pytorch实现图像分类器
- 一、定义LeNet网络模型
- 1,卷积 Conv2d
- 2,池化 MaxPool2d
- 3,Tensor的展平:view()
- 4,全连接 Linear
- 5,代码:定义 LeNet 网络模型
- 二、训练并保存网络参数
- 1,数据预处理
- 2,数据集
- 3,代码
- 三、图像分类测试
一、定义LeNet网络模型
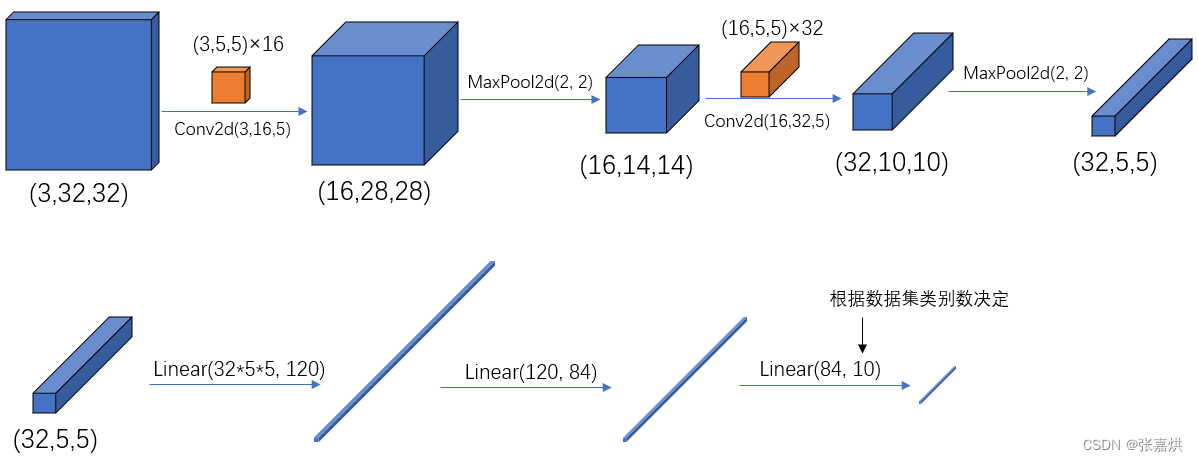
pytorch 中的卷积、池化、输入输出层中参数的含义与位置,可参考下图:
1,卷积 Conv2d
常用的卷积(Conv2d)在pytorch中对应的函数是
# in_channels:输入特征矩阵的深度。如输入一张RGB彩色图像,那in_channels=3
# out_channels:输入特征矩阵的深度。也等于卷积核的个数,使用n个卷积核输出的特征矩阵深度就是n
# kernel_size:卷积核的尺寸。可以是int类型,如3 代表卷积核的height=width=3,也可以是tuple类型如(3, 5)代表卷积核的height=3,width=5
# stride:卷积核的步长。默认为1,和kernel_size一样输入可以是int型,也可以是tuple类型
# padding:补零操作,默认为0。可以为int型如1即补一圈0,如果输入为tuple型如(2, 1) 代表在上下补2行,左右补1列。
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros')
经卷积后的输出层尺寸计算公式为:
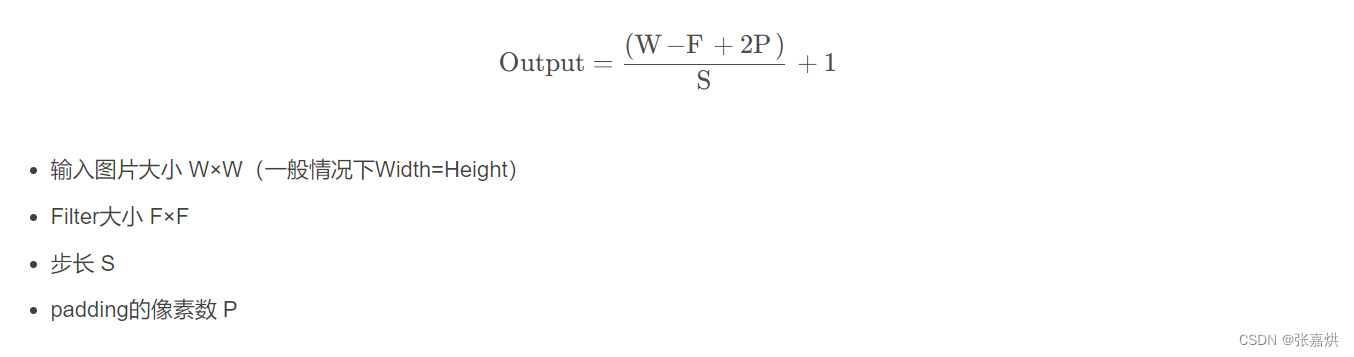
例如:当定义 Conv2d(3, 16, 5) 和 input(3, 32, 32),步长 S 为 1,P 为0时,此时卷积核尺度 F 为5,W 为32,计算得到 output(16, 28, 28)
2,池化 MaxPool2d
最大池化(MaxPool2d)在 pytorch 中对应的函数是:
MaxPool2d(kernel_size, stride)
3,Tensor的展平:view()
注意到,在经过第二个池化层后,数据还是一个三维的Tensor (32, 5, 5),需要先经过展平后(3255)再传到全连接层:
x = self.pool2(x) # 第二个池化层 output(32, 5, 5)
x = x.view(-1, 32*5*5) # 展平 output(32*5*5)
x = F.relu(self.fc1(x)) # 传到全连接层 output(120)
4,全连接 Linear
全连接(Linear)在 pytorch 中对应的函数是:
Linear(in_features, out_features, bias=True)
5,代码:定义 LeNet 网络模型
model.py
# 定义LeNet网络模型
import torch.nn as nn
import torch.nn.functional as F
class LeNet(nn.Module): # 继承于nn.Module这个父类
def __init__(self): # 初始化网络结构
super(LeNet, self).__init__() # 多继承需用到super函数
self.conv1 = nn.Conv2d(3, 16, 5)
self.pool1 = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(16, 32, 5)
self.pool2 = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(32*5*5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x): # 正向传播过程
x = F.relu(self.conv1(x)) # input(3, 32, 32) output(16, 28, 28)
x = self.pool1(x) # output(16, 14, 14)
x = F.relu(self.conv2(x)) # output(32, 10, 10)
x = self.pool2(x) # output(32, 5, 5)
x = x.view(-1, 32*5*5) # output(32*5*5)
