神经网络的代价函数
接下来我会再规定若干符号代表的含义:
L
L
L表示神经网络的总层数
s
i
s_i
si表示的是第i层的神经元数量
如果神经网络处理的是一个二元分类问题,那么他的第L层就只会有一个节点;如果处理的是一个多元分类问题,那么需要分为K类则在第L层会有K个节点
神经网络中使用的代价函数我们之前学过Logistics回归的代价函数的一般形式,其中Logistics回归的代价函数如下:(带有正则化项)
J
(
θ
)
=
−
1
m
[
∑
i
=
1
m
y
(
i
)
l
o
g
h
θ
(
x
(
i
)
)
+
(
1
−
y
(
i
)
)
l
o
g
(
1
−
h
θ
(
x
(
i
)
)
)
]
+
λ
2
m
∑
j
=
1
n
θ
j
2
J(\theta)=-\frac{1}{m} \left [ \sum_{i=1}^{m}y^{(i)}logh_\theta (x^{(i)} )+(1-y^{(i)})log(1-h_\theta (x^{(i)}))\right ]+\frac{\lambda }{2m} \sum_{j=1}^{n}\theta _j^2
J(θ)=−m1[i=1∑my(i)loghθ(x(i))+(1−y(i))log(1−hθ(x(i)))]+2mλj=1∑nθj2
那么神经网络的代价函数为
J
(
θ
)
=
−
1
m
[
∑
i
=
1
m
∑
k
=
1
K
y
k
(
i
)
l
o
g
(
h
θ
(
x
(
i
)
)
)
k
+
(
1
−
y
k
(
i
)
)
l
o
g
(
1
−
(
h
θ
(
x
(
i
)
)
)
k
)
]
+
λ
2
m
∑
l
=
1
L
−
1
∑
i
=
1
s
l
∑
j
=
1
s
l
+
1
(
θ
j
i
(
l
)
)
2
J(\theta)=-\frac{1}{m} \left [ \sum_{i=1}^{m}\sum_{k=1}^{K} y_k^{(i)}log(h_\theta (x^{(i)} ))_k+(1-y_k^{(i)})log(1-(h_\theta (x^{(i)}))_k)\right ] +\frac{\lambda }{2m} \sum_{l=1}^{L-1}\sum_{i=1}^{s_l}\sum_{j=1}^{s_{l+1}} (\theta_{ji}^{(l)})^2
J(θ)=−m1[i=1∑mk=1∑Kyk(i)log(hθ(x(i)))k+(1−yk(i))log(1−(hθ(x(i)))k)]+2mλl=1∑L−1i=1∑slj=1∑sl+1(θji(l))2
我们来分析下神经网络的代价函数,在代价函数中,一般假设函数 h ( x ) h(x) h(x)表示的是神经网络经过拟合后的输出值,而y是样本实际的结果,因为多分类的神经网络中,式子中的y不只是只有一种输出结果,而是有k种输出结果,因此需要计算K个输出单元的和,这就是为什么需要 ∑ k = 1 K \sum_{k=1}^{K} ∑k=1K的原因。
老实说,代价函数这方面我也不太整的明白,我跟的教程并没有给出足够严谨的说明,但是好在实际使用时是直接有函数接口调用的,另外我还会找额外的书籍去补一补这一方面,等着更新吧(挖坑
反向传播算法
单个实例的反向传播
上面我们知道了神经网络的代价函数:这为我们衡量一个神经网络的假设结果是否准确提供了方法。那么如何通过调整参数 θ \theta θ使得代价函数 J ( Θ ) J(\Theta) J(Θ)最小化呢?在神经网络中,我们使用反向传播算法来实现。
