该文章主要为完成实训任务,详细实现过程及结果见【http://t.csdn.cn/OmCQ8】
文章目录
- 一、概念
- 二、自定义分区器
- 2.1 提出问题
- 2.2 解决问题
- 1. 准备数据文件
- 2. 新建科目分区器
- 3. 测试科目分区器
- 三、课后作业
一、概念
-
在Spark中,RDD(弹性分布式数据集)是一种基本的数据结构,可以在集群上并行处理数据。RDD的分区(Partition)是数据的逻辑划分单元,它决定了数据在集群中的分布和并行处理的方式。掌握RDD分区的设计和调整对于优化Spark应用程序的性能至关重要。以下是关于RDD分区的一些重要概念和建议:
-
分区类型:Spark提供了多种分区类型,如Hash分区、Range分区和自定义分区等。Hash分区是最常用的分区策略,它根据键的哈希值将数据均匀分配到不同的分区中。Range分区按照键的范围将数据排序分区,适用于范围查询和排序操作。自定义分区允许开发人员根据自己的需求定义特定的分区策略。
-
分区数目:RDD的分区数目是决定并行处理程度的重要因素。合理设置分区数目可以充分利用集群资源,提高计算性能。分区数目应该与集群的核心数目和可用内存相匹配,通常建议设置为集群核心数目的两倍或更多。
-
分区操作:在进行RDD的转换操作时,分区数目可能会发生变化。一些操作(如map、filter和flatMap等)保持原有分区数目不变,而一些操作(如reduceByKey和groupByKey等)会进行重新分区。在转换操作中,需要注意操作的影响,避免出现数据倾斜或不均匀的情况。
-
分区调整:在某些情况下,可能需要手动调整RDD的分区,以优化数据的分布和并行计算。可以使用repartition和coalesce等操作来重新分区。repartition操作会进行全量的数据洗牌,适用于需要完全重新分区的情况。而coalesce操作只会合并部分分区,适用于减少分区数目而不进行完全洗牌的情况。
-
数据倾斜处理:在处理大规模数据时,可能会出现数据倾斜(Data Skew)的情况,即某些分区的数据量远大于其他分区。数据倾斜会导致计算不均衡和性能下降。对于数据倾斜的RDD,可以考虑采取一些特殊的处理策略,如使用repartition操作进行重新分区、使用reduceByKey替换groupByKey等。
-
总的来说,掌握RDD分区的设计和调整是优化Spark应用程序性能的关键。通过合理设置分区数目、选择适当的分区策略、注意分区操作和处理数据倾斜等技巧,可以充分发挥Spark的并行计算能力,提高应用程序的效率和可扩展性。
二、自定义分区器
2.1 提出问题
- 例如,某学生有以下3科三个月的月考成绩数据。
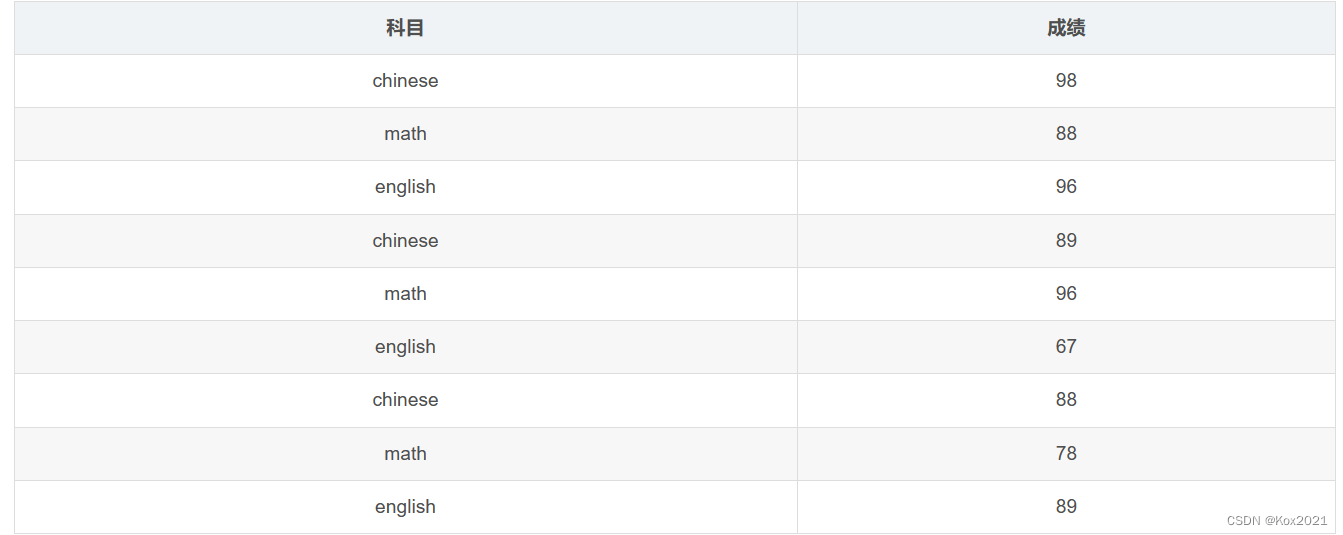
- 现需要将每一科成绩单独分配到一个分区中,然后将3科成绩输出到HDFS的指定目录(每个分区对应一个结果文件),此时就需要对数据进行自定义分区。
2.2 解决问题
1. 准备数据文件
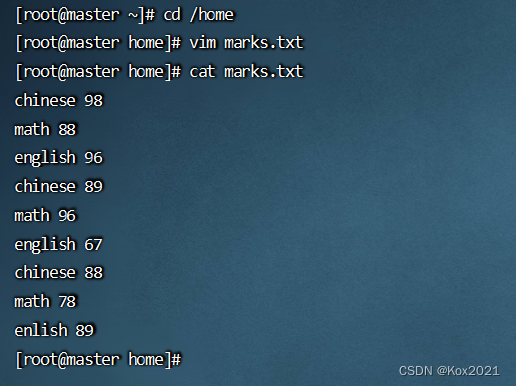
- 在
master虚拟机的/home目录里创建marks.txt
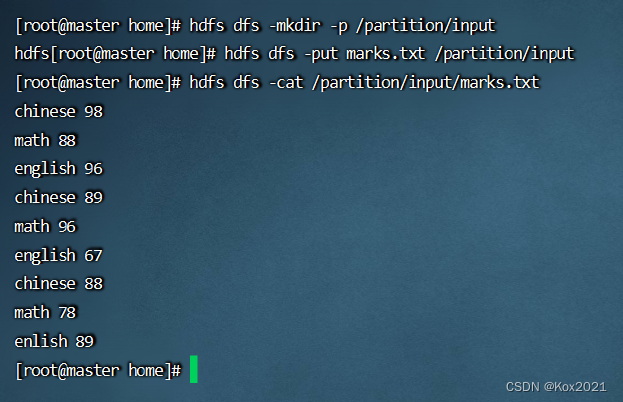
- 将数据文件上传到HDFS指定目录
