LaWGPT:你的私人法律顾问!

LaWGPT 是一系列基于中文法律知识的开源大语言模型。
该系列模型在通用中文基座模型(如 Chinese-LLaMA、ChatGLM 等)的基础上扩充法律领域专有词表、大规模中文法律语料预训练,增强了大模型在法律领域的基础语义理解能力。在此基础上,构造法律领域对话问答数据集、中国司法考试数据集进行指令精调,提升了模型对法律内容的理解和执行能力。
又双叒叕裁员,互联网裁员几时休?被裁员了如何赔偿?
我们可以用LaWGPT来了解相关的法律法规,维护自身的合法权益!
快速开始
- 准备代码,创建环境
# 下载代码
git clone git@github.com:pengxiao-song/LaWGPT.git
cd LaWGPT
# 创建环境
conda create -n lawgpt python=3.10 -y
conda activate lawgpt
pip install -r requirements.txt
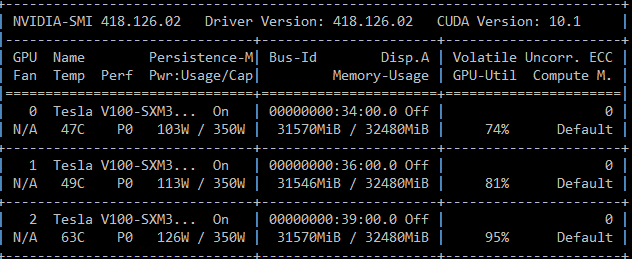
# 启动可视化脚本(自动下载预训练模型约15GB)
bash ./scripts/webui.sh
- 访问 http://127.0.0.1:7860 :
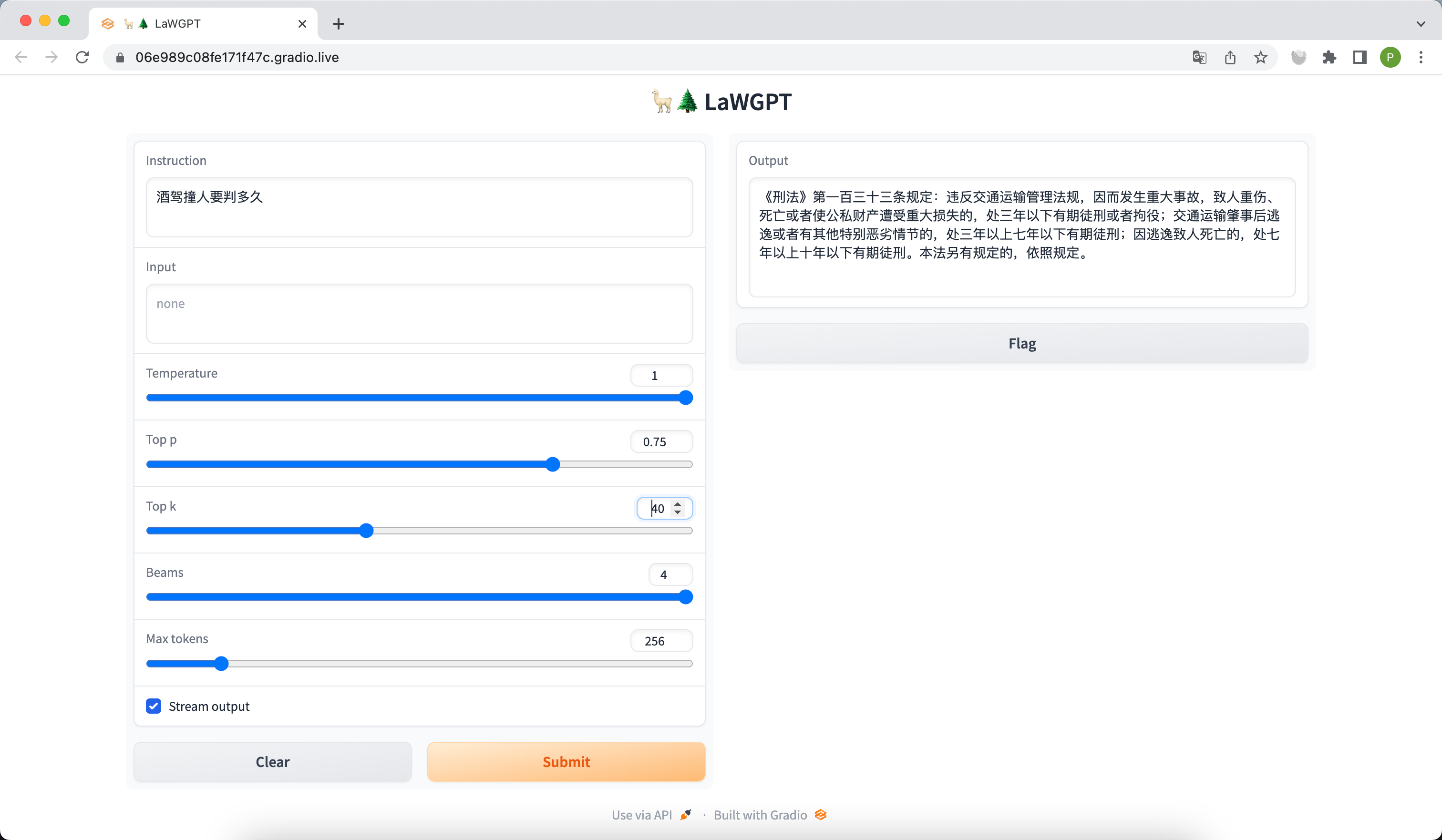
-
合并模型权重(可选)
如果您想使用 LaWGPT-7B-alpha 模型,可跳过改步,直接进入步骤3.
如果您想使用 LaWGPT-7B-beta1.0 模型:
由于 LLaMA 和 Chinese-LLaMA 均未开源模型权重。根据相应开源许可,本项目只能发布 LoRA 权重,无法发布完整的模型权重,请各位谅解。
本项目给出合并方式,请各位获取原版权重后自行重构模型。
项目结构
LaWGPT
├── assets # 静态资源
├── resources # 项目资源
├── models # 基座模型及 lora 权重
