目前Java都在流行一个说词:高并发。
反正不管是不是,反正就是高并发。
谈高并发,我们需要知道几个名词:
- -响应时间(Response Time,RT)
- -吞吐量(Throughput)
- -每秒查询率QPS(Query Per Second)
- -每秒事务处理量TPS(Transaction Per Second)
- -同时在线用户数量
整体来说高并发的技术很多,但是大体的原则考虑性能和可用性这两个大点出发。
我写的主要是一些常用的方案。当然方案并不全,只是我经常使用的方法给你们参考。
高并发永远是说起来容易,做起来难得,而且我极其反对用什么Redis锁,或者复杂的协议去实现高并发,我更推荐的是用最简单直接的方法去实现高并发。
用复杂技术去提高并发,如果只是得到50%的效率提升,而换来的确实你的系统一定难以扩展和维护,这叫做得不偿失。
对于网站来说,高并发崩溃是难以接受的,比如唯品会
唯品会崩了,相关负责人被免职:致损失过亿、影响 800 万客户_机房_功能_故障
崩溃过亿的损失,且800万用户受到影响,同时还会影响客户的忠诚度,客户离开网站,就很难再回来了。这就是为什么大部分互联网企业核心的关切是可用性和高并发的问题。
记住没有最好的方法,也没有最权威的人士。但是我们并不绝望,因为我们都是在不断地专研和改进中,包括微服务也是在不断地研究和发展中。
1、大部分的企业都不会面临超高并发
现在我们都在玩微服务,从实际的角度来说:
其实单机的QPS能达到2000的都算高并发, 也就是一台独立的服务实例能承担QPS为2000的都谈得上是高并发。
我曾经面对过1亿级别的用户的网站,上百亿条记录的MySQL数据库比的表。如果没有索引去查询这个表就直接崩,一条SQL可以20分钟后才能响应你。
如果 你是客户查找数据用20分钟,你心中的1万个草泥马估计在奔腾。
即便是这样的网站,其实真正巅峰的QPS也就是4万左右,但是每个服务都有10个实例,也就是平均每台承担的4000的QPS,这就是巅峰值。
回想能注册1亿级别用户的网站其实不算多,除非是哪些淘宝、京东、拼多多这样的超级电商的双十一的QPS才能达到数十万,所以面对1万左右的QPS几乎就是一般企业的巅峰了。
54.4万笔/秒!支付宝的技术到底有多强?_51CTO博客_支付宝每秒多少笔
对于几百万用户的网站,QPS的巅峰大约也就是5000左右,压力根本没有那么大,5000的QPS,每个服务都有3个实例,一个实例承受1666个QPS,基本没啥太大的问题。
千万级用户的QPS估计也就是1万到2万左右而已。
一个事实是:
曾经有人想挖我,并且告诉我他需要高并发。我就问,你们的QPS是多少,他说1000,我又问,最大表数据量去到多少,他说1000万左右。
我心中一万个草你马在奔腾,这也和我说高并发?
即便你扩充到5倍的规模,才用考虑微服务拆分的问题,这点数据量和QPS,直接单机就够了。
和他谈他是懂非懂的样子,和我说MySQL支撑不了,我心中真的服了,我的心理想的是,估计这家伙技术不行,在哪里装13。毕竟他是招聘人员,我尊重他,不揭短。
单Ngnix一般QPS可以达到5万左右,如果是多个节点的,我们还可以扩展,将后台服务器分在不同的区域(比如北上广蓉都可以部署机房),这样Nginx可以支撑几十万的QPS。
2、大的几条原则:
动静分离:
将需要很多流量的图片、CSS和JavaScript等通过网络的CDN节点中去,这样访问这些静态资源就很快。使用浏览器缓存就能保证大部分的访问性能足够。当然要注意的是图片压缩、脚本压缩这些问题,真正慢的是哪些大的静态资源,进行压缩合理规划就能得到想要的结果。
即便你不用CDN,也要考虑将静态的资源分配在独立的服务器上,而不是动静资源混在一起。
动态的数据独立的维护
读的问题走Redis、MongoDB就很快,对于大部分的QPS都是读,正如我说的每台QPS的巅峰大约是2000,考虑28原则,读是1600,写是400。每秒读1600次Redis你有什么压力??400需要写入数据库又有什么压力?所以合理的规划缓存和数据库对于网站的性能是十分重要的。
动态数据将是我们保持网站性能的核心。
服务高可用
任何服务都有可能故障,少许的服务故障,系统应该能够自动的排除,继续稳定工作。
合理的数据库分库
正如我说的,我遇到1亿的用户网站,我有5台机子,那么每个数据库的表大约只有2000万,这个性能优化就很明显。
合理的SQL
SQL的执行效率在很多时候就决定了你网站的性能。因此大部分的优化都集中在SQL中,实际好性能的网站大部分都在优化SQL。
一条好的SQL执行效率是另外一条的数倍,甚至是几十倍。本来10秒得到结果,优化后1秒出结果,这个就很香了对不?
