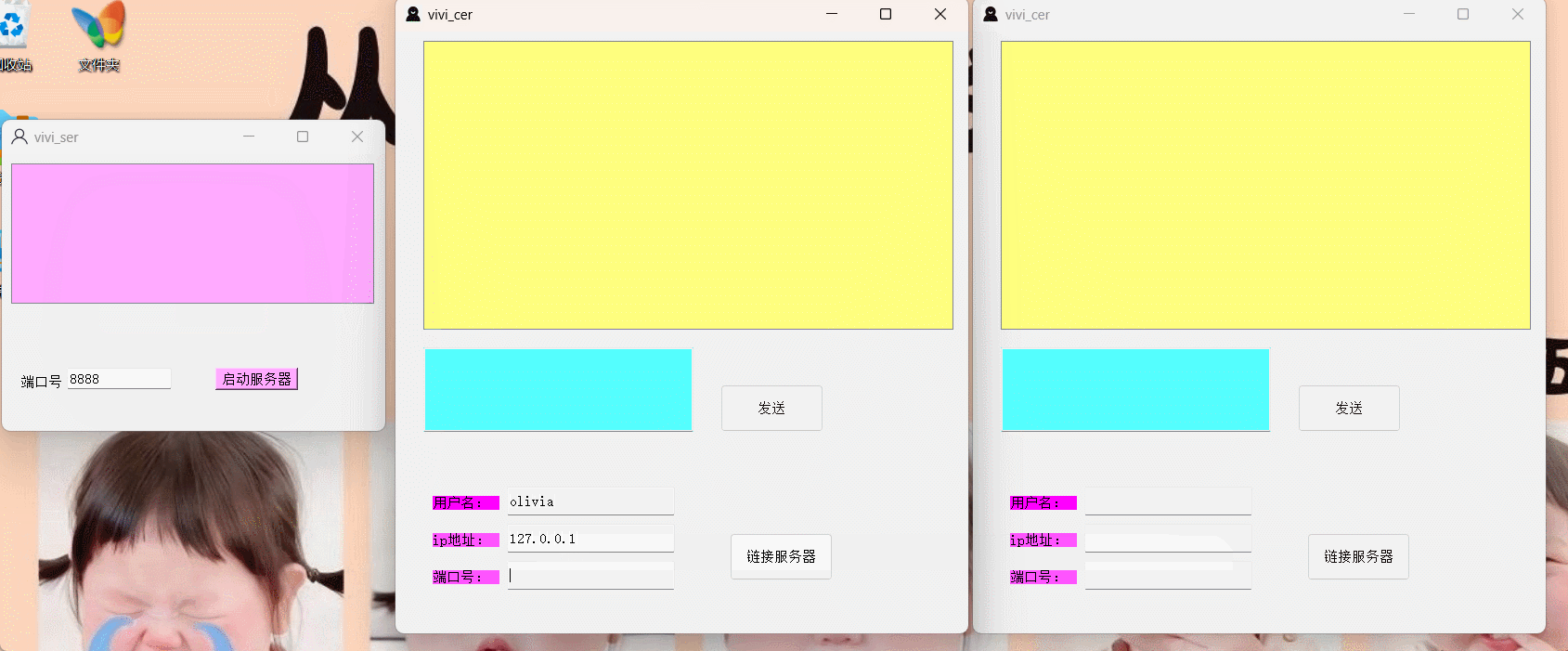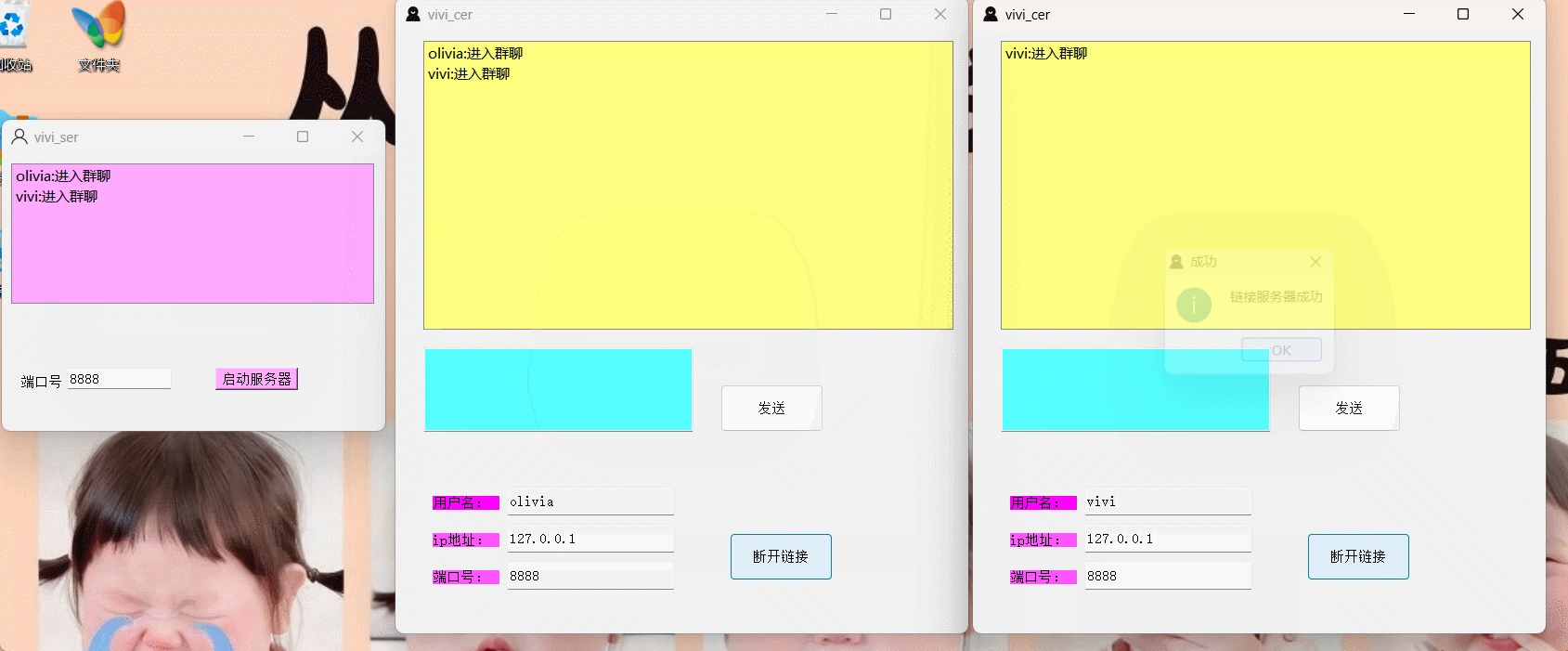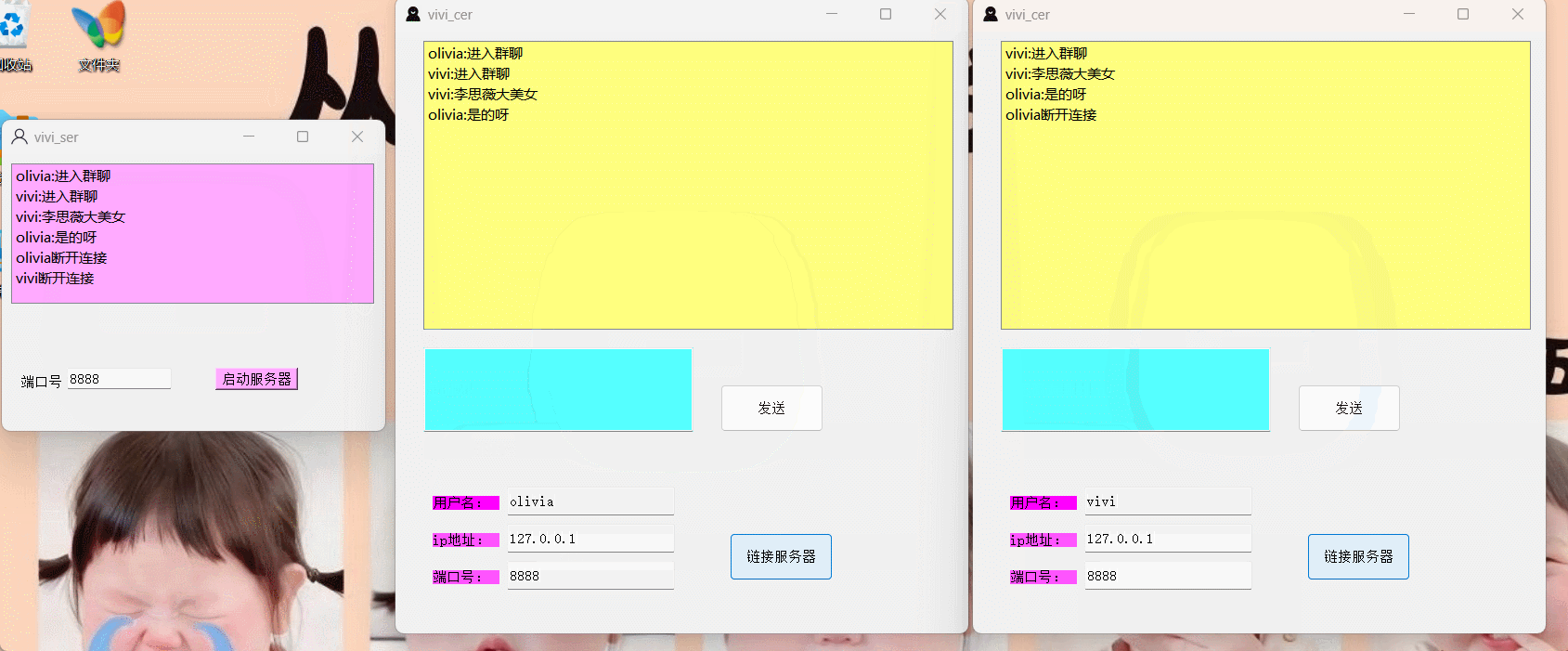
一、Bytecode的存储结构
LuaJIT的Bytecode位宽为32位,在parse阶段用结构体BCInsLine表示,ins表示32位长的字字节码指令,line表示字节码的行号:
typedef struct BCInsLine {
BCIns ins; /* Bytecode instruction. */
BCLine line; /* Line number for this bytecode. */
} BCInsLine;
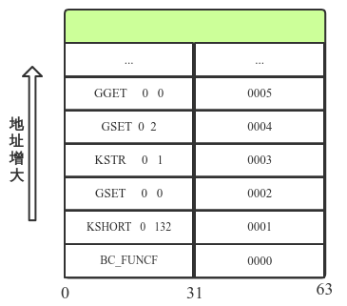
parse阶段的Bytecode指令集被存放在一个BCInsLine类型的动态数组中,数组的初始size为LJ_MIN_VECSZ(值为8),每次动态扩充的大小为 size<< 1,最大扩充至LJ_MAX_BCINS(1<<26),FuncState->bcbase指向数组的基地址。以下字节码parse时在内存中的存放方式如图所示:
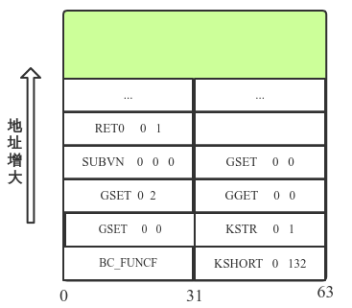
0001 KSHORT 0 132
0002 GSET 0 0 ; "a"
0003 KSTR 0 1 ; "qwer"
0004 GSET 0 2 ; "str"
0005 GGET 0 0 ; "a"