x = F.relu(self.fc1(x)) # output(120)
x = F.relu(self.fc2(x)) # output(84)
x = self.fc3(x) # output(10)
return x
二、训练并保存网络参数
1,数据预处理
ToTensor:把输入的图像数据为 shape (H x W x C) in the range [0, 255] 转化为 shape (C x H x W) in the range [0.0, 1.0],同时将 image 和 numpy 输入格式转化为 tensor
Normalize:标准化
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
2,数据集
用的是CIFAR10数据集,是 pytorch 自带的一个很经典的图像分类数据集,一共包含 10 个类别的 RGB 彩色图片。

注意:第一次运行程序,需要下载数据集到本地,所以第一次运行训练集下载时download=True为True,下载完成后改为False。测试集的加载则不用变化。
3,代码
| 名词 | 定义 |
|---|---|
| epoch | 对训练集的全部数据进行一次完整的训练,称为 一次 epoch |
| batch | 由于硬件算力有限,实际训练时将训练集分成多个批次训练,每批数据的大小为 batch_size |
| iteration 或 step | 对一个batch的数据训练的过程称为 一个 iteration 或 step |
# 加载数据集并训练,训练集计算loss,测试集计算accuracy,保存训练好的网络参数
import torch
import torchvision
import torch.nn as nn
from model import LeNet
import torch.optim as optim
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
import time
# 数据预处理
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# 导入、加载训练集
# 导入50000张训练图片
train_set = torchvision.datasets.CIFAR10(root='./data', # 数据集存放目录
train=True, # 表示是数据集中的训练集
download=False, # 第一次运行时为True,下载数据集,下载完成后改为False
transform=transform) # 预处理过程
# 加载训练集,实际过程需要分批次(batch)训练
train_loader = torch.utils.data.DataLoader(train_set, # 导入的训练集
batch_size=50, # 每批训练的样本数
shuffle=False, # 是否打乱训练集
num_workers=0) # 使用线程数,在windows下设置为0
# 导入测试集
# 导入10000张测试图片
test_set = torchvision.datasets.CIFAR10(root='./data',
train=False, # 表示是数据集中的测试集
download=False,transform=transform)
# 加载测试集
test_loader = torch.utils.data.DataLoader(test_set,
batch_size=10000, # 每批用于验证的样本数
shuffle=False, num_workers=0)
# 获取测试集中的图像和标签,用于accuracy计算
test_data_iter = iter(test_loader)
test_image, test_label = test_data_iter.next()
#训练过程
net = LeNet() # 定义训练的网络模型
loss_function = nn.CrossEntropyLoss() # 定义损失函数为交叉熵损失函数
optimizer = optim.Adam(net.parameters(), lr=0.001) # 定义优化器(训练参数,学习率)
for epoch in range(5): # 一个epoch即对整个训练集进行一次训练
running_loss = 0.0 # 累加过程中的损失
