文章目录
- 前言
- 一、插入、删除和随机访问都是 O(1) 的容器
- 题目分析
- 思路分析
- 代码
- 二、最近最少使用缓存
- 题目分析
- 思路分析
- 代码
- 三、有效的变位词
- 题目
- 分析
- 代码
- 四、变位词组
- 题目分析
- 思路分析
- 代码
- 五、外星语言是否排序
- 题目分析
- 思路分析
- 代码
- 六、最小时间差
- 题目分析
- 思路分析
- 代码①——快排思路
- 代码②——哈希思路
- 总结
前言
剑指offer专项突破版(力扣官网)——> 点击进入
本文所属专栏——>点击进入
本文涉及到了哈希表的基础知识,博主总结了一下,放到这里,有兴趣的小伙伴,可以看一下。
哈希表基础知识——哈希表——C语言
话不多说,直接进入正题。
一、插入、删除和随机访问都是 O(1) 的容器
题目分析

总结:自定义结构体,完成上述要求。
思路分析
为了实现getRandom的等概率返回值,我们采用的数据结构必然是数组这种连续存储的数据结构。
为了实现访问数据的的O(1),我们还需采用哈希表的结构进行存储数据信息。键值是元素val,哈希表中存储的值是元素val的下标。
为了实现删除数据的O(1),我们需要将数组中的数据跟最后一个位置的数据进行交换,问题就转换为删除数组尾部的元素,就省去了删除之后移动数据的操作,同时不要忘记,还要更新哈希表中的信息哦!
代码
#define MIN_NUMS 5000 //这是所开辟数组通过测试的最小元素个数
typedef struct Hash
{
int key;
int val;
UT_hash_handle hh;
}HNode;
//查找函数
int find(HNode** obj, int key)
{
HNode* ret = NULL;
HASH_FIND_INT(*obj,&key,ret);
if(ret != NULL)
{
return ret->val;
}
return -1;
}
//插入函数
void insert(HNode** obj, int key, int val)
{
HNode* ret = NULL;
HASH_FIND_INT(*obj,&key,ret);
if(ret == NULL )
{
ret = (HNode*)malloc(sizeof(HNode));
ret->key = key;
ret->val = val;
HASH_ADD_INT(*obj,key,ret);
}
//找到我们就更新下标,因为数组删除时元素的下标会发生变化
else
{
ret->val = val;
}
}
void remove_one(HNode** obj, int key)
{
HNode* ret = NULL;
HASH_FIND_INT(*obj,&key,ret);
if(ret != NULL)
{
HASH_DEL(*obj,ret);//从哈希表中移除,并没有释放其空间,需手动释放
free(ret);
}
}
void remove_all(HNode* obj)
{
HNode* cur,*next;
HASH_ITER(hh,obj,cur,next)
{
HASH_DEL(obj,cur);
free(cur);
}
}
typedef struct
{
int* arr;
int size;
HNode* hash;
} RandomizedSet;
/** Initialize your data structure here. */
RandomizedSet* randomizedSetCreate()
{
//为了返回随机数,需要我们设置一下随机数起点
srand((unsigned int)time(NULL));
RandomizedSet* map = (RandomizedSet*)malloc(sizeof(RandomizedSet));