0006 SUBVN 0 0 0 ; 1
0007 GSET 0 0 ; "a"
0008 RET0 0 1
等parse完成后,会将Bytecode指令集重新组织,放入一个BCIns 类型的数组中,数组的size为Bytecode指令的条数,基地址为(BCIns *)((char *)pt + sizeof(GCproto)),这一过程在lj_parse.c:fs_finish函数中。这么做的原因也就是让取指令操作具有一个良好的空间局部性,下图为Bytecode指令集放入重新组织的数组中的结构:
假设现在有两个寄存器PC和INS,PC存放Bytecode的地址,INS存放PC对应地址处的Bytecode值,则可以利用以下伪代码对Bytecode访问,其中code_base是存放Bytecode连续内存(数组)的首地址:
mov PC code_base
load INS [PC]
...
// set INS to next bytecode
add PC PC 4
load INS [PC]
...
二、Instruction dispatch table
DynASM会将vm_loongarch64.dasc中的汇编代码在预处理阶段变成二进制机器码,然后再使用内存映射将机器码映射到虚拟内存,等运行时便可以直接运行被映射的二进制代码。在lj_dispatch.h中有一个结构GG_State,定义如下:
typedef struct GG_State {
lua_State L; /* Main thread. */
global_State g; /* Global state. */
#if LJ_HASJIT
jit_State J; /* JIT state. */
HotCount hotcount[HOTCOUNT_SIZE]; /* Hot counters. */
#endif
ASMFunction dispatch[GG_LEN_DISP]; /* Instruction dispatch tables. */
BCIns bcff[GG_NUM_ASMFF]; /* Bytecode for ASM fast functions. */
} GG_State;
字段dispatch是一个ASMFunction数组,而ASMFunction是函数指针类型,是Bytecode指令对应的汇编函数。运行时被映射的二进制代码的地址(函数指针),存放在dispatch数组中,且数组的下标为BCOp(定义在lj_bc.h中),存放与其对应的汇编函数指针。如dispatch[BC_POW]中存放函数指针为vm_loongarch64.dasc:BC_POW函数在虚拟内存中的映射地址。
解释器在解释执行Lua原型(GCproto)生成Bytecode指令集时,如Bytecode的存储结构中的指令集。首先从GCfuncL->pc内存地址处中取出第一条Bytecode指令(BC_FUNCF rbase lit),取出该指令的opcode(BC_FUNCF),以opcode为index在dispatch中查找相应的函数指针,再执行相应的函数。等解释执行的逻辑完成,开始让PC指向下一条Bytecode指令,重复同样的过程。