我是荔园微风,作为一名在IT界整整25年的老兵,今天我们来看一看微软ChatGPT技术的底层支撑——GPU。
想要了解GPU,你必须要清楚CPU、GPU、TPU三者的关系。
微软的chatgpt是基于复杂的人工神经网络和强化学习的技术,这是如何运算的?在我们对比 CPU、GPU 和 TPU 之前,我们可以先了解到底机器学习或神经网络需要什么样的计算。如下所示,假设我们使用单层神经网络识别手写数字。
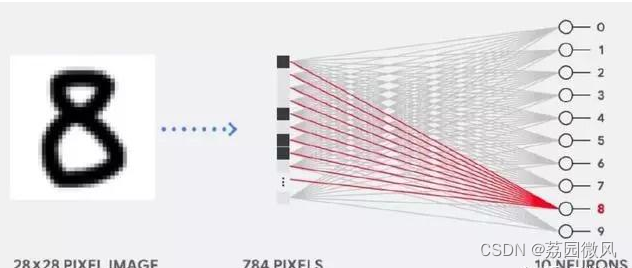
如果图像为 28×28 像素的灰度图,那么它可以转化为包含 784 个元素的向量。神经元会接收所有 784 个值,并将它们与参数值(上图红线)相乘,因此才能识别为「8」。其中参数值的作用类似于用「滤波器」从数据中抽取特征,因而能计算输入图像与「8」之间的相似性:

这是对神经网络做数据分类最基础的解释,即将数据与对应的参数相乘(上图两种颜色的点),并将它们加在一起(上图右侧收集计算结果)。如果我们能得到最高的预测值,那么我们会发现输入数据与对应参数非常匹配,这也就最可能是正确的答案。
简单而言,神经网络在数据和参数之间需要执行大量的乘法和加法。我们通常会将这些乘法与加法组合为矩阵运算,这在我们大学的线性代数中会提到。所以关键点是我们该如何快速执行大型矩阵运算,同时还需要更小的能耗。
CPU 如何运行
因此 CPU 如何来执行这样的大型矩阵运算任务呢?一般 CPU 是基于冯诺依曼架构的通用处理器,这意味着 CPU 与软件和内存的运行方式如下:
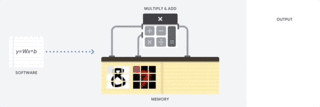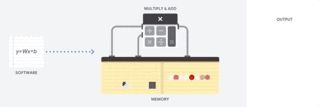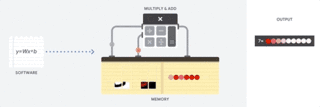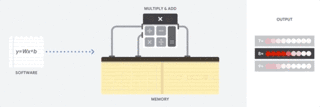
图:CPU 如何运行
CPU 最大的优势是灵活性。通过冯诺依曼架构,我们可以为数百万的不同应用加载任何软件。我们可以使用 CPU 处理文字、控制火箭引擎、执行银行交易或者使用神经网络分类图像。
但是,由于 CPU 非常灵活,硬件无法一直了解下一个计算是什么,直到它读取了软件的下一个指令。CPU 必须在内部将每次计算的结果保存到内存中(也被称为寄存器或 L1 缓存)。内存访问成为 CPU 架构的不足,被称为冯诺依曼瓶颈。
虽然神经网络的大规模运算中的每一步都是完全可预测的,每一个 CPU 的算术逻辑单元(ALU,控制乘法器和加法器的组件)都只能一个接一个地执行它们,每一次都需要访问内存,限制了总体吞吐量,并需要大量的能耗。
GPU 如何工作
为了获得比 CPU 更高的吞吐量,GPU 使用一种简单的策略:在单个处理器中使用成千上万个 ALU。现代 GPU 通常在单个处理器中拥有 2500-5000 个 ALU,意味着你可以同时执行数千次乘法和加法运算。
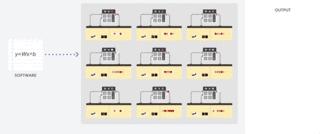
图:GPU 如何工作
这种 GPU 架构在有大量并行化的应用中工作得很好,例如在神经网络中的矩阵乘法。实际上,相比 CPU,GPU 在深度学习的典型训练工作负载中能实现高几个数量级的吞吐量。这正是为什么 GPU 是深度学习中最受欢迎的处理器架构。
但是,GPU 仍然是一种通用的处理器,必须支持几百万种不同的应用和软件。这又把我们带回到了基础的问题,冯诺依曼瓶颈。在每次几千个 ALU 的计算中,GPU 都需要访问寄存器或共享内存来读取和保存中间计算结果。
因为 GPU 在其 ALU 上执行更多的并行计算,它也会成比例地耗费更多的能量来访问内存,同时也因为复杂的线路而增加 GPU 的物理空间占用。
TPU 如何工作
当谷歌设计 TPU 的时候,我们构建了一种领域特定的架构。这意味着,我们没有设计一种通用的处理器,而是专用于神经网络工作负载的矩阵处理器。
