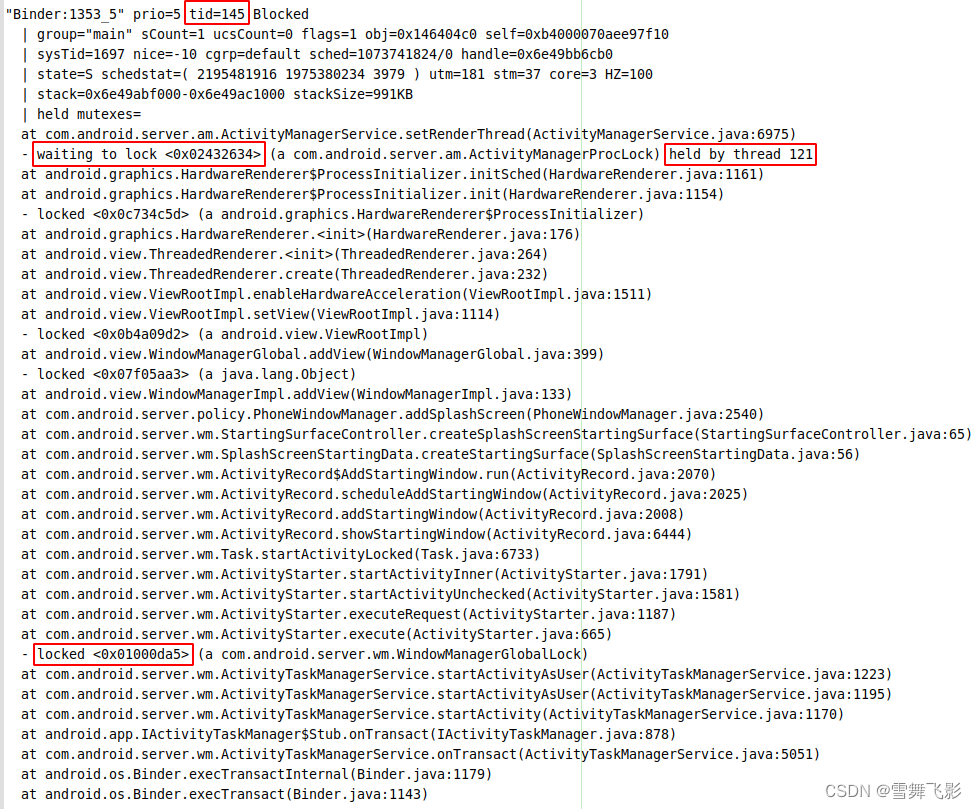
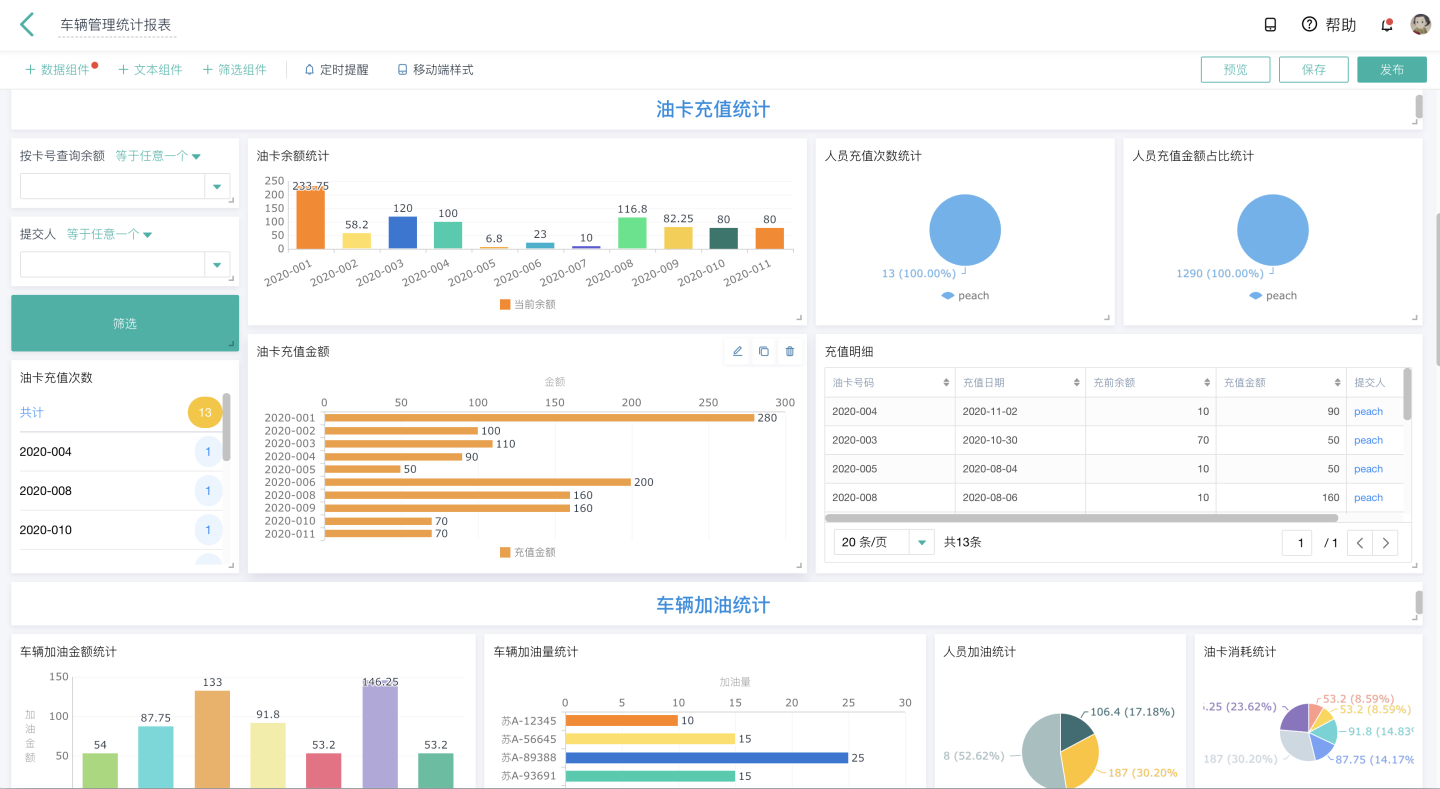
【半监督图像分割 2023 CVPR】UniMatch
论文题目:Revisiting Weak-to-Strong Consistency in Semi-Supervised Semantic Segmentation
中文题目:重新审视半监督语义分割中的强弱一致性
论文链接:https://arxiv.org/abs/2208.09910
论文代码:
论文团队:
发表时间:
DOI:
引用:Yang L, Qi L, Feng L, et al. Revisiting weak-to-strong consistency in semi-supervised semantic segmentation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023: 7236-7246.