这需要计算 J ( Θ ) J(\Theta) J(Θ)和 ∂ ∂ Θ i j ( l ) J ( Θ ) \frac{\partial}{\partial\Theta_{ij}^{(l)}}J(\Theta) ∂Θij(l)∂J(Θ),其中 J ( Θ ) J(\Theta) J(Θ)的计算方法已经在上一节给出了,接下来的内容大部分精力都在讨论如何计算 ∂ ∂ Θ i j ( l ) J ( Θ ) \frac{\partial}{\partial\Theta_{ij}^{(l)}}J(\Theta) ∂Θij(l)∂J(Θ)
先假设只有一个训练实例
(
x
,
y
)
(x,y)
(x,y),试着针对这个实例进行训练,首先我们需要使用之前学的前向传播算法,获得其最终假设函数的结果。
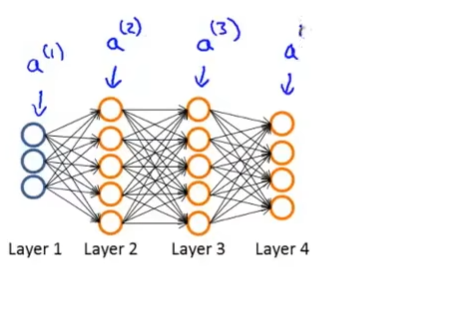
其前向传播的过程如下:
a
(
1
)
=
x
z
(
2
)
=
Θ
(
1
)
a
(
1
)
a
(
2
)
=
g
(
z
(
2
)
)
(
a
d
d
a
0
(
2
)
)
z
(
3
)
=
Θ
(
2
)
a
(
2
)
a
(
3
)
=
g
(
z
(
3
)
)
(
a
d
d
a
0
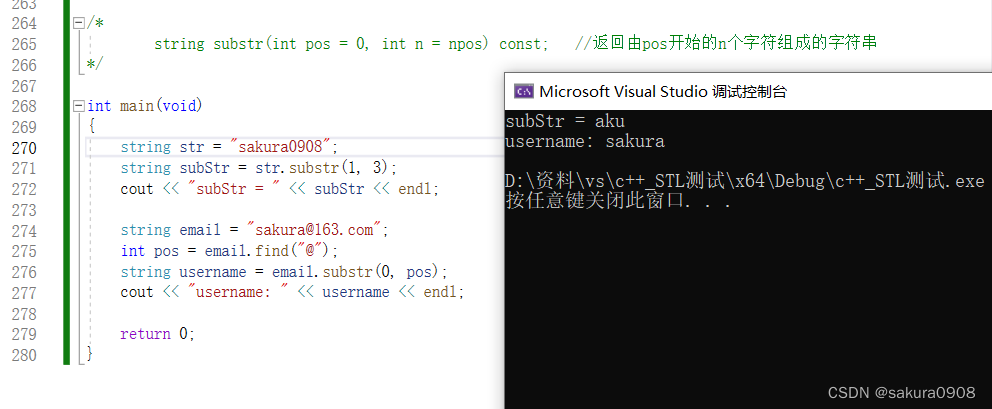
(
3
)
)
z
(
4
)
=
Θ
(
3
)
a
(
3
)
a
(
4
)
=
h
Θ
(
x
)
=
g
(
z
(
4
)
)
a^{(1)}=x\\z^{(2)}=\Theta^{(1)}a^{(1)}\\a^{(2)}=g(z^{(2)})\:(add \:a_0^{(2)})\\z^{(3)}=\Theta^{(2)}a^{(2)}\\a^{(3)}=g(z^{(3)})\:(add \:a_0^{(3)})\\z^{(4)}=\Theta^{(3)}a^{(3)}\\a^{(4)}=h_\Theta(x)=g(z^{(4)})
a(1)=xz(2)=Θ(1)a(1)a(2)=g(z(2))(adda0(2))z(3)=Θ(2)a(2)a(3)=g(z(3))(adda0(3))z(4)=Θ(3)a(3)a(4)=hΘ(x)=g(z(4))
注意:其中
a
(
1
)
a^{(1)}
a(1)是一个向量,其他的亦是,这是一个向量化的前向传播过程
接下来就是采用反向传播的时候了,反向传播实际上是在逐层计算神经网络的各层的假设结果和实际结果的误差。规定 δ j ( l ) \delta_j^{(l)} δj(l)为第l层第j个节点的神经节点的激活值的误差,那么对于上述的例子有: δ j ( 4 ) = a j ( 4 ) − y j \delta_j^{(4)}=a_j^{(4)}-y_j δj(4)=aj(4)−yj,也就是将算法的输出值减去该样例的答案yj。
当然,你也可以使用向量化表达,比如:
δ
(
4
)
=
a
(
4
)
−
y
\delta^{(4)}=a^{(4)}-y
δ(4)=a(4)−y,这个式子里的每一个元素都是一个向量,我们可以按照这种逻辑写出网络中前面几层的误差项
δ
\delta
δ,如下:
δ
(
4
)
=
a
(
4
)
−
y
δ
(
3
)
=
(
Θ
(
3
)
)
T
δ
(
4
)
.
∗
g
′
(
z
(
3
)
)
δ
(
2
)
=
(
Θ
(
2
)
)
T
δ
(
3
)
.
∗
g
′
(
z
(
2
)
)
\delta^{(4)}=a^{(4)}-y\\\delta^{(3)}=(\Theta^{(3)})^T\delta^{(4)}.*g'(z^{(3)})\\\delta^{(2)}=(\Theta^{(2)})^T\delta^{(3)}.*g'(z^{(2)})
δ(4)=a(4)−yδ(3)=(Θ(3))Tδ(4).∗g′(z(3))δ(2)=(Θ(2))Tδ(3).∗g′(z(2))其中
g
′
(
z
(
i
)
)
=
a
(
i
)
.