缓存
读的问题,主要就是用缓存,这样性能就很快,能够支撑整个服务的访问。
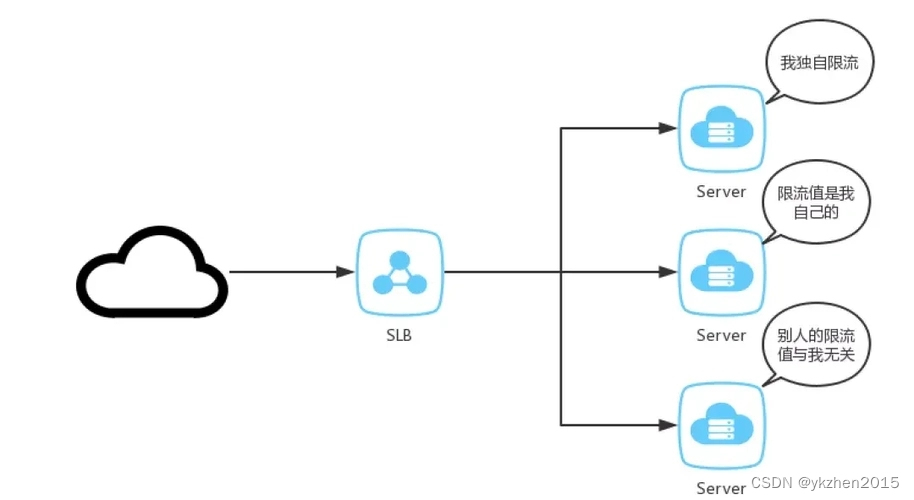
3、网关优化——服务的负载均衡:
一般来说软硬件环境相同,可以使用轮询算法,如果有性能差别还可以使用加权轮询算法,而Nacos、Eureka和Consul等都可以把不可用的实例剔除,从而保证高可用。
所以我们在使用API网关,比如Gateway的时候,通过合理的路由到具体的服务就很重要了。实例越多,就意味着摊分就也小。20个实例每个实例抗住2000,就意味着整体可以抗住4万的QPS了,要知道这个是1亿用户的网站。
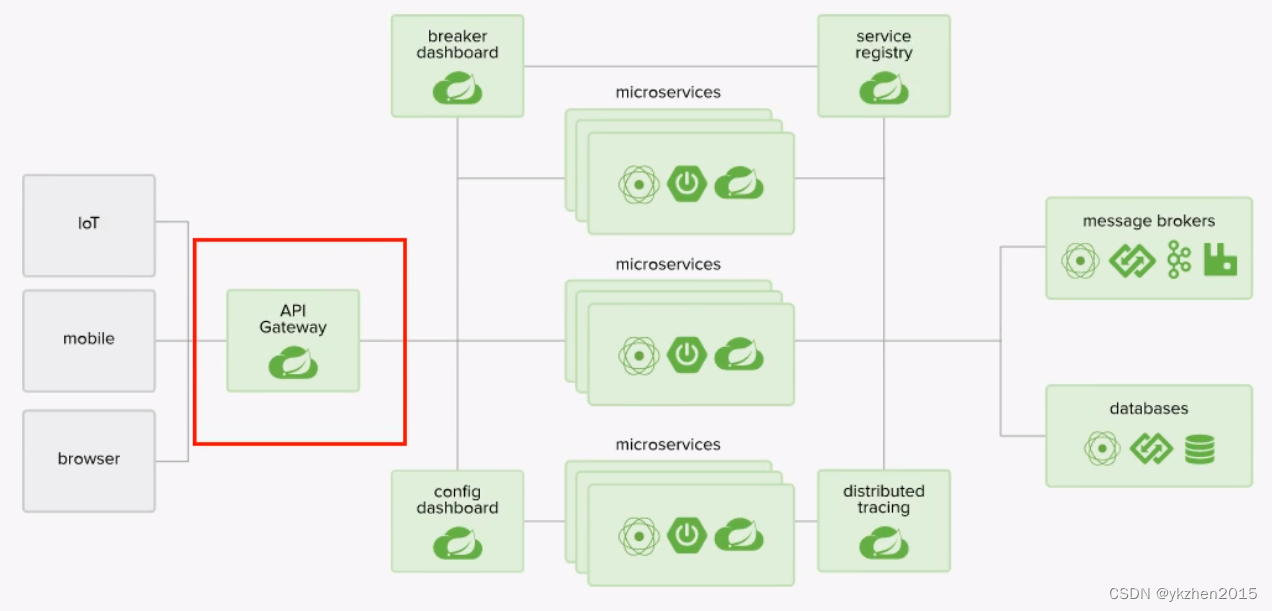
一般来说这里需要鉴别服务的有效性,可以使用过滤器,去卡一些用户发送的请求,比如:
- 一个用户短时间多次请求的,卡卡,要求验证码。
- 黑名单用户
- 僵尸用户(平时不干活,到了高峰期拼命操作的)
- 某段IP大量请求,可能是黄牛党公司
.......
将这些无效请求隔离在网关,一般我们可以使用缓存来解决,毕竟Redis的性能十分好,用它就能隔离很多不合理的请求达到后台真实的服务器。
第二个问题是限流,服务的第一原则是可用性,即便在高并发的环境无论成败,服务都要返回结果给用户,这个是一个原则。比如支付宝失败了,但是它告诉我支付失败,而不是让我空等,这个体验就完全是两码事了,对不?