map->arr = (int*)malloc(sizeof(int)*MIN_NUMS);
map->size = 0;
map->hash = NULL;
return map;
}
/** Inserts a value to the set. Returns true if the set did not already contain the specified element. */
bool randomizedSetInsert(RandomizedSet* obj, int val)
{
//如果找不到我们就插入
int ret = find(&(obj->hash),val);
if(ret == -1)
{
(obj->arr)[(obj->size)++] = val;
insert(&(obj->hash),val,obj->size-1);
return true;
}
return false;
}
/** Removes a value from the set. Returns true if the set contained the specified element. */
bool randomizedSetRemove(RandomizedSet* obj, int val)
{
//如果有我们就移除
int ret = find(&(obj->hash),val);
if(ret != -1)
{
//直接将末尾的元素赋值到当前元素的下标处
int last = (obj->arr)[(obj->size)-1];
(obj->arr)[ret] = last;
//同时size减一执行删除操作
(obj->size)--;
//更新末尾元素的新的下标,当然前提是首不等于尾
insert(&(obj->hash),last,ret);
//在哈希表中删除此元素
remove_one(&(obj->hash),val);
return true;
}
return false;
}
/** Get a random element from the set. */
int randomizedSetGetRandom(RandomizedSet* obj)
{
//获取随机数下标
int randomIndex = rand()%(obj->size);
return obj->arr[randomIndex];
}
void randomizedSetFree(RandomizedSet* obj)
{
remove_all(obj->hash);
free(obj->arr);
free(obj);
}
二、最近最少使用缓存
题目分析
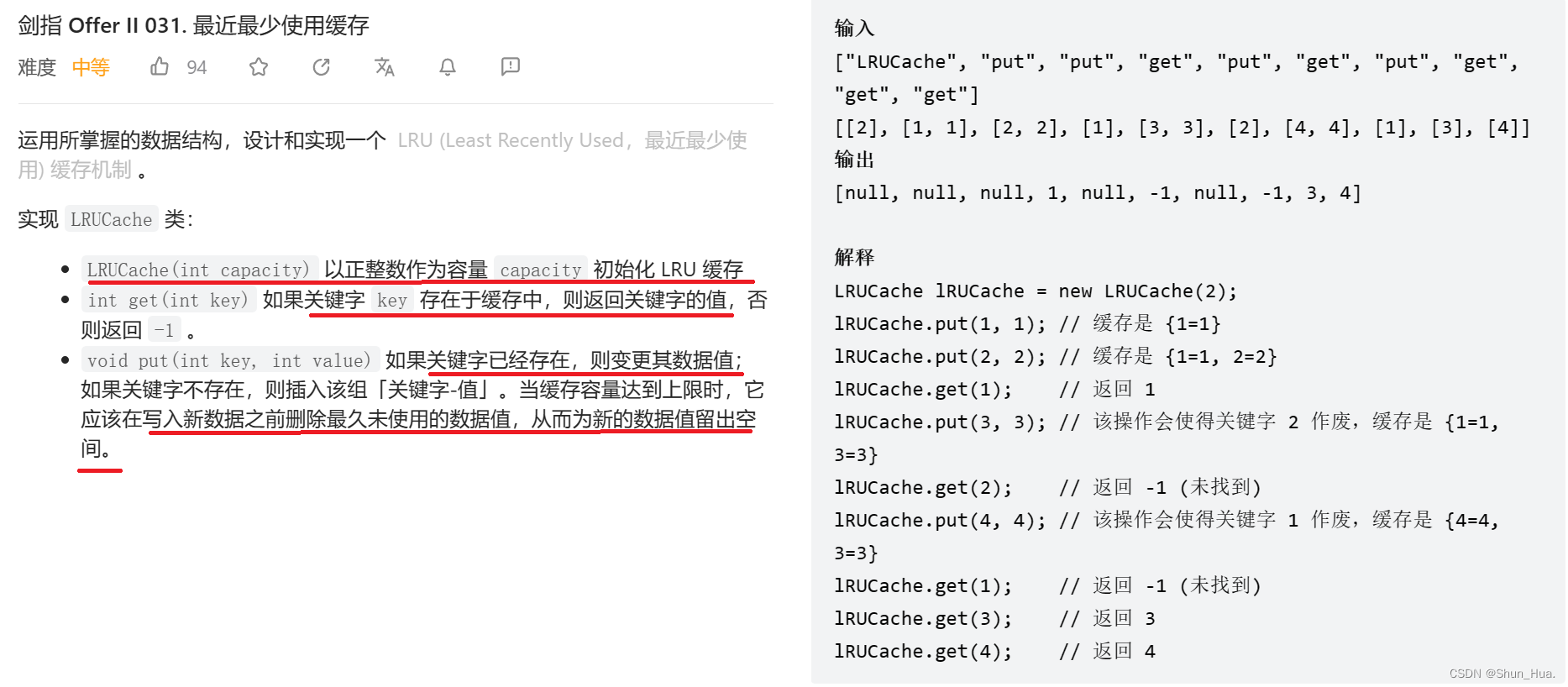
思路分析
因为是缓存,且当缓存满时,要释放最久未被使用的值,我们可以,采用双向循环链表的数据结构,当使用一个值时我们就更新头结点,到下一个结点,这样下一个结点就是最久未被使用的结点。如果需要删除,我们只需要头删即可。
当我们需要在时间复杂度O(1),实现访问数据的操作,我们就需要哈希表这种数据结构,在开辟结点,存储信息的同时,也要通过关键字key,将节点的地址,存储在哈希表中,方便访问。
代码
//双向循环链表
typedef struct DRListNode
{
int key;
int val;
struct DRListNode* prev;
struct DRListNode* next;
}Node;
//哈希表
typedef struct Hash
{
int key;
Node* val;
UT_hash_handle hh;
}HNode;
//哈希表的查找函数
Node* find(HNode** obj, int key)
{
HNode* ret = NULL;
HASH_FIND_INT(*obj,&key,ret);
if(ret!=NULL)
{
return ret->val;
}