∗
(
1
−
a
(
i
)
)
g'(z^{(i)})=a^{(i)}.*(1-a^{(i)})
g′(z(i))=a(i).∗(1−a(i)),这是Logistics激活函数的导数。另外误差项
δ
1
\delta_1
δ1是不存在的,因为第一层是输入层,没有误差可言。而通过式子
∂
∂
Θ
i
j
(
l
)
J
(
Θ
)
=
a
j
(
l
)
δ
i
(
l
+
1
)
\frac{\partial}{\partial\Theta_{ij}^{(l)}}J(\Theta)=a_j^{(l)}\delta_i^{(l+1)}
∂Θij(l)∂J(Θ)=aj(l)δi(l+1)我们就可以通过式子和
a
a
a计算出其导数项。(注意的是,现在模型尚未引入正则化的
λ
\lambda
λ项,因为此时考虑正则化会比较复杂,我们后面再完成正则化工作)
多实例反向传播
现在我们试着训练一个拥有多个实例的 ( x ( 1 ) , y ( 1 ) ) , ( x ( 2 ) , y ( 2 ) ) , . . . , ( x ( m ) , y ( m ) ) {(x^{(1)},y^{(1)}),(x^{(2)},y^{(2)}),...,(x^{(m)},y^{(m)})} (x(1),y(1)),(x(2),y(2)),...,(x(m),y(m)),定义一个变量 Δ i j ( l ) = 0 ( f o r a l l l , i , j ) \Delta_{ij}^{(l)}=0\:(for\:all\: l,i,j) Δij(l)=0(foralll,i,j)这个 Δ \Delta Δ表示的是误差,它的用处是用于计算导数 ∂ ∂ Θ i j ( l ) J ( Θ ) \frac{\partial}{\partial\Theta_{ij}^{(l)}}J(\Theta) ∂Θij(l)∂J(Θ),上面单实例中,对于第l层的节点j,只会有一个实例产生误差项目 δ \delta δ,因此 Δ = δ \Delta=\delta Δ=δ,但是在有m个实例的多实例反向传播中,一个节点会经过m个实例的验证,因此 Δ \Delta Δ等于m个单实例误差 δ \delta δ的和。
令i从1遍历到m,依次执行以下操作:
- a ( 1 ) = x ( i ) a^{(1)}=x^{(i)} a(1)=x(i)
- 使用正向传播j计算每一层的激活值 a ( l ) a^{(l)} a(l)
- 使用 y ( i ) y^{(i)} y(i)计算 δ ( L ) = a ( L ) − y ( i ) \delta^{(L)}=a^{(L)}-y^{(i)} δ(L)=a(L)−y(i),计算输出层的误差
- 并且使用该法计算各层的误差 δ ( L − 1 ) , δ ( L − 2 ) , . . . , δ ( 2 ) \delta^{(L-1)},\delta^{(L-2)},...,\delta^{(2)} δ(L−1),δ(L−2),...,δ(2)
- 接着 Δ i j ( l ) : = Δ i j ( l ) + a j ( l ) δ i ( l + 1 ) \Delta_{ij}^{(l)}:=\Delta_{ij}^{(l)}+a_j^{(l)}\delta_i^{(l+1)} Δij(l):=Δij(l)+aj(l)δi(l+1)
完成了这些工作之后,利用上面的结果计算如下的式子
D
i
j
(
l
)
:
=
1
m
Δ
i
j
(
l
)
+
λ
Θ
i
j
(
l
)
i
f
j
≠
0
D
i
j
(
l
)
:
=
1
m
Δ
i
j
(
l
)
i
f
j
=
0
D_{ij}^{(l)}:=\frac{1}{m}\Delta_{ij}^{(l)}+\lambda\Theta_{ij}^{(l)}\:\:if\:j\neq0\\D_{ij}^{(l)}:=\frac{1}{m}\Delta_{ij}^{(l)}\:\:if\:j=0
Dij(l):=m1Δij(l)+λΘij(l)ifj=0Dij(l):=m1Δij(l)ifj=0可以看到,这里我们引入了正则化的
λ
\lambda
λ项,也就是这里的作用是正则化,通过这些我们又可以计算出代价函数
J
(
Θ
)
J(\Theta)
J(Θ)的导数
∂
∂
Θ
i
j
(
l
)
J
(
Θ
)
=
D
i
j
(
l
)
\frac{\partial}{\partial\Theta_{ij}^{(l)}}J(\Theta)=D_{ij}^{(l)}
∂Θij(l)∂J(Θ)=Dij(l)。这就是反向传播算法计算代价函数的过程