因此我们需要做的一个核心问题是,避免过大的流量压垮服务。为了这个我们可以使用限流算法,一般是使用令牌桶的算法。
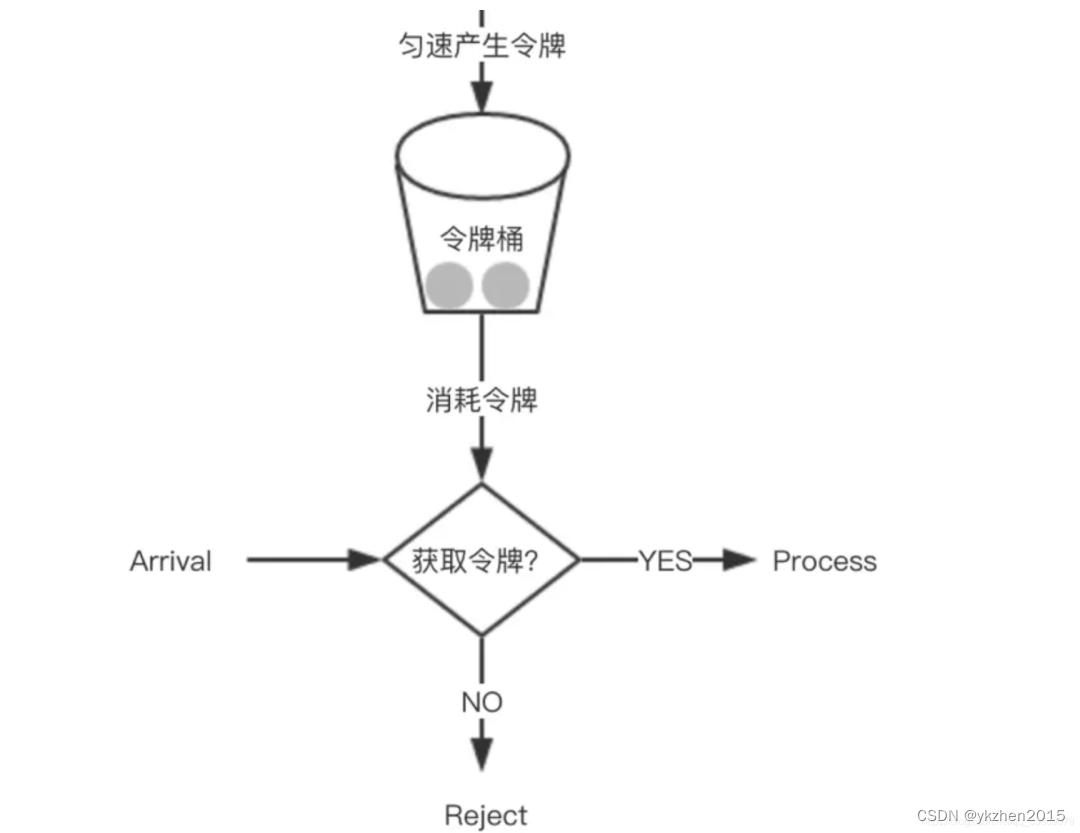
令牌桶算法,对于Resilient4j和Sentinel可以拿来就用,感兴趣的自己研究,我就不再啰嗦了。一般来说我们需要对系统进行压测。如果系统可以承担QPS为10000,那么取5000就够了。
有了限流就保证了不会过大的流量冲垮服务,这是很重要的,可用性是用户对系统的第一体验。
4、客户端负载均衡
客户端负载均衡是服务之间调用产生的。它就有三个角色:
服务消费者、服务提供者和注册中心。
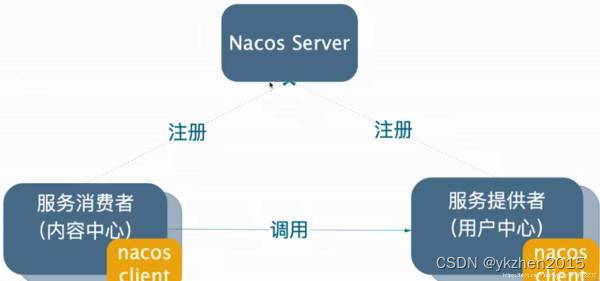
服务消费者和服务提供者都会注册到服务治理中心(比如Nacos),这样Nacos就会有一份注册清单,Nacos会不断地依靠客户端的续约来明确客户端是否可用,如果不可用就把服务实例剔除出去。因此Nacos始终都存在一份可用的服务清单。
每隔数秒,服务消费者就会从Nacos中去拉取Nacos维护的可用服务清单缓存到本地,这样服务消费者就可以使用这份缓存的服务清单对服务提供者进行负载均衡了。
以前的是Robbin和Feign支撑,目前是Spring Cloud给的负载均衡包和Feign支撑,相信大家都在用Feign多,毕竟声明调用,这个相对简单。