引用数:7
摘要
在这项工作中,我们重新讨论了弱到强一致性框架,该框架由FixMatch从半监督分类中推广而来,其中对弱扰动图像的预测作为对其强扰动版本的监督。 有趣的是,当转移到我们的分割场景中时,我们观察到这样一个简单的管道已经获得了与最近的高级作品相比的竞争性结果。 然而,它的成功在很大程度上依赖于手工设计强大的数据增强,这可能是有限的,不足以探索更广阔的扰动空间。 基于此,我们提出了一种辅助特征扰动流作为补充,从而扩展了扰动空间。 另一方面,为了充分探测原始图像级的增强,我们提出了一种双流扰动技术,使两个强视图同时由一个共同的弱视图引导。 因此,我们的整体统一双流扰动方法(Unimatch)在Pascal、Cityscapes和COCO基准上的所有评估协议中大大超过了所有现有的方法。 在遥感图像和医学图像分析中也展示了该方法的优越性。
1. 简介
语义分割的目的是为图像提供像素级的预测,它可以被看作是一个密集的分类任务,是自动驾驶等现实应用的基础。 然而,传统的全监督场景[43,77,73]对人工标注的精细图像极度渴求,极大地阻碍了它在大量图像标注成本高甚至不可行的领域的广泛应用。 因此,半监督语义分割[56]被提出并日益受到关注。 通常,它希望通过利用大量未标记的图像,并伴随少量手动标记的图像来减轻劳动密集型过程。
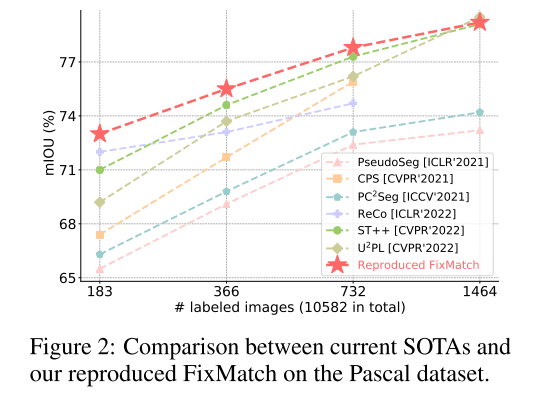
紧跟半监督学习(SSL)的研究路线,半监督语义分割的先进方法已经从基于GANS的对抗性训练范式[21,56,47]演变为广泛采用的一致性正则化框架[19,49,81,12,28,29,62]和新生的自训练管道[70,27,68,23]。 本文重点研究了FixMatch[55]将弱到强一致性正则化框架,并将其推广到半变量分类领域,进而影响到许多相关工作[41,57,66,45,63,67]。 弱到强的方法监督一个强扰动的未标记图像 x s x^s xs,其相应的弱扰动版本 x w x^w xw产生的预测,如图1所示。 直观地看,它的成功之处在于模型更有可能在 x w x^w xw上产生高质量的预测,而 x s x^s xs对我们的模型学习更有效,因为强扰动引入了额外的信息,并减轻了确认偏差[2]。 我们意外地注意到,只要加上适当的强扰动,FixMatch在我们的场景中确实仍然可以显示出强大的泛化能力,获得与最先进(SOTA)方法相比具有竞争力的结果,如图2所示。 因此,我们选择这个简单而有效的框架作为我们的基线。
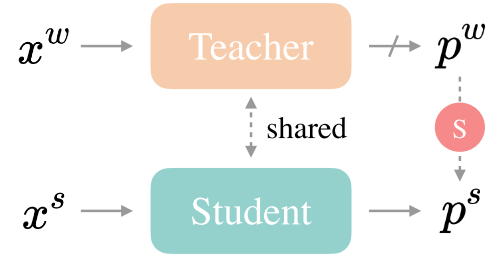
图1:FixMatch。分离的教师在弱扰动的 x w x^w xw上产生伪标签 p w p^w pw来监督(S)其强扰动的 x s x^s xs和相应的预测 p s p^s ps。标记的图像被省略了。
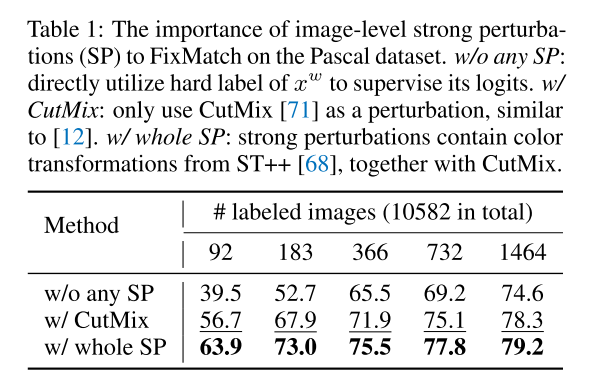
通过对图像级强扰动的研究,我们观察到它们在使FixMatch成为半监督语义分割的有力竞争者方面发挥了不可或缺的作用。 如表1所示,是否采用扰动之间的性能差距极其巨大。 受这些线索的启发,我们希望在继承FixMatch强扰动精神的同时,从两个不同的角度和方向进一步强化它们,即拓展更广阔的扰动空间和充分收获原始扰动。 以下两段分别详述了这两个视角中的每一个视角。