return NULL;
}
//哈希表的插入函数
void insert(HNode**obj, int key,Node* val)
{
HNode* ret = NULL;
HASH_FIND_INT(*obj,&key,ret);
if(ret == NULL)
{
ret = (HNode*)malloc(sizeof(HNode));
ret->key = key;
ret->val = val;
HASH_ADD_INT(*obj,key,ret);
}
else
{
ret->val = val;
}
}
//删除指定结点
void remove_one(HNode** obj, int key)
{
HNode* ret = NULL;
HASH_FIND_INT(*obj,&key,ret);
if(ret != NULL)
{
HASH_DEL(*obj,ret);
free(ret);
}
}
//全部删除
void remove_all(HNode** obj)
{
HNode* cur,*next;
HASH_ITER(hh,*obj,cur,next)
{
HASH_DEL(*obj,cur);
free(cur);
}
}
//开辟结点
Node* BuyNode(int key,int val)
{
Node* tmp = (Node*)malloc(sizeof(Node));
tmp->key = key;
tmp->val = val;
tmp->prev = NULL;
tmp->next = NULL;
return tmp;
}
//双向循环链表的尾插
Node* PushBack(Node** head, int key, int val)
{
Node *tmp = BuyNode(key,val);
if(*head == NULL)
{
tmp->prev = tmp;
tmp->next = tmp;
*head = tmp;
}
else
{
Node* first = *head;
Node* tail = first->prev;
tmp->prev = tail;
tmp->next = first;
first->prev = tmp;
tail->next = tmp;
}
return tmp;
}
//链表的头删
void PopFront(Node** curr)
{
Node* first = *curr;
//说明只有一个结点且为头结点
if(first->next == first)
{
*curr = NULL;
free(first);
}
else
{
Node* cur = *curr;
Node* prev = cur->prev;
Node* next = cur->next;
//删除cur
prev->next = next;
next->prev = prev;
*curr = next;
free(cur);
}
}
//链表的释放
void free_all(Node* head)
{
if(head != NULL)
{
Node* first = head->next;
while(first!= head)
{
Node* next = first->next;
free(first);
first = next;
}
}
free(head);
}
typedef struct
{
//链表的头结点
Node* head;
//链表的目前的大小
int size;
//链表的最大容量
int capacity;
//哈希表
HNode* hash;
}LRUCache;
LRUCache* lRUCacheCreate(int capacity)
{
LRUCache* set = (LRUCache*)malloc(sizeof(LRUCache));
set->head = NULL;
set->size = 0;