│ ├── base_models
│ └── lora_weights
├── outputs # 指令微调的输出权重
├── data # 实验数据
├── scripts # 脚本目录
│ ├── finetune.sh # 指令微调脚本
│ └── webui.sh # 启动服务脚本
├── templates # prompt 模板
├── tools # 工具包
├── utils
├── train_clm.py # 二次训练
├── finetune.py # 指令微调
├── webui.py # 启动服务
├── README.md
└── requirements.txt
数据构建
本项目基于中文裁判文书网公开法律文书数据、司法考试数据等数据集展开,详情参考中文法律数据汇总
模型评估
输出示例
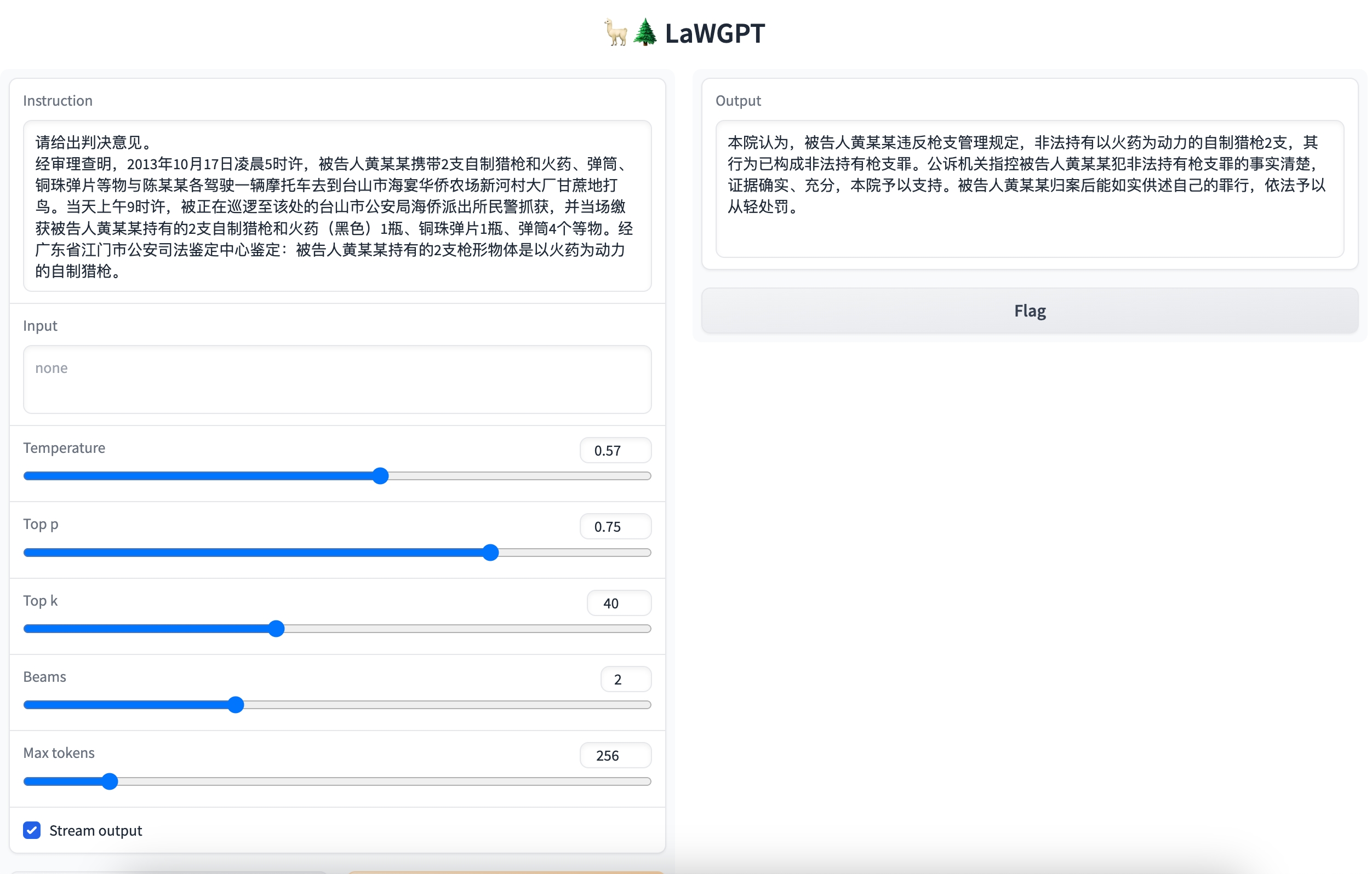
问题:请给出判决意见。
问题:请介绍赌博罪的定义。