TPU 不能运行文本处理软件、控制火箭引擎或执行银行业务,但它们可以为神经网络处理大量的乘法和加法运算,同时 TPU 的速度非常快、能耗非常小且物理空间占用也更小。
其主要助因是对冯诺依曼瓶颈的大幅度简化。因为该处理器的主要任务是矩阵处理,TPU 的硬件设计者知道该运算过程的每个步骤。因此他们放置了成千上万的乘法器和加法器并将它们直接连接起来,以构建那些运算符的物理矩阵。
这被称作脉动阵列(Systolic Array)架构。在 Cloud TPU v2 的例子中,有两个 128X128 的脉动阵列,在单个处理器中集成了 32768 个 ALU 的 16 位浮点值。
我们来看看一个脉动阵列如何执行神经网络计算。首先,TPU 从内存加载参数到乘法器和加法器的矩阵中。

图:TPU 如何工作
然后,TPU 从内存加载数据。当每个乘法被执行后,其结果将被传递到下一个乘法器,同时执行加法。因此结果将是所有数据和参数乘积的和。在大量计算和数据传递的整个过程中,不需要执行任何的内存访问。
这就是为什么 TPU 可以在神经网络运算上达到高计算吞吐量,同时能耗和物理空间都很小。
因此使用 TPU 架构的好处就是:成本降低至 1/5。
刚开始接触深度学习概念时,基本大多数时候也就提到GPU,也基本是用GPU来进行深度学习算法训练或部署人脸识别系统的。
近几年,随着人工智能(尤其是人脸识别)的爆炸式发展,诞生了许多新的东西,其中这芯片,就让很多人都摸不着头脑。
除了CPU,GPU之外,还有TPU,NPU等,真的是CPU/GPU/TPU/NPU傻傻分不清楚啊。
今天,闻西就来帮大家理理这些让人分不清楚的芯片到底都是啥?怎么区别它们?
CPU
CPU是大家听到得最多的。
CPU英文全称是Central Processing Unit,中文全称是中央处理器,是计算机的核心器件,CPU通常由三个部分组成:计算单元、控制单元和存储单元。
架构图如下:
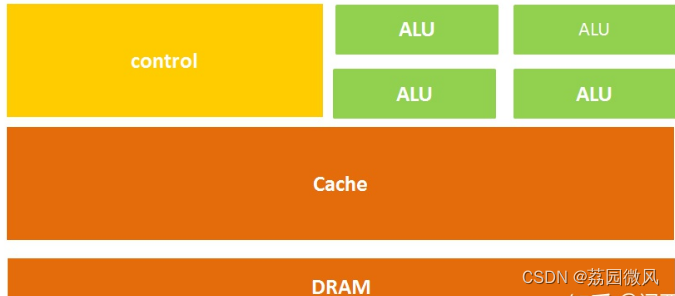
GPU
GPU全称是Graphics Processing Unit,中文全称叫图形处理器,它也是由三个部分组成:计算单元、控制单元和存储单元。
我们继续沿用上面CPU架构图用来表示各个单元的颜色来表示下GPU架构(黄色用来表示控制单元,绿色用来表示计算单元,橙色用来表示存储单元),如下:

这妥妥是个CPU变种啊!
我们把CPU和GPU的架构图放在一起比较下,看看有啥区别:
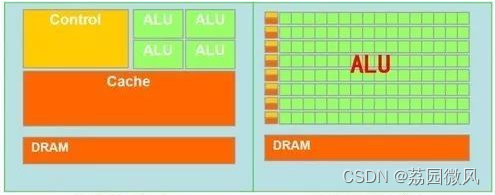
CPU这边起码30%都是用在了控制单元,各个单元占比还算均衡,而GPU就夸张了,80%以上都用在了计算单元,偏科有点严重啊。
正是由于这种区别,导致CPU精于控制和复杂运算,而GPU精于简单且重复的运算。
另外CPU和GPU还有一个最大的区别:CPU是顺序执行运算,而GPU是可以大量并发的执行运算,通俗的说就是CPU做事情是一件一件来做,而GPU是很多件事情同时做。
但很多件事情同时做,一定是简单的事情,就像一个人一样,我们没法同时做两件复杂的事情。
借用别人的说法,就像你有个工作需要计算几亿次一百以内加减乘除一样,最好的办法就是雇上几十个学生一起算,一人算一部分,反正这些计算也没什么技术含量;而CPU就像教授,积分微分都会算,就是工资高,一个教授资顶二十个学生。
GPU就是用很多简单的计算单元去完成大量的计算任务,纯粹的人海战术。这种策略基于一个前提,就是学生A和学生B的工作没有什么依赖性,是互相独立的。
虽然GPU是为了图像处理而生的,但是我们通过前面的介绍可以发现,它在结构上并没有专门为图像服务的部件,只是对CPU的结构进行了优化与调整,所以现在GPU不仅可以在图像处理领域大显身手,它还被用来科学计算、密码破解、数值分析,海量数据处理(排序,Map-Reduce等),金融分析等需要大规模并行计算的领域。
上面我们提到的CPU和GPU都是通用芯片。
一块石头,是通用的,但如果我专门打磨打磨,让它变成锋利的,是不是就可以用来切割东西了呢?