set->capacity = capacity;
set->hash = NULL;
return set;
}
int lRUCacheGet(LRUCache* obj, int key)
{
Node* ret = find(&(obj->hash),key);
if(ret != NULL)
{
//先进行尾插
Node* new = PushBack(&(obj->head),ret->key,ret->val);
//再把以前的结点进行释放
if(obj->head == ret)
{
PopFront(&(obj->head));
}
else
{
PopFront(&ret);
}
//更新哈希表的结点地址
insert(&(obj->hash),key,new);
return new->val;
}
return -1;
}
void lRUCachePut(LRUCache* obj, int key, int value)
{
Node* ret = find(&(obj->hash),key);
// printf("%p\n",ret);
if(ret != NULL)
{
ret->val = value;
Node* new = PushBack(&(obj->head),ret->key,ret->val);
//再把以前的结点进行释放
if(obj->head == ret)
{
PopFront(&(obj->head));
}
else
{
PopFront(&ret);
}
//更新哈希表的结点地址
insert(&(obj->hash),key,new);
}
else
{
//先进行判断
//如果当前的size小于capacity就直接尾插
if(obj->size < obj->capacity)
{
Node* new = PushBack(&(obj->head),key,value);
//更新哈希表
insert(&(obj->hash),key,new);
//size还要加1
(obj->size)++;
}
else
{
//说明size == capacity
//先清理此节点在哈希表中的信息
remove_one(&(obj->hash),(obj->head)->key);
//先进行头删
PopFront(&(obj->head));
//再进行尾插
Node* new = PushBack(&(obj->head),key,value);
//再更新此节点在哈希表中的信息
insert(&(obj->hash),key,new);
//size无需加加
}
}
}
void lRUCacheFree(LRUCache* obj)
{
remove_all(&(obj->hash));
free_all(obj->head);
free(obj);
}
博主,稍微啰嗦几句,如果不是自讨苦吃,或者锻炼自己的造轮子的能力,是不建议写这种题的,除非没事闲的(很明显是我了)。
三、有效的变位词
题目
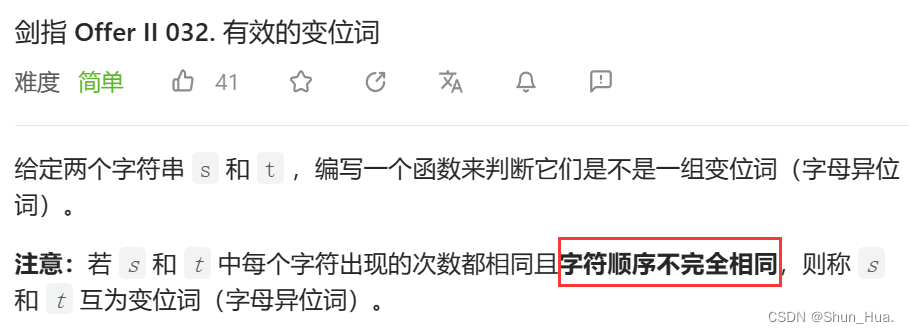
分析
此题我们在字符篇(点我进入)系统地论述过,此处不过多叙述,唯一需要强调的一个词是有效的。
代码
bool is_diff(char* str1, char* str2)
{
while((*str1 != '\0')&&(*str2 != '\0'))
{
if(*str1 != *str2)
{
return true;
}
str1++;
str2++;
}
return false;
}
void fun(char *s,int* arr)
{
for(;*s != '\0'; s++)
{
arr[*s-'a']++;
}
}
bool check(int* arr1, int* arr2)
{
for(int i = 0; i < 26; i++)
{
if(arr1[i]!=arr2[i])
{