往往客户端之间的服务调用会引发很多的问题。比如A服务挂了,故障了,缓慢了,B服务去调用它,那么就可能B服务的大量线程挂起,导致自身也瘫痪,这样B服务就不可用了,同理如果C服务调用B服务,也会导致自身不可用。这样A的不可用导致了B的不可用,而B的不可用也会导致C的不可用......这样就蔓延出去了,这个现象称为服务雪崩,为了克服这个问题,我们会使用断路器保护服务。
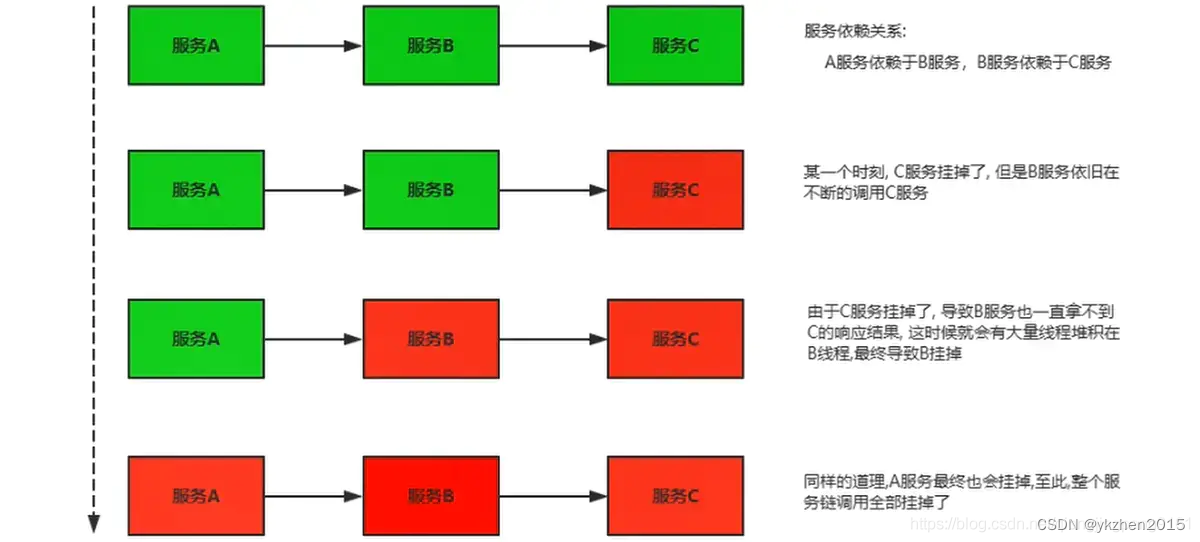
我呢,使用过NetFlix Histrix、开源的Resilient4J和Alibaba Sentinel等。断路器的作用是监控服务调用是否正常,如果不正常就将故障通过软件的方法隔离出去。

- 一开始为了恢复断路器为关闭,也就是允许你随意进行服务调用。
- 如果服务调用的异常多,超时多,那么断路器就会打开,然后阻断其他服务调用,这样服务消费者就不会有线程挂起,导致自身不可用了。
- 为了能够让服务调用恢复,过了段时间,断路器的状态由打开变成半打开,次数如果请求通畅,异常少,也不超时,那么断路器就关闭,让你继续随意进行服务调用。如果不是通畅的,那么对不起,它就恢复为打开状态,继续阻断你的服务调用。
如果你细致一点,对于一些重要的,容易出现故障的服务调用,你可以设置信号量或者线程池进行隔离。我们把这个叫做舱壁模式。