2. 新建科目分区器
- 创建
cn.kox.rdd.day04包,在包里创建SubjectPartitioner类
package cn.kox.rdd.day04
import org.apache.spark.Partitioner
/**
* @ClassName: SubjectPartitioner
* @Author: Kox
* @Data: 2023/6/15
* @Sketch:
*/
class SubjectPartitioner(partitions: Int) extends Partitioner {
/**
* @return 分区数量
*/
override def numPartitions: Int = partitions
/**
* @param key(科目)
* @return 分区索引
*/
override def getPartition(key: Any): Int = {
val partitionIndex = key.toString match {
case "chinese" => 0
case "math" => 1
case "english" => 2
}
partitionIndex
}
}
3. 测试科目分区器
- 在
cn.kox.rdd.day04包里创建TestSubjectPartitioner单例对象
package cn.kox.rdd.day04
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @ClassName: TestSubjectPartitioner
* @Author: Kox
* @Data: 2023/6/15
* @Sketch:
*/
object TestSubjectPartitioner {
def main(args: Array[String]): Unit = {
// 创建Spark配置对象
val conf = new SparkConf()
.setAppName("TestSubjectPartitioner") // 设置应用名称
.setMaster("local[*]") // 设置主节点位置(本地调试)
// 基于Spark配置对象创建Spark容器
val sc = new SparkContext(conf)
// 读取HDFS文件,生成RDD
val lines = sc.textFile("hdfs://master:9000/partition/input/marks.txt")
// 将每行数据映射成(科目,成绩)二元组
val data: RDD[(String, Int)] = lines.map(line => {
val fields = line.split(" ")
(fields(0), fields(1).toInt) // (科目,成绩)
})
// 将数据按科目分区器重新分区
val partitionData = data.partitionBy(new SubjectPartitioner(3))
// 在控制台输出分区数据
partitionData.collect.foreach(println)
// 保存分区数据到HDFS指定目录