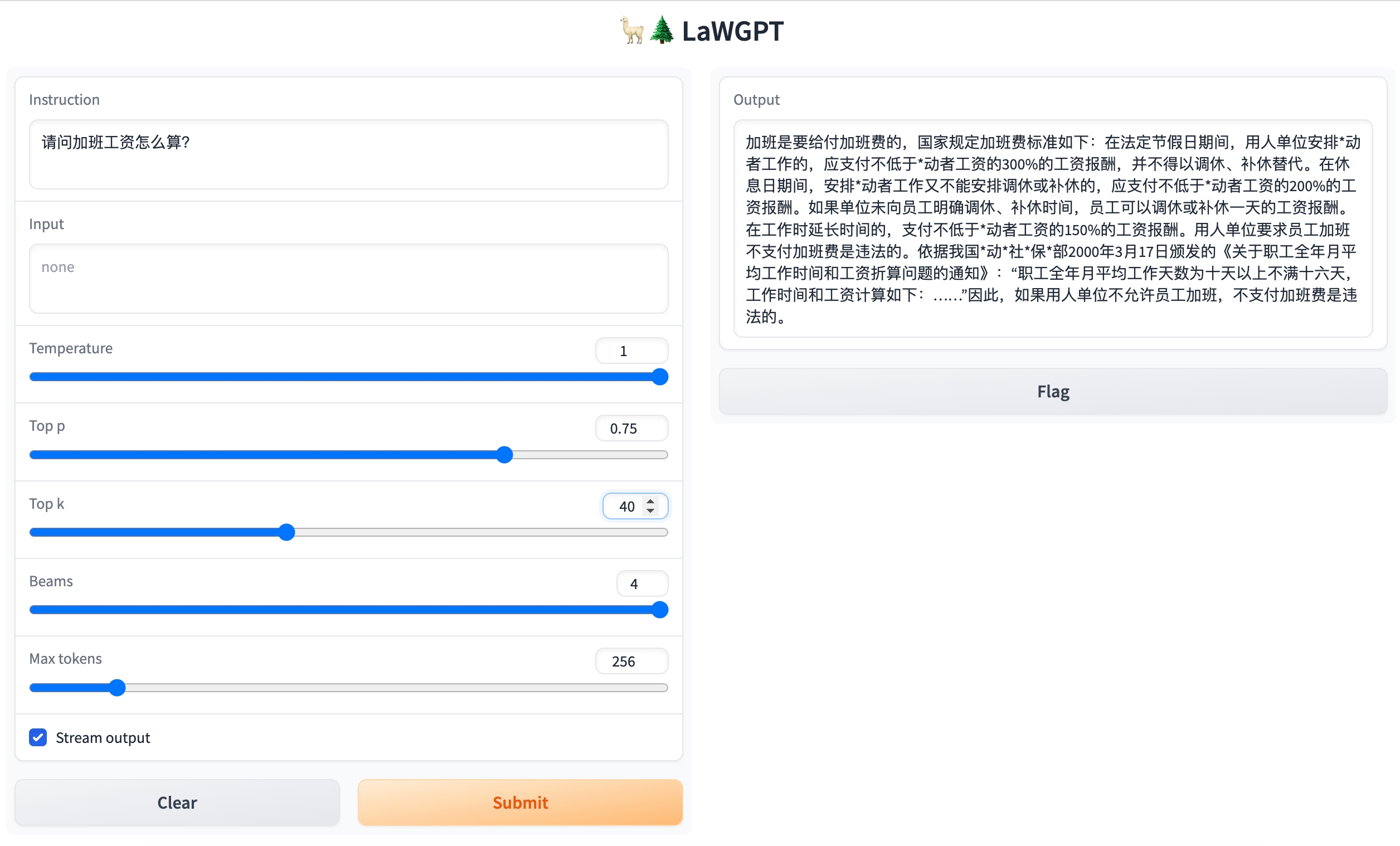
问题:请问加班工资怎么算?
问题:民间借贷受国家保护的合法利息是多少?

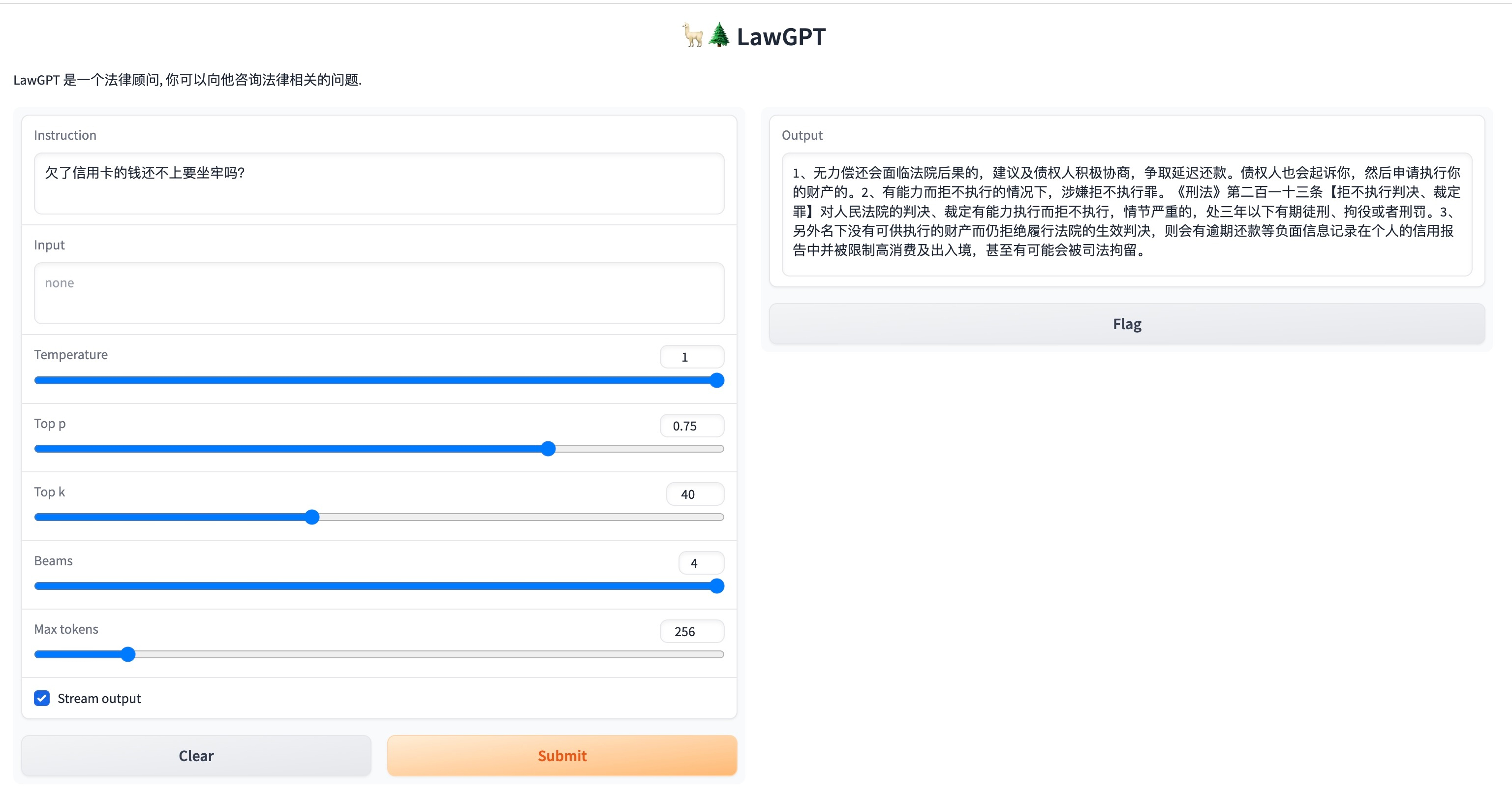
问题:欠了信用卡的钱还不上要坐牢吗?
问题:你能否写一段抢劫罪罪名的案情描述?

局限性
由于计算资源、数据规模等因素限制,当前阶段 LawGPT 存在诸多局限性:
- 数据资源有限、模型容量较小,导致其相对较弱的模型记忆和语言能力。因此,在面对事实性知识任务时,可能会生成不正确的结果。
- 该系列模型只进行了初步的人类意图对齐。因此,可能产生不可预测的有害内容以及不符合人类偏好和价值观的内容。
- 自我认知能力存在问题,中文理解能力有待增强。
请诸君在使用前了解上述问题,以免造成误解和不必要的麻烦。
免责声明
请各位严格遵守如下约定:
- 本项目任何资源仅供学术研究使用,严禁任何商业用途。
- 模型输出受多种不确定性因素影响,本项目当前无法保证其准确性,严禁用于真实法律场景。
- 本项目不承担任何法律责任,亦不对因使用相关资源和输出结果而可能产生的任何损失承担责任。
致谢
本项目基于如下开源项目展开,在此对相关项目和开发人员表示诚挚的感谢:
- Chinese-LLaMA-Alpaca: https://github.com/ymcui/Chinese-LLaMA-Alpaca
- LLaMA: https://github.com/facebookresearch/llama
- Alpaca: https://github.com/tatsu-lab/stanford_alpaca
- alpaca-lora: https://github.com/tloen/alpaca-lora
- ChatGLM-6B: https://github.com/THUDM/ChatGLM-6B
此外,本项目基于开放数据资源,详见 Awesome Chinese Legal Resources,一并表示感谢。