舱壁是船的概念,也就是真正的船舱应该是很多个,要是一个漏水的,其他船舱依旧密封,那么就不会沉没了。
舱壁模式的根本在于让容易出现错误、重要的服务调用隔离在一个线程池或者一个信号量之内,不让服务故障蔓延出去,其次可以根据故障原因来优化服务调用,避免服务雪崩。这就是我们所要做的保护服务。
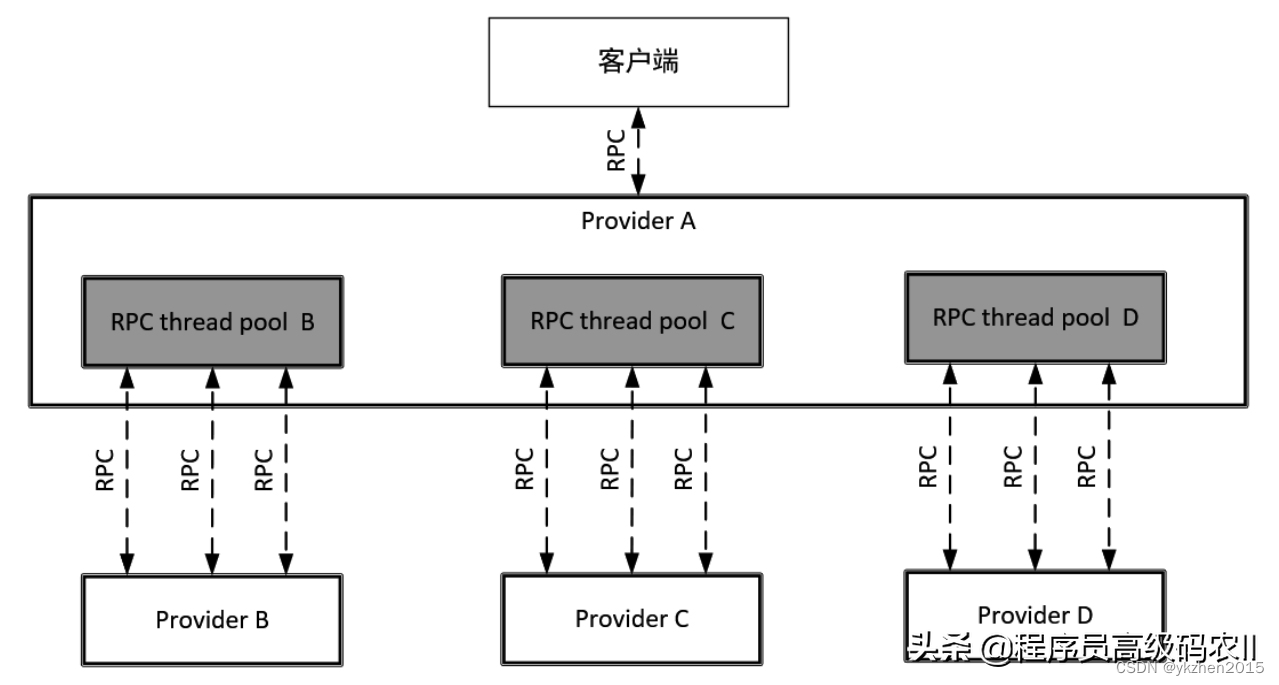
上面任何一个线程池的损坏,都会被隔离出去,而不会影响别的服务调用的工作,这就是舱壁模式。
服务调用使用缓存,如果调用的数据不需要频繁更新的,那么我们可以在服务消费者端,进行缓存结果,这样读取缓存,速度就很快了。
Histrix之前还可以合并请求,啥意思?也就是在一个很短的时间内,允许将多个请求合并为一个请求去操作。
5、数据库分库
网站的性能和数据库有很大的关系,好的网站,最佳的方式是有好的分表分库,这是数据库优化的基础。试想我说的1亿用户,你把表弄得很大,即便有好的SQL还是相对慢的。
一般来说我们微服务使用的是分库的多,也就是一个表可以分为多个库进行存储,极少考虑分表,因为分表会造成表名的不一致,后期很难维护。比如我1亿的用户,有5个数据库实例,那么每一个理想的就是2000万。对于MySQL不超过5000万的记录数就不需要特别优化。
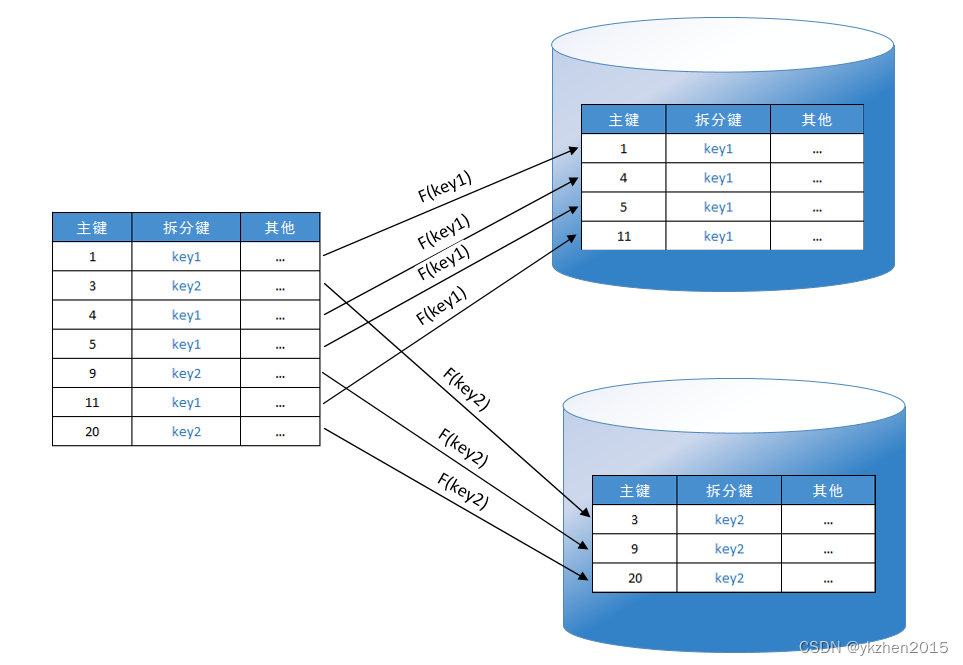