partitionData.saveAsTextFile("hdfs://master:9000/partition/output")
}
}
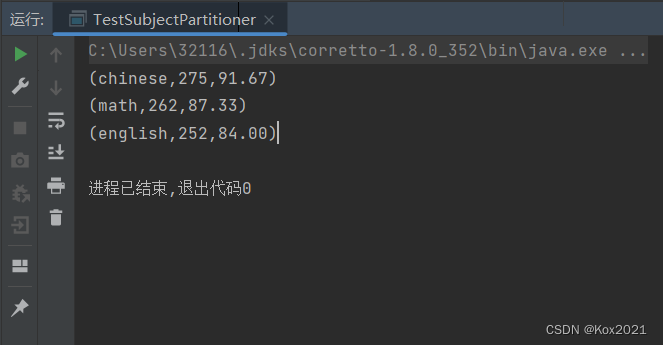
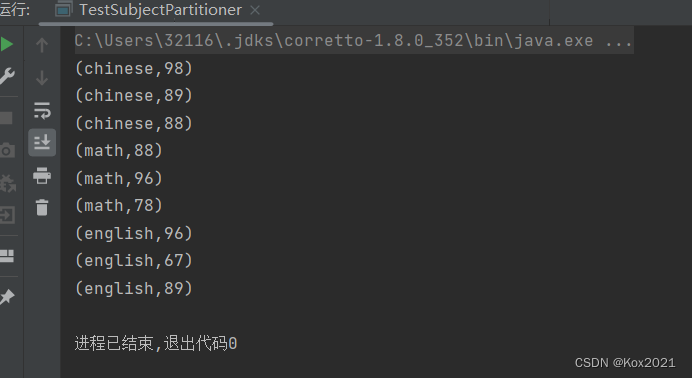
- 运行程序,查看结果
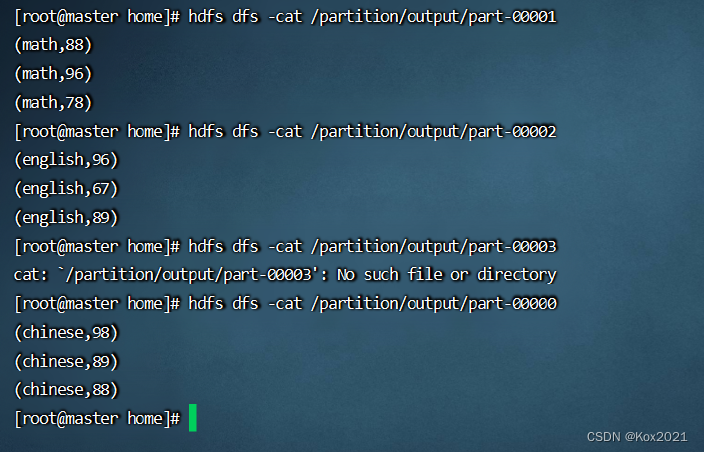
- 查看HDFS的结果文件
三、课后作业

package cn.kox.rdd.day04
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @ClassName: TestSubjectPartitioner
* @Author: Kox
* @Data: 2023/6/15
* @Sketch:
*/
object TestSubjectPartitioner {
def main(args: Array[String]): Unit = {
// 创建Spark配置对象
val conf = new SparkConf()
.setAppName("TestSubjectPartitioner") // 设置应用名称
.setMaster("local[*]") // 设置主节点位置(本地调试)
// 基于Spark配置对象创建Spark容器
val sc = new SparkContext(conf)
// 读取HDFS文件,生成RDD
val lines = sc.textFile("hdfs://master:9000/partition/input/marks.txt")
// 将每行数据映射成(科目,成绩)二元组
val data: RDD[(String, Int)] = lines.map(line => {
val fields = line.split(" ")
(fields(0), fields(1).toInt) // (科目,成绩)
})
// 将数据按科目分区器重新分区
val partitionData = data.partitionBy(new SubjectPartitioner(3))
// 计算每个科目的总分和平均分
val result = partitionData
.mapValues(score => (score, 1)) // 将每个成绩映射为(成绩, 1)
.reduceByKey { case ((score1, count1), (score2, count2)) =>
(score1 + score2, count1 + count2) // 按科目进行成绩求和和计数
}
.map { case (subject, (totalScore, count)) =>
val average = totalScore.toDouble / count.toDouble // 计算平均分
val formattedAverage = f"%%.2f".format(average) // 格式化平均分保留两位小数
(subject, totalScore, formattedAverage)
}
// 输出结果
result.foreach(println)
}
}