time_start = time.perf_counter()
for step, data in enumerate(train_loader, start=0): # enumerate遍历训练集,可以同时返回 data 和 步数,step从0开始计算
inputs, labels = data # 获取训练集的图像和标签
optimizer.zero_grad() # 清除历史损失梯度
# forward + backward + optimize
outputs = net(inputs) # 正向传播
loss = loss_function(outputs, labels) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 优化器更新参数
# 打印耗时、损失、准确率等数据
running_loss += loss.item()
if step % 1000 == 999: # print every 1000 mini-batches,每1000步打印一次
with torch.no_grad(): # 在以下步骤中(验证过程中)不用计算每个节点的损失梯度,防止内存占用
outputs = net(test_image) # 测试集传入网络(test_batch_size=10000),output维度为[10000,10]
predict_y = torch.max(outputs, dim=1)[1] # 以output中值最大位置对应的索引(标签)作为预测输出
accuracy = (predict_y == test_label).sum().item() / test_label.size(0)
print('[%d, %5d] train_loss: %.3f test_accuracy: %.3f' % # 打印epoch,step,loss,accuracy
(epoch + 1, step + 1, running_loss / 500, accuracy))
print('%f s' % (time.perf_counter() - time_start)) # 打印耗时
running_loss = 0.0
print('Finished Training')
# 保存训练得到的参数
save_path = './Lenet.pth'
torch.save(net.state_dict(), save_path)
三、图像分类测试
使用训练并保存好的网络参数,从数据集外找一张图像进行分类测试
# 导入包
import torch
import torchvision.transforms as transforms
from PIL import Image
from model import LeNet
# 数据预处理
transform = transforms.Compose(
[transforms.Resize((32, 32)), # 首先需resize成跟训练集图像一样的大小
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]) # 数据标准化
# 导入要测试的图像
im = Image.open('./car.jpg').convert('RGB') # 若图像为4通道,则用 convert('RGB') 转化为3通道,否则 transform 会报错
im = transform(im) # [C, H, W]
im = torch.unsqueeze(im, dim=0) # 对数据增加一个新维度,因为tensor的参数是[batch, channel, height, width]
# 实例化网络,加载训练好的模型参数
net = LeNet()
net.load_state_dict(torch.load('Lenet.pth'))
# 预测
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
with torch.no_grad():
outputs = net(im)
predict = torch.max(outputs, dim=1)[1].data.numpy() # 找出最大概率的下标
predicts = torch.softmax(outputs , dim=1) # 所有分类的预测概率
print(classes[int(predict)])
print(predicts)