一般来说分库就存在这样的算法:
- 按范围分:比如2020年注册的用户在库1,2021年注册的用户在库2、2022年注册的在库3,2023年注册的在库4。这样会造成不均,注册的巅峰在2022年,而2020年注册很少,这样数据就分摊不均了。
- 哈希算法:典型的求余、一致性哈希算法(具体可以自己研究)、还有一些Java的哈希算法。哈希算法的好处可以是将数据平均摊分到到各个数据库的节点中。比如1亿用户5个库就可能基本每个库是2000万左右。
- 热点算法:如果你认为将数据平均分配给各个库就OK了,那么你又错了。因为经济学告诉我们28原则,1亿的用户,活动的用户可能就是2000万,如果有5个库,但是1600万用户在1个库,其他4个库只分配到400万,就成了1个人干活,4个人在打酱油,而且忙的那个人就可能还会累死。因此将1亿数据平摊,不如将活动用户2000万平摊到各个库中。这个时候,划分独立的Redis存储1亿用户和数据库的关系,永不过期,这样我们可以随时访问Redis拿到用户的数据库信息,然后再访问具体的库。一般来说一年做2到5次热点平摊,你的数据库基本就666了。如何评判为活动用户呢?每个单位都不同,比如一个月会登录3次的,我们可以认为是热点用户,这样就可以将其视为热点。