图像级的扰动,例如颜色抖动和cutmix[71],包括启发式偏差,它实际上将额外的先验信息引入到FixMatch的自举范式中,以便捕获一致性正则化的优点。 如果没有这些干扰,FixMatch将退化为一个幼稚的在线自我训练管道,产生更糟糕的结果。 尽管这种扰动是有效的,但这些扰动完全限制在图像层面,阻碍了模型探索更广阔的扰动空间,并在不同层面上保持一致性。 为此,为了扩展原始摄动空间,我们设计了一个统一的原始图像和提取特征的摄动框架。 具体来说,在原始图像上,类似于FixMatch,使用预定义的图像级强扰动,而对于弱扰动图像的特征提取,则插入了一个令人尴尬的简单信道丢失。 这样,我们的模型在图像和嵌入层都追求对未标记图像的预测的等价性。 这两个扰动能级可以相互补充。 与[33,42]不同的是,我们将不同层次的扰动分离成独立的流,以避免单个流过于难以学习。
另一方面,目前的FixMatch框架只是在一个小批次中利用了每个未标记图像的单一强视图,这不足以充分利用手动预设的扰动空间。考虑到这一点,我们提出了一个简单但非常有效的输入改进,即从扰动池中随机抽出双独立的强视图。然后,它们被平行地输入到学生模型中,并同时受到它们共享的弱视图的监督。这样一个小的修改甚至很容易将FixMatch基线本身变成一个SOTA框架。直观地说,我们猜想,强制两个强视图接近一个共同的弱视图,可以被视为最小化这些强视图之间的距离。因此,它与对比学习[11, 25]的精神和优点相同,可以学习更多的辨别性表征,并被证明对我们目前的任务特别有益[40, 62]。我们对每个提议的组件的有效性进行了全面的研究。我们的贡献可以归纳为四个方面:
- 我们注意到,再加上适当的图像级强扰动[71,68],FixMatch在转移到语义分割场景时仍然是一个强大的框架。 在当前任务中,一个简单复制的fixmatch的性能几乎超过了所有现有的方法。
- 在FixMatch的基础上,我们提出了一种统一的摄动方法,将图像级和特征级的摄动统一在独立的流中,以开发更广阔的摄动空间。
- 我们设计了一种双流摄动策略来充分探测预定义的图像级摄动,以及获得识别特征的对比学习的优点。
- 我们集成了上述两种方法的总体框架,称为Unimatch,在Pascal、Cityscapes和Coco上的所有拆分中显著地超越了现有的方法。 在医学图像分析和遥感解译中也得到了验证(附录E)。
2. 相关工作
2.1 半监督学习
半监督学习(SSL)的核心问题在于如何为未标记的数据设计合理有效的监督信号。为了解决这个问题,提出了两个主要的方法分支,即熵最小化[22, 53, 37, 65, 80, 51]和一致性规范化[36, 54, 58, 64, 30, 6, 5, 48, 20, 38]。熵最小化,由自我训练[37]推广,通过给未标记的数据分配伪标签,然后将其与人工标记的数据结合起来进行进一步的再训练,以一种直接的方式工作。另外,一致性正则化有一个假设,即对未标记的例子的预测应该对不同形式的扰动不发生变化。其中,FixMatch[55]提出向未标记的图像注入强扰动,并用弱扰动图像的预测来监督训练过程,以归纳两种方法的优点。最近,FlexMatch[72]和FreeMatch[61]考虑了不同类别的学习状态,然后用类别的阈值过滤低置信度的标签。我们的方法继承了FixMatch,然而,我们研究了一个更具挑战性和劳动密集型的环境。更重要的是,我们证明了图像级强扰动的意义,从而设法扩大原始扰动空间,并充分利用预先定义的扰动的优势。