有了这个概念后,对于TPU,NPU等等众多的PU们,你把它们当成都是专门打磨过的石头,就很好理解了。
TPU
自从谷歌的AlphaGo打败李世石之后,谷歌在人工智能界的知名度也越来越大了,于是谷歌推出了它们的深度学习框架TensorFlow,这个深度学习框架也就此扬名世界。
有了好的算法框架,就得要有硬件来支持啊,传统的GPU行吗?
当然行,可是它毕竟是块通用的石头,要是打磨打磨就好了。
于是针对谷歌的深度学习框架TensorFlow专门定制的芯片诞生了,英文全称就叫Tensor Processing Unit,翻译为中文就是张量处理单元,它到底有多牛呢?比较下你就知道了:
TPU与同期的CPU和GPU相比,可以提供15-30倍的性能提升,以及30-80倍的效率(性能/瓦特)提升。
NPU
NPU英文全称是Neural network Processing Unit, 中文叫神经网络处理器。
神经网络就是你大脑里面的神经元连接成的网络,错综复杂,据说越复杂越聪明,当然太复杂了,就成神经病了。
而这个NPU,即神经网络处理器,就是要模仿人的大脑神经网络,使之具备智能。
怎么模仿呢?
NPU工作原理是在电路层模拟人类神经元和突触,并且用深度学习指令集直接处理大规模的神经元和突触,一条指令完成一组神经元的处理。相比于CPU和GPU,NPU通过突触权重实现存储和计算一体化,从而提高运行效率。
其他PU们
APU — Accelerated Processing Unit, 加速处理器,AMD公司推出加速图像处理芯片产品。
BPU — Brain Processing Unit, 地平线公司主导的嵌入式处理器架构。
CPU — Central Processing Unit 中央处理器, 目前PC core的主流产品。
DPU — Deep learning Processing Unit, 深度学习处理器,最早由国内深鉴科技提出;另说有Dataflow Processing Unit 数据流处理器, Wave Computing 公司提出的AI架构;Data storage Processing Unit,深圳大普微的智能固态硬盘处理器。
FPU — Floating Processing Unit 浮点计算单元,通用处理器中的浮点运算模块。
GPU — Graphics Processing Unit, 图形处理器,采用多线程SIMD架构,为图形处理而生。
HPU — Holographics Processing Unit 全息图像处理器, 微软出品的全息计算芯片与设备。
IPU — Intelligence Processing Unit, Deep Mind投资的Graphcore公司出品的AI处理器产品。
MPU/MCU — Microprocessor/Micro controller Unit, 微处理器/微控制器,一般用于低计算应用的RISC计算机体系架构产品,如ARM-M系列处理器。
NPU — Neural Network Processing Unit,神经网络处理器,是基于神经网络算法与加速的新型处理器总称,如中科院计算所/寒武纪公司出品的diannao系列。
RPU — Radio Processing Unit, 无线电处理器, Imagination Technologies 公司推出的集合集Wifi/蓝牙/FM/处理器为单片的处理器。
TPU — Tensor Processing Unit 张量处理器, Google 公司推出的加速人工智能算法的专用处理器。目前一代TPU面向Inference,二代面向训练。
VPU — Vector Processing Unit 矢量处理器,Intel收购的Movidius公司推出的图像处理与人工智能的专用芯片的加速计算核心。
WPU — Wearable Processing Unit, 可穿戴处理器,Ineda Systems公司推出的可穿戴片上系统产品,包含GPU/MIPS CPU等IP。
XPU — 百度与Xilinx公司在2017年Hotchips大会上发布的FPGA智能云加速,含256核。
ZPU — Zylin Processing Unit, 由挪威Zylin 公司推出的一款32位开源处理器。
作者简介:荔园微风,1981年生,高级工程师,浙大工学硕士,软件工程项目主管,做过程序员、软件设计师、系统架构师,早期的Windows程序员,Visual Studio忠实用户,C/C++使用者,是一位在计算机界学习、拼搏、奋斗了25年的老将,经历了UNIX时代、桌面WIN32时代、Web应用时代、云计算时代、手机安卓时代、大数据时代、ICT时代、AI深度学习时代、智能机器时代,我不知道未来还会有什么时代,只记得这一路走来,充满着艰辛与收获,愿同大家一起走下去,充满希望的走下去。