我以前就玩过热点算法,那个性能是数倍的提升,就是那么任性。因为热点数据是无规则的,只能通过实践的统计分析。自己指定规则去维护,使得热点数据能平摊到数据库中,每个数据库都尽可能的干同样的活,那么性能就是666了。
6、优化SQL
你要问我最大的工作在哪里,那么一定是在于优化SQL。SQL在很大程度上决定了RT(响应时间),而响应时间在很大程度上。
对于互联网系统需要减少:
- 统计查询:需要统计查询的应该是规定某个时间节点后才在后台执行统计分析,直接查询统计的结果,而不是临时让客户进行统计查询。
- 涉及大数据量的查询:尽量缩小为单个用户数据的查询,而不是涉及大量数据的查询。如果单个用户数据还是比较多的,可以考虑分页。
6.1、依靠索引。
尤其是主键一定要用好。因为数据大部分是根据用户走的,因此我们尽可能的是建立user_id这个索引,然后使用用户编号这个索引来缩小范围。
select col1, col2, col3 ......from t_table where user_id = xxx
对于索引要有这样几个意识:
- 优先考虑主键索引
- 索引具备大的区分度,使用它之后需要能够快速的锁定到少量数据的为佳。
- 复合索引最好一个表只有1到2个不能太多。
- 索引不应该超过6个,因为维护增删改数据,都需要维护索引。造成空间浪费,还有性能下降。
- 数据不是很大的表不需要建设索引。
使用索引,假设现在存在A和B两个索引作为条件,那么如何使用这两个索引呢?