2.2 半监督的语义分割
早期的工作[47, 56]将GANs[21]作为一种辅助监督,通过区分伪标签和人工标签,对无标签图像进行监督。在SSL快速发展的激励下,最近的方法[49, 18, 32, 46, 81, 79, 78, 1, 75, 40, 42, 34, 74]从一致性正则化和熵最小化的角度努力寻求更简单的训练范式。在这一趋势中,French等人[19]披露了Cutout[16]和CutMix[71]对于一致性正则化在分割中的成功至关重要。AEL[28]然后设计了一个自适应的CutMix和采样策略,以加强对表现不佳的类的学习。受对比学习的启发,Lai等人[35]提出在不同的背景作物下,对共享补丁的预测必须相同。而U2PL[62]将不确定的像素视为可靠的负样本,与相应的正样本进行对比。与共同训练[7, 52]和相互学习[76]的核心精神相似,CPS[12]引入了双独立模型来相互监督。
来自熵最小化研究路线的其他作品利用自我训练管道,以离线方式为未标记的图像分配伪掩码。从这个角度来看,Yuan等人[70]声称对无标签图像的过度扰动对干净的数据分布是灾难性的,因此建议对这些图像进行单独的批量规范化。同时,ST++[68]指出,适当的强数据扰动确实对自我训练有极大帮助。此外,为了解决伪标签中遇到的类偏差问题,He等人[27]将人工标注的数据和伪标注的数据之间的类分布统一起来。而USRN[23]选择聚类平衡的子类分布作为正则化,以缓解预设类的不平衡问题。
在追求优雅和有效性的同时,我们采用了来自FixMatch[55]的由弱到强一致性正则化框架,该框架可以在单个模型的单个阶段进行端到端训练。我们的基线框架可以看作是[19]的改进,或者是对[81]的简化。例如,基于[68]增强了[19]中的图像级强扰动,丢弃了[81]中的标定融合模块。有了这个整洁而有竞争力的基线,我们进一步探索了一个更广阔的扰动空间,并充分利用了原始图像级的扰动。
3. 方法
提供一个相对较小的标记图像集 D l = { ( x i l , y i l ) } \mathcal{D}^{l}=\{(x_i^l,y_i^l)\} Dl={(xil,yil)}和大量的未标记图像 D u = { x i u } {\mathcal{D}}^{u}=\{x_{i}^{u}\} Du={xiu},半监督语义分割的算法旨在用 D l {\mathcal{D}}^{l} Dl中有限的注释量充分探索 D u {\mathcal{D}}^{u} Du。
由于我们的方法是基于FixMatch[55],我们首先简要地回顾其核心思想(§3.1)。
随后,我们详细介绍了两个提议的组成部分,即统一扰动(§3.2),以及双流扰动(§3.3)。
最后,我们对我们的整体统一双流扰动方法(UniMatch)进行了总结(§3.4)。
3.1 前期知识
如前所述,FixMatch利用弱到强的一致性正则化来利用未标记的数据。具体来说,每个未标记的图像
x
u
x^u
xu同时被两个操作者扰动、即弱扰动
A
w
{\mathcal{A}}^{w}
Aw,如剪裁,和强扰动,如颜色抖动。然后,总体目标函数是监督损失
L
s
\mathcal{L}^s
Ls和无监督损失
L
u
\mathcal{L}^u
Lu的组合,即:
L
=
L
s
+
σ
L
u
.
\mathcal{L}=\mathcal{L}^s+\sigma\mathcal{L}^u.