return false;
}
}
return true;
}
bool isAnagram(char * s, char * t)
{
if(is_diff(s,t))
{
int* str1 = (int*)malloc(sizeof(int)*26);
int* str2 = (int*)malloc(sizeof(int)*26);
memset(str1,0,sizeof(int)*26);
memset(str2,0,sizeof(int)*26);
fun(s,str1);
fun(t,str2);
return check(str1,str2);
}
return false;
}
四、变位词组
题目分析
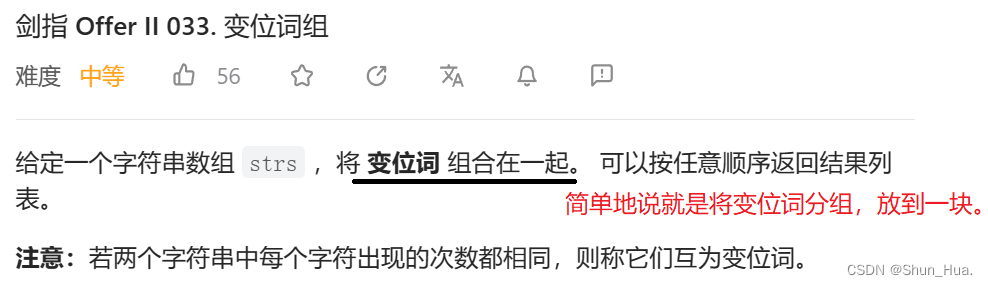
思路分析
如何判断是多组呢?思路其实很简单,将变位词固定顺序——快排 ,也就是对变位词排序,判断在哈希表中有没有,如果有,则说明是同一组变位词,如果没有,则不是同一组变位词,需要将排序过后的变位词,当做键值记录。
代码
typedef struct Hash
{
const char* key;//字符串
int row;//所在行号
int size;//当前行的个数
int capacity;//最大容量
char** str;
UT_hash_handle hh;
}HNode;
int my_cmp(const void* e1, const void* e2)
{
return *(char*)(e1) - *(char*)(e2);
}
char *** groupAnagrams(char ** strs, int strsSize, int* returnSize, int** returnColumnSizes)
{
HNode* head = NULL;
int group = 0;
for(int i = 0; i < strsSize; i++)
{
//先将字符串复制一份,进行排序
int size = strlen(strs[i]) + 1;
char* copy_str = (char*)malloc(sizeof(char)*size);
strcpy(copy_str,strs[i]);
//对复制的字符串进行排序
qsort(copy_str,size-1,sizeof(char),my_cmp);
//先看在字符串中有没有这个字符串
HNode* ret = NULL;
HASH_FIND_STR(head,copy_str,ret);
//printf("%s\n",copy_str);
if(ret == NULL)
{
//说明哈希表中没有
ret = (HNode*)malloc(sizeof(HNode));
ret->row = group++;
ret->size = 0;
ret->capacity = 10;
//赋值key
ret->key = copy_str;
//开辟空间
ret->str = (char**)malloc(sizeof(char*)*(ret->capacity));
(ret->str)[ret->size++] = strs[i];
//添加到哈希表中
HASH_ADD_KEYPTR(hh,head,ret->key,strlen(ret->key),ret);
}
else
{
//说明哈希表中有
//判断是否需要扩容
if(ret->size == ret->capacity)
{
ret->str = (char**)realloc(ret->str,sizeof(char*)*(ret->capacity)*2);
(ret->capacity)*=2;
}
(ret->str)[ret->size++] = strs[i];
}
}
//剩余的工作是将数组移到一堆
//先判断需要开多少行
int n = HASH_COUNT(head);
