JDK8-2-流(3)- 流操作-distinct
去重操作,如下开头两个菜品一样,对 menu 去重如下:
public class DishDistinctTest1 {
public static final List<Dish> menu = Arrays.asList(
new Dish("pork", false, 800, Dish.Type.MEAT),
new Dish("pork", false, 800, Dish.Type.MEAT),
new Dish("beef", false, 700, Dish.Type.MEAT),
new Dish("chicken", false, 400, Dish.Type.MEAT),
new Dish("french fries", true, 530, Dish.Type.OTHER),
new Dish("rice", true, 350, Dish.Type.OTHER),
//季节水果
new Dish("season fruit", true, 120, Dish.Type.OTHER),
new Dish("pizza", true, 550, Dish.Type.OTHER),
//虾
new Dish("prawns", false, 300, Dish.Type.FISH),
//鲑鱼,三文鱼,
new Dish("salmon", false, 450, Dish.Type.FISH));
public static void distinctTest() {
List<Dish> dishList = menu.stream()
.distinct()
.collect(Collectors.toList());
System.out.println(dishList);
}
public static void main(String[] args) {
distinctTest();
}
}
注意: 对象去重需要重写 equals 和 hashCode 方法(默认对象 equals 方法比较的是对象内存地址是否一致),由 distinct 内部具体实现类 java.util.stream.DistinctOps 可以看出这点。
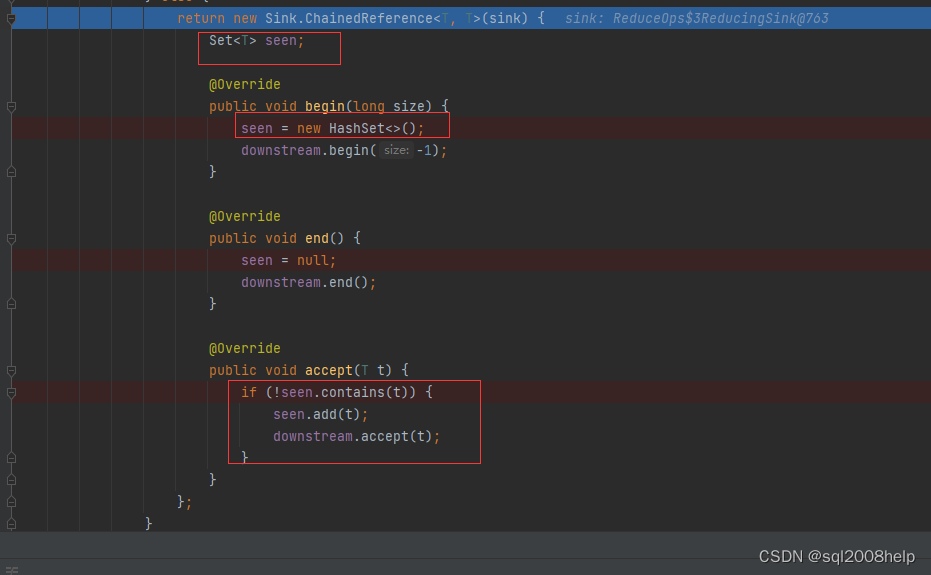
java.util.HashSet
public boolean contains(Object o) {
return map.containsKey(o);
}
java.util.HashMap
public boolean containsKey(Object key) {
return getNode(hash(key), key) != null;
}

IDEA 如何自动生成 equals 和 hashCode 方法
空白处右键选择 Generate 或者Alt + Ins 快捷键
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Dish dish = (Dish) o;
return vegetarian == dish.vegetarian && calories == dish.calories && Objects.equals(name, dish.name) && type == dish.type;
}
@Override
public int hashCode() {
return Objects.hash(name, vegetarian, calories, type);
}
使用 filter 方法去重
假设现在需求有变,菜品 Dish 只要名称、是否素食、类型一致即可判断为重复,最直接的方法就是改动 Dish 类中 equals 和 hashCode 方法实现,但是这样会改变原有的规则,导致原来的代码有问题,而且假设还有其他去重的逻辑,那也无法同时满足。
如何实现
① 定义一个 String 类型 的 Set
② 将 Dish 中 name、vegetarian、type 属性拼接成字符串加入到 set 中,利用 Set 集合中无法添加重复元素的特性过滤掉没有成功添加的元素
代码如下:
public class DishDistinctTest2 {
public static final List<Dish> REPEATED_DISHES = Arrays.asList(
new Dish("pork", false, 790, Dish.Type.MEAT),
new Dish("pork", false, 800, Dish.Type.MEAT),
new Dish("beef", false, 700, Dish.Type.MEAT),
new Dish("beef", false, 690, Dish.Type.MEAT)
);
private static <T> Predicate<T> distinctByKey(Function<? super T, String> keyExtractor) {
Set<String> set = ConcurrentHashMap.newKeySet();
return t -> set.add(keyExtractor.apply(t));
}
public static void distinctTest2() {
List<Dish> dishList = REPEATED_DISHES.stream()
.filter(
distinctByKey(
dish -> String.join("-",
dish.getName(), Boolean.toString(dish.isVegetarian()), dish.getType().toString()
)
)
)
.collect(Collectors.toList());
System.out.println(dishList);
}
public static void main(String[] args) {
distinctTest2();
}
}
打印结果:
[Dish{name='pork', vegetarian=false, calories=790, type=MEAT}, Dish{name='beef', vegetarian=false, calories=700, type=MEAT}]
其中重点代码为 distinctByKey 方法
如果难以理解的话,可以将以上代码用 JDK7 的方式写,如下:
public static void distinctTestWithJDK7() {
List<Dish> dishList = new ArrayList<>();
Set<String> set = ConcurrentHashMap.newKeySet();
for (Dish dish : REPEATED_DISHES) {
String key = String.join("-", dish.getName(), Boolean.toString(dish.isVegetarian()), dish.getType().toString());
if (set.add(key)) {
dishList.add(dish);
}
}
System.out.println(dishList);
}
重复的元素如何保留想要的那一个
① new Dish(“pork”, false, 790, Dish.Type.MEAT),
② new Dish(“pork”, false, 800, Dish.Type.MEAT),
③ new Dish(“beef”, false, 700, Dish.Type.MEAT),
④ new Dish(“beef”, false, 690, Dish.Type.MEAT)
从上面例子的打印结果可以看出保留的是①、③号元素,即两个元素如果重复则保留顺序靠前的,假设现在需求要保留低卡路里的呢
很容易可以想到可以先按照卡路里排序再去重,代码如下:
public static void distinctTest3() {
Comparator<Dish> comparator = Comparator.comparing(Dish::getName).reversed().thenComparing(Dish::getCalories);
List<Dish> dishList = REPEATED_DISHES.stream()
.sorted(comparator)
.filter(distinctByKey(dish -> String.join("-", dish.getName(), Boolean.toString(dish.isVegetarian()), dish.getType().toString())))
.collect(Collectors.toList());
System.out.println(dishList);
}