L=Ls+σLu.
通常情况下,监督项
L
u
\mathcal{L}^u
Lu是模型预测和真实标签之间的交叉熵损失。而无监督损失
L
u
\mathcal{L}^u
Lu将强扰动下的样本预测规整为与弱扰动下的预测相同,可以表述为::
L
u
=
1
B
u
∑
1
(
max
(
p
w
)
≥
τ
)
H
(
p
w
,
p
s
)
,
\mathcal{L}^u=\frac{1}{B_u}\sum\mathbb{1}(\max(p^w)\geq\tau)\mathrm{H}(p^w,p^s),
Lu=Bu1∑1(max(pw)≥τ)H(pw,ps),
其中
B
u
B_u
Bu是未标记图像的批量大小,
τ
\tau
τ是一个预定义的置信度阈值,用于滤除噪声标签。
H
(
p
w
,
p
s
)
\mathrm{H}(p^w,p^s)
H(pw,ps)使两个概率分布项之间的熵最小化,产生于:
p
w
=
F
^
(
A
w
(
x
u
)
)
;
p
s
=
F
(
A
s
(
A
w
(
x
u
)
)
)
,
p^w=\hat{F}(\mathcal{A}^w(x^u));p^s=F(\mathcal{A}^s(\mathcal{A}^w(x^u))),
pw=F^(Aw(xu));ps=F(As(Aw(xu))),
其中教师模型
F
^
\hat{F}
F^在弱扰动图像上产生伪标签,而学生
F
F
F利用强扰动图像和获得的伪标签进行模型优化。 在这项工作中,为了简单起见,我们将
F
^
\hat{F}
F^设置为与
F
F
F完全相同,遵循FixMatch。
3.2 统一图像和特征级扰动
除了半监督分类,FixMatch中的方法已经席卷了广泛的研究课题,并取得了蓬勃的成功,如语义分割[19, 81, 28],物体检测[41, 57, 66],无监督领域适应[45],和动作识别[63, 67]。尽管它很受欢迎,但其功效实际上在很大程度上取决于研究人员精心设计的强扰动,其最佳组合和超参数的获得是很耗时的。此外,在某些情况下,如医学图像分析和遥感解释,它可能需要特定领域的知识来找出有前途的。更重要的是,这些扰动完全受制于图像层面,阻碍了学生模型对更多不同的扰动保持多层次的一致性。
为此,为了构建一个更广泛的扰动空间,在FixMatch的基础上,我们建议对弱扰动图像
x
w
x^w
xw的特征注入扰动。我们选择将不同级别的扰动分离成多个独立的前馈流,使学生能够更直接地在每个流中实现目标一致性。形式上,一个分割模型
F
F
F可以分解为一个编码器
g
g
g和一个解码器
h
h
h。除了在FixMatch中获得
p
w
p^w
pw和
p
s
p^s
ps外,我们还通过以下方式从一个辅助特征扰动流中获得
p
f
p
p^{fp}
pfp:
e
w
=
g
(
x
w
)
,
p
f
p
=
h
(
P
(
e
w
)
)
,
\begin{aligned} e^w& =g(x^w), \\ p^{fp}& =h(\mathcal{P}(e^w)), \end{aligned}
ewpfp=g(xw),=h(P(ew)),
其中,
e
w
e^w
ew是提取的
x
w
x^w
xw的特征,
P
\mathcal{P}
P表示特征的扰动,例如,dropout或添加均匀的噪声。
总体而言,如图4A所示,对于每个未标记的小批处理维持三个前馈流,它们是(i)最简单的流: x w → f → p w x^{w}\rightarrow f\rightarrow p^{w} xw→f→pw,(ii)图像级强扰动流: x s → f → p s x^{s}\rightarrow f\rightarrow p^{s} xs→f→ps,以及(iii)我们引入的特征扰动流: x w → g → P → h → p f p . x^{w}\rightarrow g\rightarrow\mathcal{P}\rightarrow h\rightarrow p^{fp}. xw→g→P→h→pfp.。
这样,学生模型就能在图像和特征层次上对统一的扰动保持一致。 为了方便起见,我们将其命名为Uniperb。 无监督损失
L
u
\mathcal{L}^u
Lu表述为:
L
u
=
1
B
u
∑
1
(
max
(
p
w
)
≥
τ
)
(
H
(
p
w
,
p
s
)
+
H
(
p
w
,
p
f
p
)
)
.