*returnSize = n;
char*** str = (char***)malloc(sizeof(char**)*n);
*returnColumnSizes = (int*)malloc(sizeof(int)*n);
//通过遍历哈希表放到一堆
HNode* cur,*next;
HASH_ITER(hh,head,cur,next)
{
//获取行号
int row = cur->row;
//获取行元素个数
int size = cur->size;
//获取行所在地址
char** str_row = cur->str;
str[row] = str_row;
(*returnColumnSizes)[row] = size;
}
return str;
}
五、外星语言是否排序
题目分析
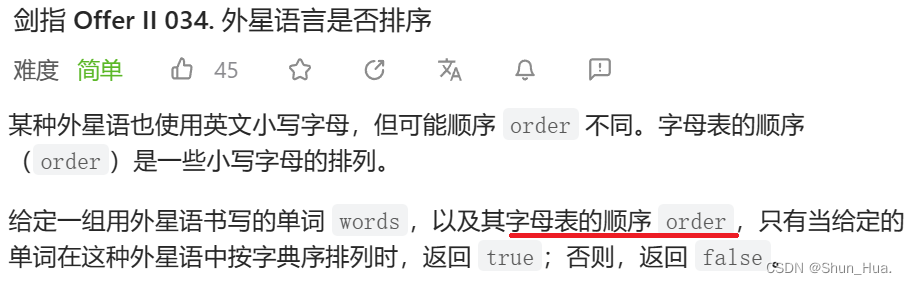
只要看明白了,其实很简单,意思就是我们是按abcdef……yz,26个字母排序的。但外星语言可能是按bcdef……26个字母排序的,但字母都是相同的。
思路分析
- 关键:记录字典序的
每个字符的顺序,然后遍历数组,比较相邻字符串的每个字符是不是按照这种顺序排的。
代码
bool isAlienSorted(char ** words, int wordsSize, char * order)
{
//记录字典序,顺序
int* arr = (int*)malloc(sizeof(int)*26);
memset(arr,0,sizeof(int)*26);
for(int i = 0; i < 26; i++)
{
arr[order[i]-'a'] = i;
}
//判断是否按照顺序进行排序
for(int i = 0; i < wordsSize-1; i++)
{
char* cur = words[i];
char* next = words[i+1];
while(*cur!='\0'&& *next !='\0')
{
if(arr[*cur-'a'] > arr[*next-'a'])
{
return false;
}
else if(arr[*cur-'a'] < arr[*next-'a'])
{
break;
}
else
{
cur++;
next++;
}
}
if((*cur!='\0')&&(*next=='\0'))
{
return false;
}
}
return true;
}
六、最小时间差
题目分析
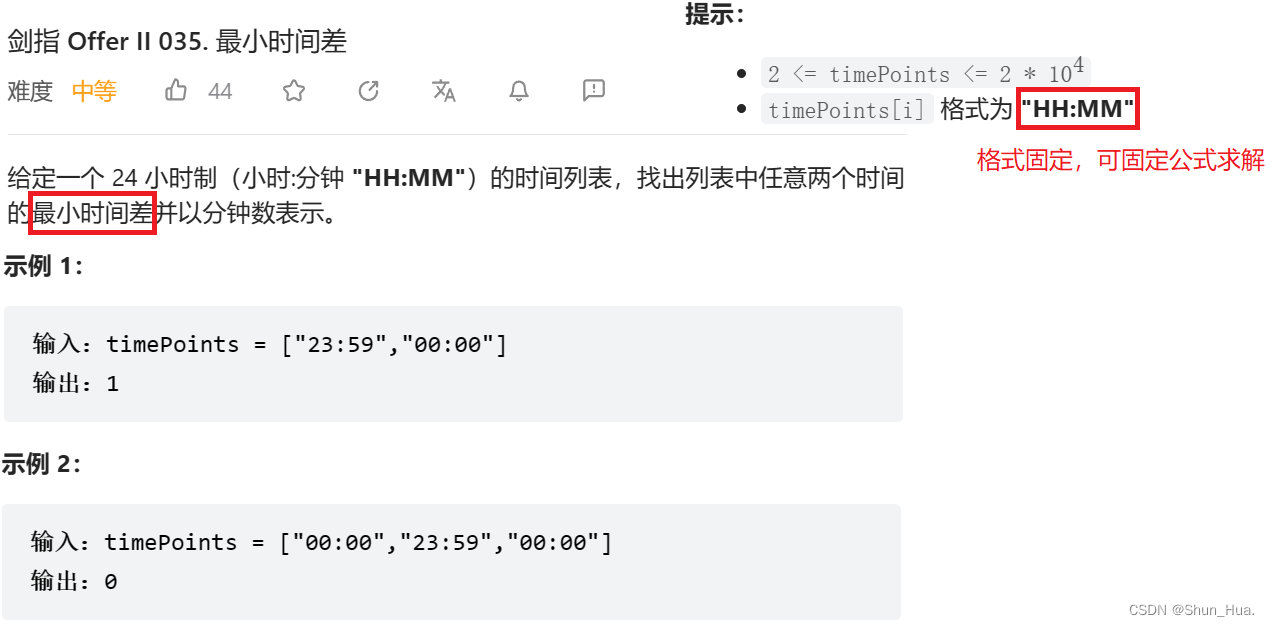
思路分析
补充知识:一天最多有1440分钟
这道题的关键在于求最小时间差(分钟表示) ,比如"23:59"和"00:00",最小时间差是1,而不是1439。我们可以将此问题看为:圆上两点之间的最短距离,如果两点之差大于圆周长的一半,那就是另一边较短了。
因此,如果两时间的分钟差大于一天一半的时间,那就是另一边较短了。
图解:
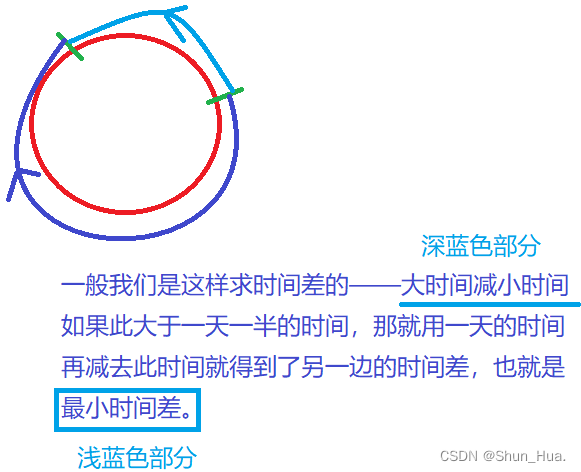
那如何求最短时间差呢,这里提供两种思路,
- 排序之后,两相邻数的时间差可能最小的,遍历一遍。首尾时间差,也可能是最小的,因此我们需要再求一下。
- 为了省去排序的麻烦 ,时间
按分钟分,只有1440种可能,因此我们可以开一个数组,存每个槽位是否有这个时间,如果时间重复,直接返回0,即可。剩下的就是找存在的相邻的时间,和存在的首尾时间差。
代码①——快排思路
int change_minutes(char* str)
{
int hours = (str[0]-'0')*10 + (str[1]-'0');
int minutes = (str[3]-'0')*10 + (str[4]-'0');
return hours*60 + minutes;
}
int minutes_sub(int m1, int m2)
{