如果A的区分度,可以将数据条数缩小到万级,而B区分度可以缩小到千级别,那么SQL索引条件就是:
where B=y and A=x
这是因为在SQL语句里,先出现的索引会优先被数据库使用,的B索引的区分度大,能极大缩小范围,这样速度就快。
6.2、查询条件注意应用到索引
假设字段A是索引字段,对于查询条件,一般不要写表达式,比如:
where A/3=2
这样的写法就无法使用索引,修改为就可以使用索引了。
where A=2*3
模糊查询:
where A like '%张%'
这样无法使用索引,一般来说,对于这样的可以考虑建立全文索引。
6.3、子查询修改为连接查询
很多查询有些人写不好,比如下面这条:
select col1, col2, col3, ... from A where x in (select id from B where y=1)
这样是子查询,我们可以写为:
select A.col1, A.col2, A.col3, ... from A , B where A.x=B.id and B.y=1
子查询不如连接查询快。
还有外连接,比如需要找到A表有,B表没有的数据。
select A.* from A where x not in (select y from B)
这又是一条糟糕的语句,我们可以进行优化为:
select A.* from A left join B on A.x = B.y where B.y is null
对于关联查询,我们的一个原则是,小表驱动大表。因为小表需要轮询少,大表需要轮询多。
所以:
- 内连接和左连接:左表是小表。
- 右连接:右表是小表。
6.4、注意锁的应用
假设存在A是主键索引,而B是普通的索引,于是很多人这样写更新SQL。
update t_table set col1 = 1 where B = 1
这条语句很清楚,也走索引,但是极其容易产生问题。
因为这条语句是更新语句,在没有出现主索引的时候,MySQL会锁定整张表,而不是需要更新的行。
一旦锁表,就会造成各类阻塞,于是不断报错,系统就崩了。我们可以修改为:
update t_table set col1 = 1 where id in (select id from t_table where B = 1)
上面这条使用主键更新,这样MySQL只会给行锁,不会锁住整个表,这样就能维持其他线程的并发了。
7、Redis用好
Redis是用于查询的,因为我们的大部分的请求都是查询,而查询数据可以不是实时的,可以是脏数据。一般来说你需要考虑超时时间,此时需要注意缓存穿透、缓存击穿、缓存雪崩的坑(搞不清楚概念的自己再去查查)。
对于Redis来说可以搭建集群模式,它可以容纳最多16384个节点,一般够用了。除非你是超大电商,如果还不够用,可以再加层负载均衡,继续扩容节点。这样就能容纳很多的数据。
大部分的数据走缓存,就能够撑住很大的并发,毕竟读比写的频率要快得多,使用缓存就如同银弹一样,能快速的响应用户。
只是Redis一定要考虑回收的策略,它的策略如下:
# volatile-lru -> Evict using approximated LRU, only keys with an expire set.
# allkeys-lru -> Evict any key using approximated LRU.
# volatile-lfu -> Evict using approximated LFU, only keys with an expire set.
# allkeys-lfu -> Evict any key using approximated LFU.
# volatile-random -> Remove a random key having an expire set.
# allkeys-random -> Remove a random key, any key.
# volatile-ttl -> Remove the key with the nearest expire time (minor TTL)
# noeviction -> Don't evict anything, just return an error on write operations.默认的情况下,是noeviction,也就是Redis对内存使用到最大内存空间后啥也不做,只是报错。
一般来说的我们是使用“volatile”开头的回收策略为主,因为这些都是超时的键的回收策略。对“allkeys”回收那么可能误删正在使用的键哦。
还要注意Redis的备份方式,主要是两种:快照和AOF(追加文件)。
- 快照就是将当前内存的内容保存下来,这样用快照文件就可以快速恢复了。只是服务器内存一般好几十个G,保存速度很慢,会卡顿。
- 而AOF的方式则是将Redis执行过的写命令保存下来,但是恢复的时候就要一条条执行命令了。这样恢复的速度就远远没有快照方式快。
8、数据预热
因为在运行中,很多时候需要临时创建对象,这对于java、缓存和数据库来说都瞬间消耗大量的资源去创建各类对象。为了更快,需要在高并发来到之前,先预热好,先创建对象,高并非来的时候,这样就能很好的避免临时创建对象的压力了。