\mathcal{L}^u=\frac{1}{B_u}\sum\mathbb{1}(\max(p^w)\geq\tau)\big(\mathrm{H}(p^w,p^s)+\mathrm{H}(p^w,p^{fp})\big).
Lu=Bu1∑1(max(pw)≥τ)(H(pw,ps)+H(pw,pfp)).
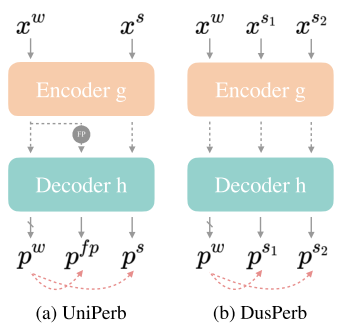
需要注意的是,我们并不是为了提出一种新的特征扰动方法。 实际上,一个非常简单的通道dropout(pytorch中的nn.dropout2d)已经足够好了。 此外,与最近的工作[42]将三个水平的扰动混合成一个单一的流不同,我们强调了将不同性质的扰动分离成独立的流的必要性,这在我们的烧蚀研究中得到了证明。 我们认为,图像级的扰动可以被特征级的扰动很好地补充。
3.3 双流扰动
由于图像级强扰动的巨大优势,我们希望对其进行充分的探索。 我们受到自监督学习和半监督分类最近进展的启发,即为未标记数据构造多个视图作为输入可以更好地利用扰动。 例如,SWAV[8]提出了一种叫做多重作物的新技术,在不同分辨率的视图包中加强局部到全局的一致性。 同样,Remixmatch[5]产生了多个强大的增强版本供模型学习。
因此,我们想知道这样一个简单的想法是否也能有利于我们的半监督语义分割。与ReMixMatch类似,我们做了一个直接的尝试,即不是将单一的 p s p^s ps送入模型,而是通过强扰动池 A s {\mathcal{A}}^{s} As从 x w x^w xw独立产生双流扰动 ( x s 1 , x s 2 ) (x^{s_1},x^{s_2}) (xs1,xs2)。由于 A s {\mathcal{A}}^{s} As是预先确定的,但不是决定性的,所以 x s 1 x^{s_1} xs1和 x s 2 x^{s_2} xs2是不相等的。我们的双流扰动框架,简单表示为DusPerb,显示在图4b中。
耐人寻味的是,在我们的分割方案中,在所有的分割协议下,这样的小修改带来了与原始FixMatch的一致和实质性的改进,建立了新的最先进的结果。在我们的消融研究中验证了这一点,性能的提高是非同小可的,而不是归功于加倍的未标记的批量大小。我们猜想,用一个共享的弱视图来规范两个强视图,也可以看作是在这两个强视图之间强制执行一致性。直观地说,假设kw是xw预测的类别的分类器权重,
(
q
s
1
,
q
s
2
)
(q_{s_{1}},q_{s_{2}})
(qs1,qs2)是图像
(
x
s
1
,
x
s
2
)
(x^{s_1},x^{s_2})
(xs1,xs2)的特征,那么在我们采用的交叉熵损失中,我们最大化
q
j
⋅
k
w
q_{j}\cdot k_{w}
qj⋅kw对
∑
i
=
0
C
q
j
⋅
k
i
\sum_{i=0}^{C}q_{j}\cdot k_{i}
∑i=0Cqj⋅ki,其中
j
∈
{
s
1
,
s
2
}
j\in\{s_{1},s_{2}\}
j∈{s1,s2},
k
i
k_i
ki是类别
i
i
i的分类器权重。因此可以认为,我们也在最大化
q
s
1
q_{s_{1}}
qs1和
q
s
2
q_{s_{2}}
qs2的相似度。因此,InfoNCE损失[59]得到满足
L
s
1
↔
s
2
=
−
log
exp
(
q
s
1
⋅
q
s
2
)
∑
i
=
0
C
exp
(
q
j
⋅
k
i
)
,
s
.