int ret = abs(m1-m2);
if(ret > 1440/2)
{
return 1440-ret;
}
else
{
return ret;
}
}
int my_cmp(const void* e1, const void* e2)
{
return *(int*)e2 - *(int*)e1;
}
int findMinDifference(char ** timePoints, int timePointsSize)
{
//将时间转换为分钟记录
int*arr = (int*)malloc(sizeof(int)*timePointsSize);
for(int i = 0; i < timePointsSize; i++)
{
arr[i] = change_minutes(timePoints[i]);
}
//将时间进行排序_排降序
qsort(arr,timePointsSize,sizeof(int),my_cmp);
//比较相邻的时间差,最大时间差的那个可能也是最小的(想一下为啥子),因此我们要先计算一下。
int min = minutes_sub(arr[0],arr[timePointsSize-1]);
for(int i = 0; i < timePointsSize-1;i++)
{
int cur = minutes_sub(arr[i],arr[i+1]);
if(cur < min)
{
min = cur;
}
}
//及时地清理空间
free(arr);
return min;
}
代码②——哈希思路
int change_minutes(char* str)
{
int hours = (str[0]-'0')*10 + (str[1]-'0');
int minutes = (str[3]-'0')*10 + (str[4]-'0');
return hours*60 + minutes;
}
int minutes_sub(int m1, int m2)
{
int ret = abs(m1-m2);
if(ret > 1440/2)
{
return 1440-ret;
}
else
{
return ret;
}
}
int findMinDifference(char ** timePoints, int timePointsSize)
{
//开一个数组存储所有可能的情况
int *arr = (int*)malloc(sizeof(int)*1440);
memset(arr,0,sizeof(int)*1440);
for(int i = 0; i < timePointsSize; i++)
{
int ret = change_minutes(timePoints[i]);
if(arr[ret] == 0)
{
arr[ret] = 1;
}
else
{
//如果有相同的直接返回0
return 0;
}
}
//先找到首尾
int first = 0;
int last = 1439;
while((arr[first] == 0)||(arr[last] == 0))
{
if(arr[first] == 0)
{
first++;
}
if(arr[last] == 0)
{
last--;
}
}
int min = minutes_sub(first,last);
for(int i = 0; i < 1440;)
{
while(arr[i]==0)
{
i++;
}
int j = i+1;
while(j <1440&&arr[j]==0)
{
j++;
}
if(j != 1440)
{
int ret = minutes_sub(i,j);
if(ret < min)
{
min = ret;
}
}
i = j;
}
free(arr);
return min;
}
总结
今天的内容就分享到这里了,文章不错的话,帮忙点个赞呗,小伙伴们,我们下次见吧!