t
.
,
j
∈
{
s
1
,
s
2
}
,
\mathcal{L}_{s_1\leftrightarrow s_2}=-\log\frac{\exp(q_{s_1}\cdot q_{s_2})}{\sum_{i=0}^C\exp(q_j\cdot k_i)},s.t.,j\in\{s_1,s_2\},
Ls1↔s2=−log∑i=0Cexp(qj⋅ki)exp(qs1⋅qs2),s.t.,j∈{s1,s2},
其中
q
s
1
q_{s_1}
qs1和
q
s
2
q_{s_2}
qs2为正对,除
k
w
k_w
kw外,其余分类器权重均为负样本。因此,它具有对比学习的精神[11,25,13],能够学习更多的区别表征,并已被证明对当前任务非常有意义[40,62]。
3.4 我们的整体框架:统一双流扰动(UniMatch)
总而言之,我们提出了两种利用无标签图像的关键技术,即UniPerb和DusPerb。我们的整体框架(被称为UniMatch)整合了这两种方法,如图3所示。算法1中提供了相应的伪代码。与FixMatch相比,我们保留了两个辅助前馈流,一个用于对
x
w
x^w
xw的特征进行扰动,另一个用于对
(
x
s
1
,
x
s
2
)
(x^{s_{1}},x^{s_{2}})
(xs1,xs2)的多视图学习。最后的无监督项的计算方法是:
L
u
=
1
B
u
∑
1
(
m
a
x
(
p
w
)
≥
τ
)
(
λ
H
(
p
w
,
p
f
p
)
+
μ
2
(
H
(
p
w
,
p
s
1
)
+
H
(
p
w
,
p
s
2
)
)
)
.
\mathcal{L}^{u}=\frac{1}{B_{u}}\sum\mathbf{1}(\mathrm{max}(p^{w})\geq\tau)\big(\lambda\mathrm{H}(p^{w},p^{fp})+\frac{\mu}{2}(\mathrm{H}(p^{w},p^{s_{1}})+\mathrm{H}(p^{w},p^{s_{2}}))\big).
Lu=Bu1∑1(max(pw)≥τ)(λH(pw,pfp)+2μ(H(pw,ps1)+H(pw,ps2))).
明确了特征扰动流和图像级扰动流有各自的特性和优势,因此它们的损失权重
λ
λ
λ和
μ
μ
μ同样设置为0.5。
L
u
\mathcal{L}^{u}
Lu的权重项
σ
\sigma
σ设为1,与
L
s
\mathcal{L}^{s}
Ls相同。
L
u
\mathcal{L}^{u}
Lu中的目标函数
H
H
H是一个常规的交叉熵损失。按照FixMatch,在我们所有的实验中,置信度阈值
τ
τ
τ被设定为0.95。
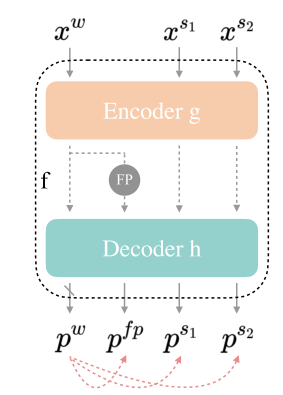
图3:我们提出的统一的双流扰动方法(UniMatch)。FP表示特征扰动,虚线表示监督。